1、基于Keras、Mnist手写数字识别数据集构建全连接(FC)神经网络训练模型
文章目录
- 前言
- 一、MNIST数据集是什么?
- 二、构建神经网络训练模型
-
- 1.导入库
- 2.载入数据
- 3.数据处理
- 4.创建模型
- 5.编译模型
- 6.训练模型
- 7.评估模型
- 三、总代码
前言
提示:
1、本案例采用Keras,全连接神经网络相关知识实现,请读者自行了解,本文不再详细叙述;
2、本案例使用开源数据集Mnist(手写数字识别数据集),如果无法下载数据集,可尝试使用以下办法:
- 从百度网盘下载数据集文件mnist.npz,保存在本地(假设保存在D:\mydatasets\文件夹下)
百度网盘下载地址:
https://pan.baidu.com/share/init?surl=27CSAC9Ng6wFYdUI0WXIww
提取码:2gsh
以下是本篇文章正文内容,下面案例仅供参考
一、MNIST数据集是什么?
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST)。训练集 (training set) 由来自 250 个不同人手写的数字构成,其中 50% 是高中学生,50% 来自人口普查局 (the Census Bureau) 的工作人员。测试集(test set) 也是同样比例的手写数字数据。
数据集包含60,000个用于训练的示例和10,000个用于测试的示例。MNIST 数据集包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (包含 10,000 个标签)
训练数据集包含 60,000 个样本,测试数据集包含 10,000 样本。在 MNIST 数据集中的每张图片由 28 x 28 个像素点构成,每个像素点用一个灰度值表示。存储在28 x 28 的二维数组中,将这些像素展开为一个每行 784 个值的一维的行向量,每行就是代表了一张图片。
二、构建神经网络训练模型
1.导入库
导入Keras库:layers,models,datasets,utils
Dense方法,Sequential方法,utils.np_utils方法
代码如下(示例):
from keras.layers import Dense
from keras.models import Sequential
from keras.datasets import mnist
from keras.utils import np_utils
2.载入数据
使用以下代码加载Mnist手写数字识别数据集数据(注意红色部分改变为你刚才存储的文件路径)"D:\mydatasets\mnist.npz"
代码如下(示例):
mnist = tf.keras.datasets.mnist
# "D:\mydatasets\mnist.npz" 是Mnist手写数字识别数据集文件所在路径
(x_train,y_train),(x_test,y_test) = mnist.load_data("D:\mydatasets\mnist.npz")
由于数据集包含60,000个用于训练的示例和10,000个用于测试的示例,即训练集中存在60000个样本,测试集中存在10000个样本,其中每一个样本均为28 x 28像素的图片。
由此得知,
- x_train.shape: (60000, 28, 28)
x_test.shape:(10000, 28, 28)
y_train.shape:(60000,) # 训练集标签
y_test.shape:(10000,) # 测试集标签
3.数据处理
样本像素展开
- 以训练集为例,对每一个样本进行像素展开(降维),得到 784 个值的一维的行向量,每行就是代表了一张图片,此时将得到一个行代表每一个图片样本,列代表样本个数的(60000, 784)的二维数组。
数据归一化处理
- 在 MNIST 数据集中的每张图片由 28 x 28 个像素点构成,每个像素点用一个灰度值表示。因此对每个像素进行归一化处理,有助于后续可以加快梯度下降的求解速度,即提升模型的收敛速度,从而优化模型训练速度,减少错误率(error),并提高模型识别精度(accuracy)。
标签转换独热编码
-
对标签数据转换为分类的 one-hot (独热)编码。
原理:One-Hot编码,又称为一位有效编码,主要是采用位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。独热编码是利用0和1表示一些参数,使用N位状态寄存器来对N个状态进行编码。
简单来说:
数字字体识别0~9中,独热编码分别为
0:1000000000
1:0100000000
2:0010000000
3:0001000000
4:0000100000
5:0000010000
6:0000001000
7:0000000100
8:0000000010
9:0000000001生成一个大小(1*10)的矩阵由此表示每个数字,如,数字1的的矩阵为[0100000000]。
然后再通过keras.utils.to_categorical 方法将所有样本组成一个n*10维的二元矩阵,每一行代表每个样本标签的独热码。此时,标签矩阵为(60000, 10)。
代码如下(示例):
# 像素展开,归一化处理
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# 独热编码
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
4.创建模型
创建三层全连接层(Dense)
- 第一层:输入层
- 第二层:隐藏层
- 第三层:输出层
代码如下(示例):
model = Sequential([
Dense(units=200,input_dim=784,bias_initializer='one',activation='tanh'),
Dense(units=100,bias_initializer='one',activation='tanh'),
Dense(units=10,bias_initializer='one',activation='softmax')
])
units:大于0的整数,代表该层的输出维度;
input_dim:可以指定输入数据的维度;
bias_initializer:偏置向量初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置向量的初始化器。“one”是全1初始化;
activation:激活函数,为预定义的激活函数名,tanh函数,sigmoid函数,softmax函数;
5.编译模型
设置优化器,和目标函数,编译模型
-
本实例使用 Adam优化器;目标函数是交叉熵损失函数。
交叉熵损失函数公式:
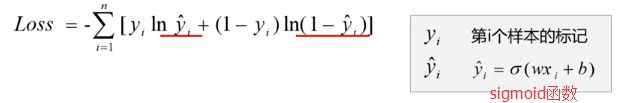
代码如下(示例):
model.compile(optimizer='adam', loss='categorical_crossentropy',metrics=['accuracy'])
optimizer:优化器,为预定义优化器名或优化器对象
loss:目标函数,为预定义损失函数名或一个目标函数,
metrics:设置一个评估模型的指标,该值为一个列表,包含评估模型在训练和测试时的性能的指标,典型用法是metrics=[‘accuracy’],accuracy即精度。
6.训练模型
model.fit() 函数模型训练
代码如下(示例):
model.fit(x_train,y_train,batch_size=32,epochs=5,verbose=2)
x:输入数据。如果模型只有一个输入,那么x的类型是numpy.array(numpy的array数组),如果模型有多个输入,那么x的类型应当为list(列表),list的元素是对应于各个输入的numpy.array
y:标签,numpy.array
batch_size:类型是整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
epochs:指的就是训练过程中数据将被抽到多少次
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
7.评估模型
一般情况下,训练学习模型不仅要提高精度减少误差,还要尽可能避免产生过拟合和欠拟合的情况,因此对学习模型进行评估模型,是评价一个模型优劣的重要环节。
- 过拟合(over-fitting):就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。
- 欠拟合(under-fitting):模型在训练样本被提取的特征比较少,导致训练出来的模型不能很好地匹配,表现得很差,甚至样本本身都无法高效的识别。
代码如下(示例):
loss_train,accuracy_train = model.evaluate(x_train,y_train)
print('train loss:',loss_train,'train accuracy:',accuracy_train)
loss_test,accuracy_test = model.evaluate(x_test,y_test)
print('test loss:',loss_test,'test accuracy:',accuracy_test)
三、总代码
from keras.layers import Dense
from keras.models import Sequential
from keras.datasets import mnist
from keras.utils import np_utils
#载入数据
(x_train,y_train),(x_test,y_test) = mnist.load_data('D:\mydatasets\mnist.npz')
# print('x_train:',x_train.shape,'y_train:',y_train.shape)
#数据处理
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
#创建模型,输入784个神经元,输出10个神经元
model = Sequential([
Dense(units=200,input_dim=784,bias_initializer='one',activation='tanh'),
Dense(units=100,bias_initializer='one',activation='tanh'),
Dense(units=10,bias_initializer='one',activation='softmax')
])
#定义优化器,编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(x_train,y_train,batch_size=32,epochs=5,verbose=2)
#评估模型
loss_train,accuracy_train = model.evaluate(x_train,y_train)
print('train loss:',loss_train,'train accuracy:',accuracy_train)
loss_test,accuracy_test = model.evaluate(x_test,y_test)
print('test loss:',loss_test,'test accuracy:',accuracy_test)
运行结果:
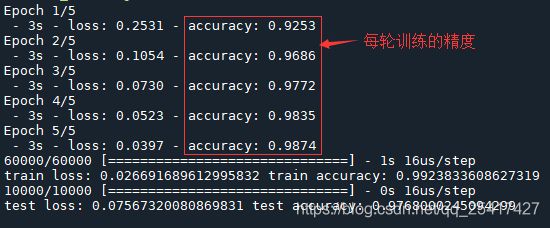
由上图可知,train accuracy的训练精度为99.2%,test accuracy的测试精度为97.6% 。