基于opencv模板匹配的单目标跟踪
基于模板的物体跟踪
- 模板匹配
- 核心函数
- 完整代码
- 效果展示
- 多目标检测
模板匹配
调用函数:
cv.matchTemplate(image, templ, method, result=None, mask=None)
image: 输入图片1,图中包含模板的完整图片;
templ: 输入图片2,模板图片。size必须小于image;
method:采用何种匹配方式;
result:比较结果的映射图像,必须是单通道32位浮点格式,一般不设置;
mask: 搜索模板的mask(不知道咋翻译会好一点),它必须与templ具有相同的类型和大小。 默认情况下未设置。
参数 method:
CV_TM_SQDIFF 平方差匹配法:该方法采用平方差来进行匹配;最好的匹配值为0;匹配越差,匹配值越大。
CV_TM_CCORR 相关匹配法:该方法采用乘法操作;数值越大表明匹配程度越好。
CV_TM_CCOEFF 相关系数匹配法:1表示完美的匹配;-1表示最差的匹配。
CV_TM_SQDIFF_NORMED 归一化平方差匹配法
CV_TM_CCORR_NORMED 归一化相关匹配法
CV_TM_CCOEFF_NORMED 归一化相关系数匹配法,一般情况下用的最多吧
需要注意的是不同的方式返回的参数大小代表的意义不同
核心函数
def template_demo(tpl, target, method = cv2.TM_CCORR_NORMED):
th, tw = tpl.shape[:2]# 取高宽,不取通道 模板高宽
result = cv2.matchTemplate(target, tpl, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result) # 寻找最小值,最大值。最小值位置,最大值位置
tl = max_loc
br = (tl[0]+tw, tl[1]+th)
print(max_val, tl, br)
if max_val < 0.45:
lost = 1
else:
lost = 0
return tl, br, lost
输入的参数意义:
tpl:完整的图片;
target: 模板;
method: 默认的是cv2.TM_CCORR_NORMED;
输出的参数意义:
tl: 左上角坐标;
br:右下角坐标;
lost:目标是否丢失在视野,1代表丢失;
完整代码
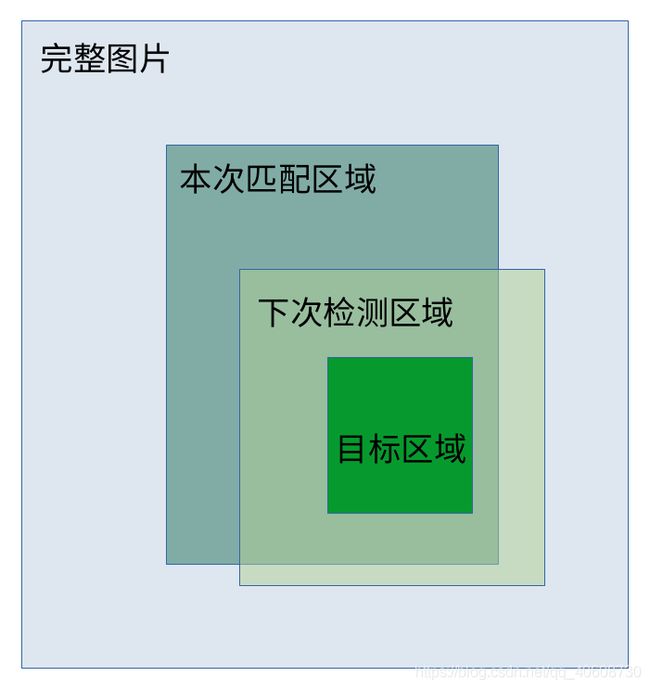
大致的原理图如下图所示,具体的思路都在代码里。
import cv2 as cv2
import numpy as np
from subprocess import call
def template_demo(tpl, target, method = cv2.TM_CCORR_NORMED):
th, tw = tpl.shape[:2]# 取高宽,不取通道 模板高宽
result = cv2.matchTemplate(target, tpl, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result) # 寻找最小值,最大值。最小值位置,最大值位置
tl = max_loc
br = (tl[0]+tw, tl[1]+th)
print(max_val, tl, br)
if max_val < 0.45:
lost = 1
else:
lost = 0
return tl, br, lost
if __name__ == '__main__':
print("--------- Python OpenCV Tutorial ---------")
cap = cv2.VideoCapture('person.mp4')
ret, frame = cap.read()
print(frame.shape)
lam = 1
fourcc = cv2.VideoWriter_fourcc(*'XVID') # 保存视频的编码
out = cv2.VideoWriter('person_output.avi',fourcc, 20.0, (frame.shape[1], frame.shape[0]))
gROI = cv2.selectROI("ROI frame", frame, False) # 用鼠标设置要跟踪的目标
ROI = frame[gROI[1]: gROI[1]+gROI[3], gROI[0]:gROI[0]+gROI[2], :] # 截取相关的区域
area = [0, frame.shape[1], 0, frame.shape[0]] # area代表着被匹配的图片在完整图片中的区域
while True:
ret, frame = cap.read()
if ret:
frame1 = frame[area[2]:area[3], area[0]:area[1], :] # 为了增加稳定性,截取模板周围的图片当做被匹配的图片,不会跑到很远的地方
tl, br, lost = template_demo(ROI, frame1, method=cv2.TM_CCOEFF_NORMED)
if lost==1: # 如果目标丢失,则加大搜索范围,正常范围是模板的4倍面积,丢失的话就是16倍面积
lam = 2
else:
lam = 1
# ROI = frame1[tl[1]:br[1], tl[0]:br[0], :] # 一开始是想根据检测的结果更新模板,但是程序运行过程中,会有误差的累积,会越来越大,导致检测失败,目前还没有很好地方法。
# cv2.imshow('ROI', ROI)
result = cv2.rectangle(frame, (area[0]+tl[0], area[2]+tl[1]), (br[0]+area[0], br[1]+area[2]), (0, 0, 255), 2) # 在完整图片上框选
cv2.imshow('result', result)
# 随着检测的数据,更新area的参数
area[0] = (tl[0] + br[0]) // 2 - lam * (br[0] - tl[0]) + area[0]
area[1] = (tl[0] + br[0]) // 2 + lam * (br[0] - tl[0]) + area[0]
area[2] = (tl[1] + br[1]) // 2 - lam * (br[1] - tl[1]) + area[2]
area[3] = (tl[1] + br[1]) // 2 + lam * (br[1] - tl[1]) + area[2]
# area不能超出完整图片的范围
area[0] = 0 if area[0] < 0 else area[0]
area[1] = frame.shape[1] if area[1] > frame.shape[1] else area[1]
area[2] = 0 if area[2] < 0 else area[2]
area[3] = frame.shape[0] if area[3] > frame.shape[0] else area[3]
out.write(result) # 检测结果存储成视频
cv2.waitKey(18)
else: # 视频终止就退出
break
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 结束后的处理
cap.release()
cv2.destroyAllWindows()
# 因为opencv只能输出avi格式的视频 但是视频占用内存较大,所以通过ffmpeg改成mp4格式,可以通过sudo apt-get install ffmpeg安装
command = "ffmpeg -i person_output.avi person_output.mp4"
call(command.split())
效果展示
对于这种变化只有还是原来的形状的球来说,检测算法的效果很好,但是对于一些跑动的物体,特别是相似的物体而言,检测算法就可能会出问题。
但是值得注意的是,它只会在模板的周围进行检测,不会跳的特别远。
多目标检测
在此基础上就行了改进,参看另一博客:多目标检测