深度学习之Pytorch------DNN实现MNIST手写数字识别
目录
1.MNIST数据集介绍
2.Pytorch实现DNN
1.MNIST数据集介绍
MNIST数据集在torvision.datasets里面,可以自行加载,其中训练集有6W张,测试集有1W张,都为灰度图,即channel为1,图片的大小都是28x28,下面我们通过代码测试以下。
1. 导入工具包
# 导入工具包
from PIL import Image
import numpy as np
import torchvision
from torch.utils.data import DataLoader
2. 加载数据
train_data = torchvision.datasets.MNIST(
root = './mnist',
# train = True 为 训练集,6w张照片;train = False 为 测试集,1w张照片
train = True,
# download 在第一次加载数据集时需要指定为 True,后面就不需要了,即从./mnist 目录中加载
# download = True
) # 通过此句,现 6W 中张照片均在 train_data 中,每一张照片都是 28 * 28 大小
# 构建可迭代的数据装载器,这里我们设置的 batch_size = 1,即一次循环,读取一张图片
train_loader = DataLoader(dataset=train_data, batch_size=1, shuffle=True)3. 图片显示函数
def img_show(img):
pil = Image.fromarray(np.uint(img))
pil.show()
4. 测试观察图片
for i, data in enumerate(train_data):
# 这里我们只读取1张照片,看下效果就行
if i == 1:
break
"""
data 是一个元组,你可以简单理解为它的0下标处存放的是batch_size张图片;
1下标处存放的是batch_size张图片分别对应的数字
"""
x, y = data
img_show(x)
简单看下效果,train_data的第一张图片就是 5

2.Pytorch实现DNN
1. 导入工具包
import torch
import numpy as np
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
2. 超参数设置
# 分批次训练,一批 64 个
BATCH_SIZE = 64
# 所有样本训练 3 次
EPOCHS = 3
# 学习率设置为 0.0006
LEARN_RATE = 6e-4
# 若当前 Pytorch 版本以及电脑支持GPU,则使用 GPU 训练,否则使用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
3. 读取数据集
# 训练集数据加载
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
"""
将下载的文件转换成pytorch认识的tensor类型,且将图片的数值大小从(0-255)归一化到(0-1)
经过此步,现在每一张照片大小为 (1, 28, 28),1是通道数,灰度照片,通道数为 1
并且每张照片的灰度值都由 (0 - 255)归一化到 (0 - 1)
"""
transform=torchvision.transforms.ToTensor()
)
# 构建训练集的数据装载器,一次迭代有 BATCH_SIZE 张图片
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 测试集数据加载
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False,
transform=torchvision.transforms.ToTensor()
)
# 构建测试集的数据加载器,一次迭代 1 张图片,我们一张一张的测试
test_loader = DataLoader(dataset=test_data, batch_size=1, shuffle = True)4. 定义DNN神经网络
"""
此处我们定义了一个 3 层的网络
隐藏层 1:40 个神经元
隐藏层 2:20 个神经元
输出层:10 个神经元
"""
class DNN(nn.Module):
def __init__(self):
super(DNN, self).__init__()
# 隐藏层 1,使用 sigmoid 激活函数
self.layer1 = nn.Sequential(
nn.Linear(784, 40),
nn.Sigmoid()
)
# 隐藏层 2,使用 sigmoid 激活函数
self.layer2 = nn.Sequential(
nn.Linear(40, 20),
nn.Sigmoid()
)
# 输出层
self.layer_out = nn.Linear(20, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
self.out = self.layer_out(x)
return self.out
5. 实例化model,并且定义优化器以及损失函数
# 实例化DNN,并将模型放在 GPU 训练
model = DNN().to(device)
# 同样,将损失函数放在 GPU
loss_fn = nn.MSELoss(reduction='mean').to(device)
#大数据常用Adam优化器,参数需要model的参数,以及学习率
optimizer = torch.optim.Adam(model.parameters(), lr=LEARN_RATE)6. 训练模型
for epoch in range(EPOCHS):
# 加载训练数据
for step, data in enumerate(train_loader):
x, y = data
"""
因为此时的训练集即 x 大小为 (BATCH_SIZE, 1, 28, 28)
因此这里需要一个形状转换为(BATCH_SIZE, 784);
y 中代表的是每张照片对应的数字,而我们输出的是 10 个神经元,
即代表每个数字的概率
因此这里将 y 也转换为该数字对应的 one-hot形式来表示
"""
x = x.view(x.size(0), 784)
yy = np.zeros((x.size(0), 10))
for j in range(x.size(0)):
yy[j][y[j].item()] = 1
yy = torch.from_numpy(yy)
yy = yy.float()
x, yy = x.to(device), yy.to(device)
# 调用模型预测
output = model(x).to(device)
# 计算损失值
loss = loss_fn(output, yy)
# 输出看一下损失变化
print(f'EPOCH({epoch}) loss = {loss.item()}')
# 每一次循环之前,将梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度下降,更新参数
optimizer.step() 下面是运行结果
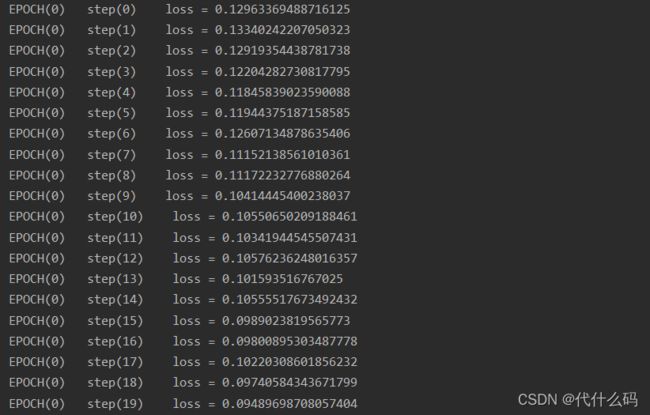
7. 开始测试吧
sum = 0
# test:
for i, data in enumerate(test_loader):
x, y = data
# 这里 仅对 x 进行处理
x = x.view(x.size(0), 784)
x, y = x.to(device), y.to(device)
res = model(x).to(device)
# 得到 模型预测值
r = torch.argmax(res)
# 标签,即真实值
l = y.item()
sum += 1 if r == l else 0
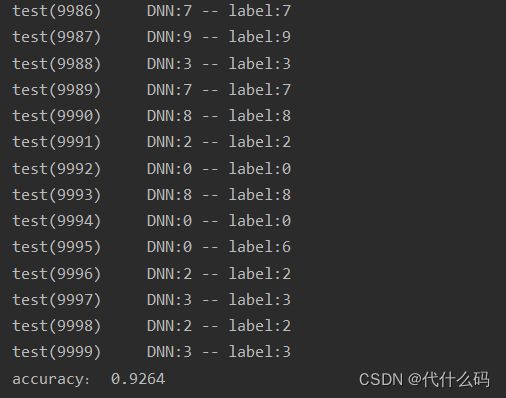
print(f'test({i}) DNN:{r} -- label:{l}')
print('accuracy:', sum / 10000)下面是运行结果,正确率也一般般,92左右,这里就是去更多的调试参数了,网络层数,神经元个数,学习率等 ^o^
附上完整代码
import torch
import numpy as np
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
# 分批次训练,一批 64 个
BATCH_SIZE = 64
# 所有样本训练 3 次
EPOCHS = 3
# 学习率设置为 0.0006
LEARN_RATE = 6e-4
# 若当前 Pytorch 版本以及电脑支持GPU,则使用 GPU 训练,否则使用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 训练集数据加载
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
transform=torchvision.transforms.ToTensor()
)
# 构建训练集的数据装载器,一次迭代有 BATCH_SIZE 张图片
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 测试集数据加载
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False,
transform=torchvision.transforms.ToTensor()
)
# 构建测试集的数据加载器,一次迭代 1 张图片,我们一张一张的测试
test_loader = DataLoader(dataset=test_data, batch_size=1, shuffle = True)
"""
此处我们定义了一个 3 层的网络
隐藏层 1:40 个神经元
隐藏层 2:20 个神经元
输出层:10 个神经元
"""
class DNN(nn.Module):
def __init__(self):
super(DNN, self).__init__()
# 隐藏层 1,使用 sigmoid 激活函数
self.layer1 = nn.Sequential(
nn.Linear(784, 40),
nn.Sigmoid()
)
# 隐藏层 2,使用 sigmoid 激活函数
self.layer2 = nn.Sequential(
nn.Linear(40, 20),
nn.Sigmoid()
)
# 输出层
self.layer_out = nn.Linear(20, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
self.out = self.layer_out(x)
return self.out
# 实例化DNN,并将模型放在 GPU 训练
model = DNN().to(device)
# 同样,将损失函数放在 GPU
loss_fn = nn.MSELoss(reduction='mean').to(device)
#大数据常用Adam优化器,参数需要model的参数,以及学习率
optimizer = torch.optim.Adam(model.parameters(), lr=LEARN_RATE)
for epoch in range(EPOCHS):
# 加载训练数据
for step, data in enumerate(train_loader):
x, y = data
"""
因为此时的训练集即 x 大小为 (BATCH_SIZE, 1, 28, 28)
因此这里需要一个形状转换为(BATCH_SIZE, 784);
y 中代表的是每张照片对应的数字,而我们输出的是 10 个神经元,
即代表每个数字的概率
因此这里将 y 也转换为该数字对应的 one-hot形式来表示
"""
x = x.view(x.size(0), 784)
yy = np.zeros((x.size(0), 10))
for j in range(x.size(0)):
yy[j][y[j].item()] = 1
yy = torch.from_numpy(yy)
yy = yy.float()
x, yy = x.to(device), yy.to(device)
# 调用模型预测
output = model(x).to(device)
# 计算损失值
loss = loss_fn(output, yy)
# 输出看一下损失变化
print(f'EPOCH({epoch}) loss = {loss.item()}')
# 每一次循环之前,将梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度下降,更新参数
optimizer.step()
sum = 0
# test:
for i, data in enumerate(test_loader):
x, y = data
# 这里 仅对 x 进行处理
x = x.view(x.size(0), 784)
x, y = x.to(device), y.to(device)
res = model(x).to(device)
# 得到 模型预测值
r = torch.argmax(res)
# 标签,即真实值
l = y.item()
sum += 1 if r == l else 0
print(f'test({i}) DNN:{r} -- label:{l}')
print('accuracy:', sum / 10000)