跑通caffe-ssd demo代码(训练、测试自己数据集)
跑通caffe-ssd demo代码(训练、测试自己数据集)
ssd网络我就不多介绍了,CSDN上面一搜一大把。这篇主要讲讲如何跑通caffe代码~
github:caffe-ssd
一、代码结构

在caffe-ssd中能用到的文件我全部在上述图片中标出来了,到时候具体的再细说~
caffe-ssd的环境自己百度吧,网上很多安装教程~
二、数据集准备
训练模型,首先第一个事情就是准备数据集。在利用caffe训练分类模型的时候,通常使用lmdb或者hdf5格式的数据,但是在该项目中使用的是lmdb格式的(其他格式的数据肯定也行,但是就是需要自己c++手写数据处理层了~太麻烦了)
1.
首先,准备VOC格式的数据

这是VOC数据集的格式,其中,Annotations里面存放的是所有数据图片相对应的xml标签文件,imagesets里面存放的是一些txt文件,后续用到再详细说,JPEGImages里面存放的就是训练图片,最后两个文件夹是用于实例分割的,在目标检测中用不到,所以就不用管它。(这里,为了简单,所以只使用VOC_trainval_2007中前36张图片)
JPEGImages:

其中,trainval里面存放训练图片,test存放测试图片。这个划分根据你自己项目进行决定就行。一般来说,trainval:test=4:1,这里我在test存放8张随机图片,剩余的存放在trainval文件夹中。值得一提,全部的图片还是放在trainval和test文件夹同级目录中,这样便于后续生成trainval.txt和test.txt。
Annotations:

Imagesets:

2.
下面介绍如何生成Imagesets里面的这四个txt文件~
先说trainval.txt和test.txt这两个文件。
#! /usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import glob
trainval_dir = r"D:\voc\VOC_test\JPEGImages\trainval" #训练集图片存放地址
test_dir = r"D:\voc\VOC_test\JPEGImages\test" #测试图片存放地址
trainval_img_lists = glob.glob(trainval_dir + '/*.jpg') #如果你的图片是png格式的,只需要修改最后的后缀
trainval_img_names = []
for item in trainval_img_lists:
temp1, temp2 = os.path.splitext(os.path.basename(item))
trainval_img_names.append(temp1)
test_img_lists = glob.glob(test_dir + '/*.jpg') #如果你的图片是png格式的,只需要修改最后的后缀
test_img_names = []
for item in test_img_lists:
temp1, temp2 = os.path.splitext(os.path.basename(item))
test_img_names.append(temp1)
#图片路径和xml路径
dist_img_dir = r"D:\voc\VOC_test\JPEGImages" #JPEGImages路径
dist_anno_dir = r"D:\voc\VOC_test\Annotations" #存放所有数据的xml文件路径
trainval_fd = open(r"D:\voc\VOC_test\ImageSets\trainval.txt", 'w') #trainval.txt存放地址
test_fd = open(r"D:\voc\VOC_test\ImageSets\test.txt", 'w') #test.txt存放地址
for item in trainval_img_names:
trainval_fd.write(dist_img_dir + '/' + str(item) + '.jpg' + ' ' + dist_anno_dir + '/' + str(item) + '.xml\n')
for item in test_img_names:
test_fd.write(dist_img_dir + '/' + str(item) + '.jpg' + ' ' + dist_anno_dir + '/' + str(item) + '.xml\n')
生成的trainval.txt:

test.txt:

注意:这里我建议大家使用绝对路径,到时候在训练的时候比较清楚点
3.
下面介绍labelmap_voc.prototxt:
labelmap_voc.prototxt文件在你下载的caffe-ssd中有一个副本,位置在:you_caffe_root/data/VOC0712/里面,这里面的数据要根据你自己的需求进行修改,因为我这里就是VOC数据集,所以我不用改变的。不过假如我想进行猫狗目标检测算法,那我就得这么改:
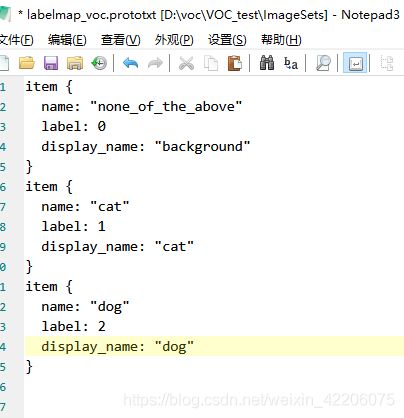
这里,label为0的是背景一类,不管你是检测多少种物体,这一类是不能动的。
4.
下面就是test_name_size.txt生成方式:
#! /usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import glob
from PIL import Image #读图
img_dir = r"D:/voc/VOC_test/JPEGImages/test" #测试图片存放路径
#获取制定路径下的所有jpg图片的名称
img_lists = glob.glob(img_dir + '/*.jpg')
test_name_size = open(r"D:/voc/VOC_test/ImageSets/test_name_size.txt", 'w') #test_name_size.txt存放路径
for item in img_lists:
img = Image.open(item)
width, height = img.size
temp1, temp2 = os.path.splitext(os.path.basename(item))
test_name_size.write(temp1 + ' ' + str(height) + ' ' + str(width) + '\n')
最后生成的test_name_size.txt:

其中,每一列中第一个表示测试图片名称,第二个和第三个表示的是该测试图片的高和宽。
这样,所有准备工作都做完了~用上述所有文件就可以生成lmdb数据了
5.
将VOC文件夹放在you_caffe_root/data中

定位到you_caffe_root/data/VOC0712,下面应该有两个shell脚本文件:create_list.sh和create_data.sh。前者其实就是生成trainval.txt和test.txt,因为我们已经用python脚本生成好了,所以就可以直接用后者来生成lmdb数据了。
create_data.sh:
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir=$cur_dir/../.. #你安装caffe的根目录
cd $root_dir
redo=1
data_root_dir="" #上述VOC总文件夹的位置
mapfile="" #上述生成的labelmap_voc.prototxt存放位置
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python $root_dir/scripts/create_annoset.py #该sh脚本本质上是调用的是scripts/create_annoset.py,你找到create_annoset.py位置就行
--anno-type=$anno_type
--label-map-file=$mapfile
--min-dim=$min_dim
--max-dim=$max_dim
--resize-width=$width
--resize-height=$height
# 很多人最后训练代码出错其实就是最后一行没有设置正确
--check-label
$extra_cmd #这个不用管
$data_root_dir #这个不用管
$root_dir/data/$dataset_name/$subset.txt #这个位置是上述生成的trainval.txt和test.txt文件路径,这个要设置好
$data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db #这一个参数是设置生成lmdb文件的路径,一般来说,最好设置在VOC总文件夹下面,即同JPEGImages、Annotations、Images在同一个路径下,当然,也可以事先自己在VOC总文件夹下面创建一个lmdb的文件夹,该lmdb文件夹下面又有两个子文件夹,分别代表的是训练lmdb数据和测试lmdb数据
examples/$dataset_name
done
注意点:
1.如果代码运行报错(明明图片和xml标签路径是正确的,但是就是无法生成lmdb),那么找到create_annoset.py第87行:
img_file, anno = line.strip("\n").split(" ")
改为
img_file, anno = line.strip("\n").strip("\r").split(" ")
2.生成LMDB文件,首先是sh create_data.sh,内部会调用python root_caffe_dir/scripts/create_annotation.py,但是真正调用的其实是root_caffe_dir/build/tools/convert_annoset的二进制文件,该文件又是由root_caffe_dir/tools/convert_annoset.cpp编译而来。打开root_caffe_dir/tools/convert_annoset.cpp,在大约157行左右可以看到:
filename = root_folder + lines[line_id].first;
所以说,官方代码默认带了caffe的根目录,所以如果想要匹配路径的话,就要修改你生成的trainval.txt和test.txt两个文件中图片的路径,或者是修改root_caffe_dir/tools/convert_annoset.cpp里面的代码,然后重新编译一边。
三、开始训练
与以往caffe实现分类网络不同的是,该项目是通过py脚本进行训练的,而不是直接通过caffe的c++接口进行训练。
该py脚本的位置在:you_caffe_root/examples/ssd/ssd_pascal.py。
上述图片中还有一个ssd_detect.py脚本,该脚本就是用于测试单张图片用的,这个后续再说。
ssd_pascal.py:
具体需要修改的地方会在下面标注清楚的
from __future__ import print_function
import caffe
from caffe.model_libs import *
from google.protobuf import text_format
import math
import os
import shutil
import stat
import subprocess
import sys
# Add extra layers on top of a "base" network (e.g. VGGNet or Inception).
def AddExtraLayers(net, use_batchnorm=True, lr_mult=1):
use_relu = True
# Add additional convolutional layers.
# 19 x 19
from_layer = net.keys()[-1]
# TODO(weiliu89): Construct the name using the last layer to avoid duplication.
# 10 x 10
out_layer = "conv6_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv6_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 512, 3, 1, 2,
lr_mult=lr_mult)
# 5 x 5
from_layer = out_layer
out_layer = "conv7_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv7_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 1, 2,
lr_mult=lr_mult)
# 3 x 3
from_layer = out_layer
out_layer = "conv8_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv8_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
# 1 x 1
from_layer = out_layer
out_layer = "conv9_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv9_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
return net
### Modify the following parameters accordingly ###
# The directory which contains the caffe code.
# We assume you are running the script at the CAFFE_ROOT.
caffe_root = os.getcwd()
# Set true if you want to start training right after generating all files.
run_soon = True
# Set true if you want to load from most recently saved snapshot.
# Otherwise, we will load from the pretrain_model defined below.
resume_training = True
# If true, Remove old model files.
remove_old_models = False
# The database file for training data. Created by data/VOC0712/create_data.sh
train_data = "examples/VOC0712/VOC0712_trainval_lmdb" #该地址为上述生成的lmdb格式的训练数据,注意的是,该地址为存放lmdb数据的上一级文件夹
# The database file for testing data. Created by data/VOC0712/create_data.sh
test_data = "examples/VOC0712/VOC0712_test_lmdb" #该地址为上述生成的lmdb格式的测试数据,注意的是,该地址为存放lmdb数据的上一级文件夹
# Specify the batch sampler.
resize_width = 300 #该模型接收输入图片的宽
resize_height = 300 #该模型接收输入图片的高
resize = "{}x{}".format(resize_width, resize_height)
batch_sampler = [
{
'sampler': {
},
'max_trials': 1,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.1,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.3,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.5,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.7,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.9,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'max_jaccard_overlap': 1.0,
},
'max_trials': 50,
'max_sample': 1,
},
]
train_transform_param = { #这个字典里面就是进行数据增强的操作,其实我感觉可以不要该操作,但是没有尝试过注释后代码还能不能跑通
'mirror': True,
'mean_value': [104, 117, 123], #图片均值
'resize_param': {
'prob': 1,
'resize_mode': P.Resize.WARP,
'height': resize_height,
'width': resize_width,
'interp_mode': [
P.Resize.LINEAR,
P.Resize.AREA,
P.Resize.NEAREST,
P.Resize.CUBIC,
P.Resize.LANCZOS4,
],
},
'distort_param': {
'brightness_prob': 0.5,
'brightness_delta': 32,
'contrast_prob': 0.5,
'contrast_lower': 0.5,
'contrast_upper': 1.5,
'hue_prob': 0.5,
'hue_delta': 18,
'saturation_prob': 0.5,
'saturation_lower': 0.5,
'saturation_upper': 1.5,
'random_order_prob': 0.0,
},
'expand_param': {
'prob': 0.5,
'max_expand_ratio': 4.0,
},
'emit_constraint': {
'emit_type': caffe_pb2.EmitConstraint.CENTER,
}
}
test_transform_param = {
'mean_value': [104, 117, 123],
'resize_param': {
'prob': 1,
'resize_mode': P.Resize.WARP,
'height': resize_height,
'width': resize_width,
'interp_mode': [P.Resize.LINEAR],
},
}
# If true, use batch norm for all newly added layers.
# Currently only the non batch norm version has been tested.
use_batchnorm = False
lr_mult = 1
# Use different initial learning rate.
if use_batchnorm:
base_lr = 0.0004
else:
# A learning rate for batch_size = 1, num_gpus = 1.
base_lr = 0.00004 #一般来说,我们会调用这个学习率,但是实际在训练的时候的学习率应该为base_lr * 25,所以说如果想增减学习率,只需要修改此处就可以
# Modify the job name if you want.
job_name = "SSD_{}".format(resize)
# The name of the model. Modify it if you want.
model_name = "VGG_VOC0712_{}".format(job_name)
# Directory which stores the model .prototxt file.
save_dir = "models/VGGNet/VOC0712/{}".format(job_name) #最后生成caffemodel的位置
# Directory which stores the snapshot of models.
snapshot_dir = "models/VGGNet/VOC0712/{}".format(job_name)
# Directory which stores the job script and log file.
job_dir = "jobs/VGGNet/VOC0712/{}".format(job_name)
# Directory which stores the detection results.
output_result_dir = "{}/data/VOCdevkit/results/VOC2007/{}/Main".format(os.environ['HOME'], job_name)
# model definition files.
train_net_file = "{}/train.prototxt".format(save_dir) #train.prototxt位置
test_net_file = "{}/test.prototxt".format(save_dir) #test.prototxt位置
deploy_net_file = "{}/deploy.prototxt".format(save_dir)
solver_file = "{}/solver.prototxt".format(save_dir)
# snapshot prefix.
snapshot_prefix = "{}/{}".format(snapshot_dir, model_name)
# job script path.
job_file = "{}/{}.sh".format(job_dir, model_name)
# Stores the test image names and sizes. Created by data/VOC0712/create_list.sh
name_size_file = "data/VOC0712/test_name_size.txt" #上述生成的test_name_size.txt位置,最后用绝对路径
# The pretrained model. We use the Fully convolutional reduced (atrous) VGGNet.
pretrain_model = "models/VGGNet/VGG_ILSVRC_16_layers_fc_reduced.caffemodel" #预训练模型,会很大程度减少自己项目的训练时间
# Stores LabelMapItem.
label_map_file = "data/VOC0712/labelmap_voc.prototxt" #上述生成的labelmap_voc.prototxt位置,最后用绝对路径
# MultiBoxLoss parameters.
num_classes = 21 #该位置要换成你自己项目的物体类别个数,别忘了要加上背景
share_location = True
background_label_id=0
train_on_diff_gt = True
normalization_mode = P.Loss.VALID
code_type = P.PriorBox.CENTER_SIZE
ignore_cross_boundary_bbox = False
mining_type = P.MultiBoxLoss.MAX_NEGATIVE
neg_pos_ratio = 3.
loc_weight = (neg_pos_ratio + 1.) / 4.
multibox_loss_param = {
'loc_loss_type': P.MultiBoxLoss.SMOOTH_L1,
'conf_loss_type': P.MultiBoxLoss.SOFTMAX,
'loc_weight': loc_weight,
'num_classes': num_classes,
'share_location': share_location,
'match_type': P.MultiBoxLoss.PER_PREDICTION,
'overlap_threshold': 0.5,
'use_prior_for_matching': True,
'background_label_id': background_label_id,
'use_difficult_gt': train_on_diff_gt,
'mining_type': mining_type,
'neg_pos_ratio': neg_pos_ratio,
'neg_overlap': 0.5,
'code_type': code_type,
'ignore_cross_boundary_bbox': ignore_cross_boundary_bbox,
}
loss_param = {
'normalization': normalization_mode,
}
# parameters for generating priors.
# minimum dimension of input image
min_dim = 300
# conv4_3 ==> 38 x 38
# fc7 ==> 19 x 19
# conv6_2 ==> 10 x 10
# conv7_2 ==> 5 x 5
# conv8_2 ==> 3 x 3
# conv9_2 ==> 1 x 1
mbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2']
# in percent %
min_ratio = 20
max_ratio = 90
step = int(math.floor((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))
min_sizes = []
max_sizes = []
for ratio in xrange(min_ratio, max_ratio + 1, step):
min_sizes.append(min_dim * ratio / 100.)
max_sizes.append(min_dim * (ratio + step) / 100.)
min_sizes = [min_dim * 10 / 100.] + min_sizes
max_sizes = [min_dim * 20 / 100.] + max_sizes
steps = [8, 16, 32, 64, 100, 300]
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]]
# L2 normalize conv4_3.
normalizations = [20, -1, -1, -1, -1, -1]
# variance used to encode/decode prior bboxes.
if code_type == P.PriorBox.CENTER_SIZE:
prior_variance = [0.1, 0.1, 0.2, 0.2]
else:
prior_variance = [0.1]
flip = True
clip = False
# Solver parameters.
# Defining which GPUs to use.
gpus = "0,1,2,3"
gpulist = gpus.split(",")
num_gpus = len(gpulist)
# Divide the mini-batch to different GPUs.
batch_size = 32 #批次训练大小,基于你自己机器的性能调节
accum_batch_size = 32
iter_size = accum_batch_size / batch_size
solver_mode = P.Solver.CPU
device_id = 0 #你的机器有几个GPU,这里就设置几
batch_size_per_device = batch_size
if num_gpus > 0:
batch_size_per_device = int(math.ceil(float(batch_size) / num_gpus))
iter_size = int(math.ceil(float(accum_batch_size) / (batch_size_per_device * num_gpus)))
solver_mode = P.Solver.GPU
device_id = int(gpulist[0])
if normalization_mode == P.Loss.NONE:
base_lr /= batch_size_per_device
elif normalization_mode == P.Loss.VALID:
base_lr *= 25. / loc_weight
elif normalization_mode == P.Loss.FULL:
# Roughly there are 2000 prior bboxes per image.
# TODO(weiliu89): Estimate the exact # of priors.
base_lr *= 2000.
# Evaluate on whole test set.
num_test_image = 4952 #这个数字要与上述生成的test_name_size.txt的行数保持一致,及测试集一共多少张图片
test_batch_size = 8
# Ideally test_batch_size should be divisible by num_test_image,
# otherwise mAP will be slightly off the true value.
test_iter = int(math.ceil(float(num_test_image) / test_batch_size))
solver_param = {
# Train parameters
'base_lr': base_lr,
'weight_decay': 0.0005,
'lr_policy': "multistep",
'stepvalue': [80000, 100000, 120000],
'gamma': 0.1,
'momentum': 0.9,
'iter_size': iter_size,
'max_iter': 120000,
'snapshot': 80000,
'display': 10,
'average_loss': 10,
'type': "SGD",
'solver_mode': solver_mode,
'device_id': device_id,
'debug_info': False,
'snapshot_after_train': True,
# Test parameters
'test_iter': [test_iter],
'test_interval': 10000,
'eval_type': "detection",
'ap_version': "11point",
'test_initialization': False,
}
# parameters for generating detection output.
det_out_param = {
'num_classes': num_classes,
'share_location': share_location,
'background_label_id': background_label_id,
'nms_param': {'nms_threshold': 0.45, 'top_k': 400},
'save_output_param': {
'output_directory': output_result_dir,
'output_name_prefix': "comp4_det_test_",
'output_format': "VOC",
'label_map_file': label_map_file,
'name_size_file': name_size_file,
'num_test_image': num_test_image,
},
'keep_top_k': 200,
'confidence_threshold': 0.01,
'code_type': code_type,
}
# parameters for evaluating detection results.
det_eval_param = {
'num_classes': num_classes,
'background_label_id': background_label_id,
'overlap_threshold': 0.5,
'evaluate_difficult_gt': False,
'name_size_file': name_size_file,
}
### Hopefully you don't need to change the following ###
# Check file.
check_if_exist(train_data)
check_if_exist(test_data)
check_if_exist(label_map_file)
check_if_exist(pretrain_model)
make_if_not_exist(save_dir)
make_if_not_exist(job_dir)
make_if_not_exist(snapshot_dir)
# Create train net.
net = caffe.NetSpec()
net.data, net.label = CreateAnnotatedDataLayer(train_data, batch_size=batch_size_per_device,
train=True, output_label=True, label_map_file=label_map_file,
transform_param=train_transform_param, batch_sampler=batch_sampler)
VGGNetBody(net, from_layer='data', fully_conv=True, reduced=True, dilated=True,
dropout=False)
AddExtraLayers(net, use_batchnorm, lr_mult=lr_mult)
mbox_layers = CreateMultiBoxHead(net, data_layer='data', from_layers=mbox_source_layers,
use_batchnorm=use_batchnorm, min_sizes=min_sizes, max_sizes=max_sizes,
aspect_ratios=aspect_ratios, steps=steps, normalizations=normalizations,
num_classes=num_classes, share_location=share_location, flip=flip, clip=clip,
prior_variance=prior_variance, kernel_size=3, pad=1, lr_mult=lr_mult)
# Create the MultiBoxLossLayer.
name = "mbox_loss"
mbox_layers.append(net.label)
net[name] = L.MultiBoxLoss(*mbox_layers, multibox_loss_param=multibox_loss_param,
loss_param=loss_param, include=dict(phase=caffe_pb2.Phase.Value('TRAIN')),
propagate_down=[True, True, False, False])
with open(train_net_file, 'w') as f:
print('name: "{}_train"'.format(model_name), file=f)
print(net.to_proto(), file=f)
shutil.copy(train_net_file, job_dir)
# Create test net.
net = caffe.NetSpec()
net.data, net.label = CreateAnnotatedDataLayer(test_data, batch_size=test_batch_size,
train=False, output_label=True, label_map_file=label_map_file,
transform_param=test_transform_param)
VGGNetBody(net, from_layer='data', fully_conv=True, reduced=True, dilated=True,
dropout=False)
AddExtraLayers(net, use_batchnorm, lr_mult=lr_mult)
mbox_layers = CreateMultiBoxHead(net, data_layer='data', from_layers=mbox_source_layers,
use_batchnorm=use_batchnorm, min_sizes=min_sizes, max_sizes=max_sizes,
aspect_ratios=aspect_ratios, steps=steps, normalizations=normalizations,
num_classes=num_classes, share_location=share_location, flip=flip, clip=clip,
prior_variance=prior_variance, kernel_size=3, pad=1, lr_mult=lr_mult)
conf_name = "mbox_conf"
if multibox_loss_param["conf_loss_type"] == P.MultiBoxLoss.SOFTMAX:
reshape_name = "{}_reshape".format(conf_name)
net[reshape_name] = L.Reshape(net[conf_name], shape=dict(dim=[0, -1, num_classes]))
softmax_name = "{}_softmax".format(conf_name)
net[softmax_name] = L.Softmax(net[reshape_name], axis=2)
flatten_name = "{}_flatten".format(conf_name)
net[flatten_name] = L.Flatten(net[softmax_name], axis=1)
mbox_layers[1] = net[flatten_name]
elif multibox_loss_param["conf_loss_type"] == P.MultiBoxLoss.LOGISTIC:
sigmoid_name = "{}_sigmoid".format(conf_name)
net[sigmoid_name] = L.Sigmoid(net[conf_name])
mbox_layers[1] = net[sigmoid_name]
net.detection_out = L.DetectionOutput(*mbox_layers,
detection_output_param=det_out_param,
include=dict(phase=caffe_pb2.Phase.Value('TEST')))
net.detection_eval = L.DetectionEvaluate(net.detection_out, net.label,
detection_evaluate_param=det_eval_param,
include=dict(phase=caffe_pb2.Phase.Value('TEST')))
with open(test_net_file, 'w') as f:
print('name: "{}_test"'.format(model_name), file=f)
print(net.to_proto(), file=f)
shutil.copy(test_net_file, job_dir)
# Create deploy net.
# Remove the first and last layer from test net.
deploy_net = net
with open(deploy_net_file, 'w') as f:
net_param = deploy_net.to_proto()
# Remove the first (AnnotatedData) and last (DetectionEvaluate) layer from test net.
del net_param.layer[0]
del net_param.layer[-1]
net_param.name = '{}_deploy'.format(model_name)
net_param.input.extend(['data'])
net_param.input_shape.extend([
caffe_pb2.BlobShape(dim=[1, 3, resize_height, resize_width])])
print(net_param, file=f)
shutil.copy(deploy_net_file, job_dir)
# Create solver.
solver = caffe_pb2.SolverParameter(
train_net=train_net_file,
test_net=[test_net_file],
snapshot_prefix=snapshot_prefix,
**solver_param)
with open(solver_file, 'w') as f:
print(solver, file=f)
shutil.copy(solver_file, job_dir)
max_iter = 0
# Find most recent snapshot.
for file in os.listdir(snapshot_dir):
if file.endswith(".solverstate"):
basename = os.path.splitext(file)[0]
iter = int(basename.split("{}_iter_".format(model_name))[1])
if iter > max_iter:
max_iter = iter
train_src_param = '--weights="{}" \\\n'.format(pretrain_model)
if resume_training:
if max_iter > 0:
train_src_param = '--snapshot="{}_iter_{}.solverstate" \\\n'.format(snapshot_prefix, max_iter)
if remove_old_models:
# Remove any snapshots smaller than max_iter.
for file in os.listdir(snapshot_dir):
if file.endswith(".solverstate"):
basename = os.path.splitext(file)[0]
iter = int(basename.split("{}_iter_".format(model_name))[1])
if max_iter > iter:
os.remove("{}/{}".format(snapshot_dir, file))
if file.endswith(".caffemodel"):
basename = os.path.splitext(file)[0]
iter = int(basename.split("{}_iter_".format(model_name))[1])
if max_iter > iter:
os.remove("{}/{}".format(snapshot_dir, file))
# Create job file.
with open(job_file, 'w') as f:
f.write('cd {}\n'.format(caffe_root))
f.write('./build/tools/caffe train \\\n')
f.write('--solver="{}" \\\n'.format(solver_file))
f.write(train_src_param)
if solver_param['solver_mode'] == P.Solver.GPU:
f.write('--gpu {} 2>&1 | tee {}/{}.log\n'.format(gpus, job_dir, model_name))
else:
f.write('2>&1 | tee {}/{}.log\n'.format(job_dir, model_name))
# Copy the python script to job_dir.
py_file = os.path.abspath(__file__)
shutil.copy(py_file, job_dir)
# Run the job.
os.chmod(job_file, stat.S_IRWXU)
if run_soon:
subprocess.call(job_file, shell=True)
预训练模型文件下载地址:VGG_ILSVRC_16_layers_fc_reduced.caffemodel
注意点:
在脚本中能用绝对路径就用绝对路径,不然各种相对路径能让你心态爆炸!
四、测试模型
找到you_caffe_root/example/ssd/ssd_detect.py
#encoding=utf8
'''
Detection with SSD
In this example, we will load a SSD model and use it to detect objects.
'''
import os
import sys
import argparse
import numpy as np
from PIL import Image, ImageDraw
# Make sure that caffe is on the python path:
caffe_root = './'
os.chdir(caffe_root)
sys.path.insert(0, os.path.join(caffe_root, 'python'))
import caffe
from google.protobuf import text_format
from caffe.proto import caffe_pb2
def get_labelname(labelmap, labels):
num_labels = len(labelmap.item)
labelnames = []
if type(labels) is not list:
labels = [labels]
for label in labels:
found = False
for i in xrange(0, num_labels):
if label == labelmap.item[i].label:
found = True
labelnames.append(labelmap.item[i].display_name)
break
assert found == True
return labelnames
class CaffeDetection:
def __init__(self, gpu_id, model_def, model_weights, image_resize, labelmap_file):
caffe.set_device(gpu_id)
caffe.set_mode_gpu()
self.image_resize = image_resize
# Load the net in the test phase for inference, and configure input preprocessing.
self.net = caffe.Net(model_def, # defines the structure of the model
model_weights, # contains the trained weights
caffe.TEST) # use test mode (e.g., don't perform dropout)
# input preprocessing: 'data' is the name of the input blob == net.inputs[0]
self.transformer = caffe.io.Transformer({'data': self.net.blobs['data'].data.shape})
self.transformer.set_transpose('data', (2, 0, 1))
self.transformer.set_mean('data', np.array([104, 117, 123])) # mean pixel
# the reference model operates on images in [0,255] range instead of [0,1]
self.transformer.set_raw_scale('data', 255)
# the reference model has channels in BGR order instead of RGB
self.transformer.set_channel_swap('data', (2, 1, 0))
# load PASCAL VOC labels
file = open(labelmap_file, 'r')
self.labelmap = caffe_pb2.LabelMap()
text_format.Merge(str(file.read()), self.labelmap)
def detect(self, image_file, conf_thresh=0.5, topn=5):
'''
SSD detection
'''
# set net to batch size of 1
# image_resize = 300
self.net.blobs['data'].reshape(1, 3, self.image_resize, self.image_resize)
image = caffe.io.load_image(image_file)
#Run the net and examine the top_k results
transformed_image = self.transformer.preprocess('data', image)
self.net.blobs['data'].data[...] = transformed_image
# Forward pass.
detections = self.net.forward()['detection_out']
# Parse the outputs.
det_label = detections[0,0,:,1]
det_conf = detections[0,0,:,2]
det_xmin = detections[0,0,:,3]
det_ymin = detections[0,0,:,4]
det_xmax = detections[0,0,:,5]
det_ymax = detections[0,0,:,6]
# Get detections with confidence higher than 0.6.
top_indices = [i for i, conf in enumerate(det_conf) if conf >= conf_thresh]
top_conf = det_conf[top_indices]
top_label_indices = det_label[top_indices].tolist()
top_labels = get_labelname(self.labelmap, top_label_indices)
top_xmin = det_xmin[top_indices]
top_ymin = det_ymin[top_indices]
top_xmax = det_xmax[top_indices]
top_ymax = det_ymax[top_indices]
result = []
for i in xrange(min(topn, top_conf.shape[0])):
xmin = top_xmin[i] # xmin = int(round(top_xmin[i] * image.shape[1]))
ymin = top_ymin[i] # ymin = int(round(top_ymin[i] * image.shape[0]))
xmax = top_xmax[i] # xmax = int(round(top_xmax[i] * image.shape[1]))
ymax = top_ymax[i] # ymax = int(round(top_ymax[i] * image.shape[0]))
score = top_conf[i]
label = int(top_label_indices[i])
label_name = top_labels[i]
result.append([xmin, ymin, xmax, ymax, label, score, label_name])
return result
def main(args):
'''main '''
detection = CaffeDetection(args.gpu_id,
args.model_def, args.model_weights,
args.image_resize, args.labelmap_file)
result = detection.detect(args.image_file)
print result
img = Image.open(args.image_file)
draw = ImageDraw.Draw(img)
width, height = img.size
print width, height
for item in result:
xmin = int(round(item[0] * width))
ymin = int(round(item[1] * height))
xmax = int(round(item[2] * width))
ymax = int(round(item[3] * height))
draw.rectangle([xmin, ymin, xmax, ymax], outline=(255, 0, 0))
draw.text([xmin, ymin], item[-1] + str(item[-2]), (0, 0, 255))
print item
print [xmin, ymin, xmax, ymax]
print [xmin, ymin], item[-1]
img.save('detect_result.jpg')
def parse_args():
'''parse args'''
parser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=int, default=0, help='gpu id')
parser.add_argument('--labelmap_file',
default='data/VOC0712/labelmap_voc.prototxt') #上述生成的labelmap_voc.prototxt位置
parser.add_argument('--model_def',
default='models/VGGNet/VOC0712/SSD_300x300/deploy.prototxt') #训练阶段生成的测试prototxt文件路径
parser.add_argument('--image_resize', default=300, type=int) #测试图片大小要与训练一致
parser.add_argument('--model_weights',
default='models/VGGNet/VOC0712/SSD_300x300/'
'VGG_VOC0712_SSD_300x300_iter_120000.caffemodel') #训练阶段生成的caffemodel路径
parser.add_argument('--image_file', default='examples/images/fish-bike.jpg') #要测试图片的路径
return parser.parse_args()
if __name__ == '__main__':
main(parse_args())
https://blog.csdn.net/chenlufei_i/article/details/80068953
https://blog.csdn.net/weixin_30613343/article/details/96541315