以下几个C语言关键字你真的得懂(深度解剖)
 篮球哥温馨提示:编程的同时不要忘记锻炼哦!
篮球哥温馨提示:编程的同时不要忘记锻炼哦!
时间不在于你拥有多少,而在于你怎样使用。
我总能成功,I always succeed!
1、什么是语句,表达式?
2、bool 变量在C语言中到底是怎么一回事?
3、浮点数 真的是你想的这样吗?
4、指针变量和 0 比较
5、else 匹配问题以及 if 的其他常见问题
1、什么是语句,表达式?
这里因为是解剖C语言,所以简单介绍一下:
在C语言中 ,凡是以分号隔开的就是一条语句:
- printf("hello world\n");
- a = 1 + 2;
- ; (空语句)
什么是表达式呢?
C语言中,用各种操作符把变量连起来,形成有意义的式子,叫做表达式:
- if (表达式)
- while(表达式)
- a > b ? a : b;
- a = b + c;
2、bool 变量在C语言中是到底怎么一回事?
C语言中有没有bool类型呢?
在c99之前,主要是c90是没有的,目前大部分书,基本上都是认为没有的,但是c99引入了 _Bool 类型 (新增在头文件 stdbool.h 中,被重新用宏写成了bool,为了保证C/C++兼容性)我们可以用编译器转到 bool 定义里头看一看:
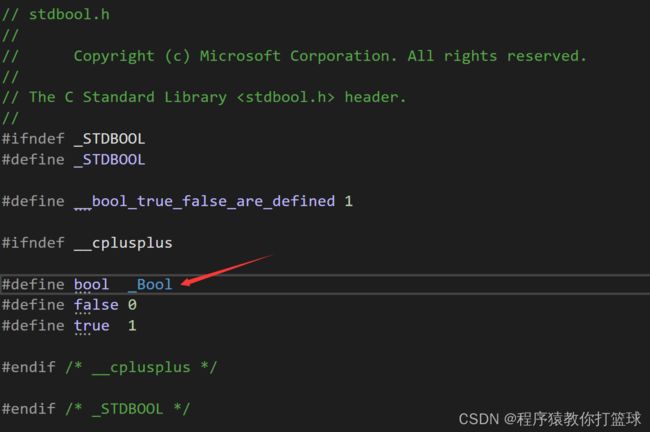
那么布尔类型的大小变量占几个字节呢?(一个字节)
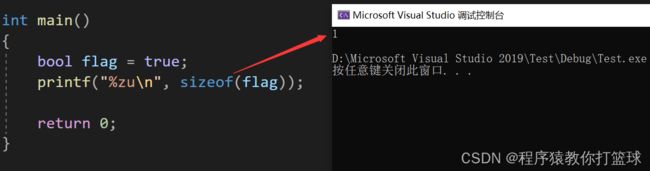
既然有了bool型,那么我们以后使用bool进行判断如何写呢?举一个例子:

这里我们推荐第三种写法,为什么呢,因为如上图的 flag 本身就是一个bool类型,没必要在进行 if 里面第一步执行表达式了(后面有讲)。
结论:bool类型,直接判定,不用操作符进行和特定值比较。
有趣环节:
我们来看一个有趣的代码:
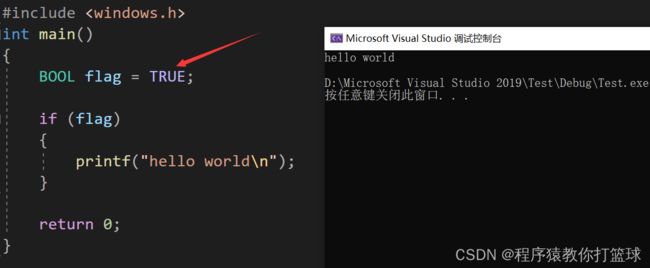
这里bool类型大写为什么也可以使用呢?C/C++不是对大小写很敏感吗?那么我们直接刨根问底,双击BOOL右键转到定义看他到底是何方妖怪!
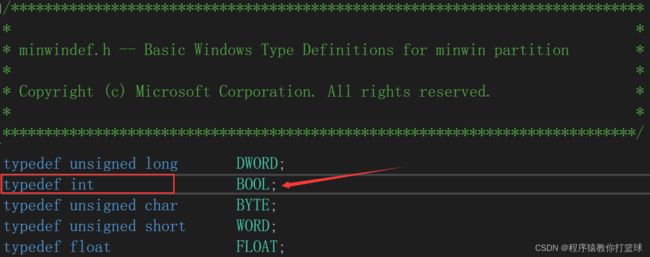
其实啊,这些是Microsoft自己搞的一套BOOL值。在vs中转到BOOL对应的头文件,翻到最上面,就能看到微软的版权信息。
那么推荐使用吗?
强烈不推荐,因为好的习惯是:一定要保证代码的跨平台性,微软定义的专属类型,其他平台不支持。(以后在语言 编程层面上,凡是直接使用和平台强相关的内容,我们都不推荐。
3、浮点数 真的是你想的这样吗?
首先我们得知道这样一个概念:C语言的浮点数是会造成精度损失的!(浮点数的存储)
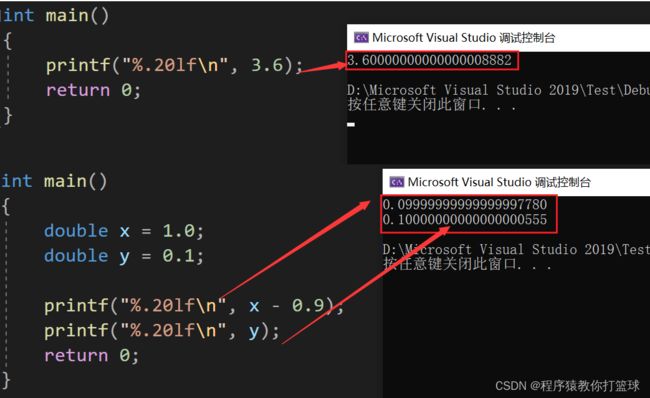
那么,浮点数可以直接进行比较吗?

显然是不能直接比较的,浮点数在进行比较的时候,是不能直接用==来比较的,因为浮点数本身有精度损失,从而导致各种结果可能会有细微的差别!
那么浮点数之间该怎么比较呢?
应该进行范围精度比较!
精度: 自己设置,通常是宏定义。 或者使用系统精度!


以上两种方法都可以进行浮点数比较,那么浮点数跟 0 比较又是怎么一回事呢?
我们有了以上的例子,可以知道浮点数肯定是不能直接 == 比较的,那么如何跟 0 比较呢?接着往下看:

通过上图两个代码我们可以发现,当数值足够小的话会被判定成0,我们可能在一些书上写的是<= DBL_EPSILON 有必要吗?其实是没有必要的!
fabs(x) <= DBL_EPSILON(确认x是否是0的逻辑),如果=,就说明x本身,已经能够引起其他和他+-的数 据本身的变化了,这个不符合0的概念。因为0 +- 任何一个数都等于0!
总结:
- 浮点数存储的时候,是有精度损失的。
- 浮点数不能进行 == 比较的
- if (fabs(a - b) < DBL_EPSILON)
4、指针变量和 0 比较
通过我们之前对C语言的学习,我们知道有三种可以表示0的方法:(bool为c99标准暂时不考虑)。

如上可知他们的类型是不相同的!就比如我们初始化时操作符两边值的类型要保持一致的!
如果类型不一样的话不同的编译器可能会报警,这个小伙伴们可以自己去测试,但至于变量建议保持一致,是否应该初始化我在上期讲过了,可以去看一看!
//例:
int main()
{
int a = 0;
double b = 0.0;
int* p = NULL;
return 0;
}看到这,我们来解决上面那个警告的问题,我们说他们的类型不同,究竟是为什么呢?

我们双击NULL转到定义可以看到,NULL是一个void*类型,那么我们知道用 printf 以 %d 打印时是以整型打印的,所以这里我们就要用到强制类型转换了,NULL不是void*类型吗,那我们就把他强制转换成int型,我们接着看:

可以看到,强制类型转换之后编译器正常了,连警告都没有,代码直接跑起来,那么如何理解强制类型转换呢?
这里有个小故事:
假设我们都坐在教室里上课,老师对我们说,等会要来一位同学要转到我们班来,那同学特别坏,天天欺负同学,过了一会那个同学走进教室,同学们因为听了老师的话所以一对他印象很不好,过了一会老师又对同学们说,老师说错了,这位同学特别乐于助人,成绩也很好是个好学生,同学们对他的印象又发生改变了,这就可以理解成强制类型转换。
那么简单来说,0还是那个0,我们只是用不同的类型去解释这个0,强制类型转换数据本身还是他自己,并不会改变内存中的数值,我们只是用我们想要的类型去解释他而已!
5、else 匹配问题以及 if 的其他常见问题
首先我们来看一段很简单的代码:
int main()
{
int val = 1;
if (1 == val)
{
printf("hello world\n");
}
return 0;
}当然我不是问小伙伴们这段代码打印啥,而是问这段代码的执行过程是怎样的?
- 先执行()中的表达式 or 函数,得到真假结果(true,false)逻辑结果
- 接着对结果进行条件判定功能
- 然后再执行下面进行分支功能
看到这呢,我想问问小伙伴有没有被不好的代码风格给影响到?这里有一段代码我们一起来看看:
int main()
{
int x = 0;
int y = 1;
if (10 == x)
if (11 == y)
printf("hello world\n");
else
printf("hello basketball\n");
return 0;
}看完这段代码可能有小伙伴会说打印 "hello basketball", 也有的小伙伴会说什么也不打印!其实这串代码最终是什么都不打印!!!为什么呢,因为 else 匹配采用就近原则,如果我们换一下代码风格,我们再来看看:
int main()
{
int x = 0;
int y = 1;
if (10 == x)
{
if (11 == y)
printf("hello world\n");
else
printf("hello basketball\n");
}
return 0;
}这样是不是就是清晰很多了?所以通过上面我们要知道 else 的匹配规则,以及我们也要养成良好的代码风格!
下面有一个很好的代码风格爱打篮球的程序猿想给各位小伙伴推荐一下:
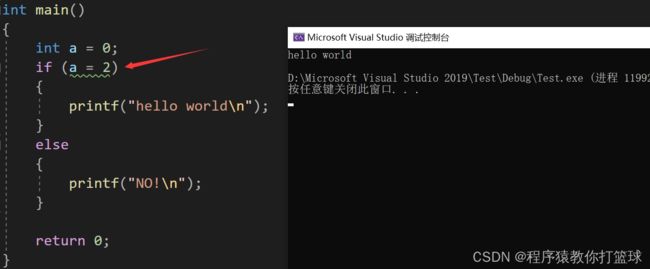
上面的代码编译器并不会报错,仍然可以运行,但是我们想要的是如果 a == 2 我们才执行下面的打印,其实在日常写代码中,如果我们手误把 == 写成了 = 编译器是不会告诉我们的,在编程中,越早发现问题越好,那么像上面的手误操作我们应该如何避免呢?
我们可以把常量写在左边,因为赋值表达式的左值是必须可修改的,如果我们把常量放到左边了,把 == 写成了 = 编译器会直接报错:

这样写的话,我们就能直接发现代码中的错误了,会使我们更早的发现错误,所以我建议小伙伴如何写这种类似的代码呢:
int main()
{
int a = 0;
if (2 == a)
{
printf("hello world\n");
}
else
{
printf("NO!\n");
}
return 0;
}这样写代码就会万无一失啦!
好了本期要讲解的几个关键字就到这里了,想必看完的小伙伴都有收获吧!接下来还会接着带你们更深度的解剖我们的C语言哦!
答案没有正式揭晓前,什么都是可能的!
