MobileViT 它来了!Apple 提出轻量、通用、适用于移动设备的Transformer!
关注公众号,发现CV技术之美
本文分享论文『MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer』,由苹果公司提出《MobileViT》,轻量、通用、适用于移动设备的Transformer!
详细信息如下:

论文链接:https://arxiv.org/abs/2110.02178
复现代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch
导言:
轻量级的卷积神经网络在移动视觉任务中非常有用,它们的空间归纳偏置允许它们在不同的视觉任务中以较少的参数学习表征。然而,这些网络在空间上是局部建模的。如果想要学习全局表征,可以采用基于自注意的视觉Transformer(ViT)。但是与CNN不同,ViT是的参数量比较大。
在本文中,作者提出了这样一个问题问题:是否有可能结合CNN和ViTs的优势,为移动视觉任务构建一个轻量级、低延迟的网络?为此,作者提出了MobileViT,一种用于移动设备的轻量级通用视觉Transformer。
实验结果表明,MobileViT在不同的任务和数据集上显著优于基于CNN和ViT的网络。在ImageNet-1k数据集上,MobileViT实现了78.4%的Top-1精度,拥有约600万个参数,对于类似数量的参数,其精度分别比MobileNetv3(基于CNN)和DeIT(基于ViT)高3.2%和6.2%。在MS-COCO目标检测任务中,对于相同数量的参数,MobileViT比MobileNetv3的准确度高5.7%。
01
Motivation

基于自注意的模型(如上图所示),目前已经成为了卷积神经网络(CNN)学习视觉表征的替代方案。简单地说,ViT将图像分成一系列不重叠的patch,然后利用Transformer中的多头自注意学习patch之间的表示。
然而,这些ViT模型性能的改进是以网络参数和推理速度为代价的。许多现实的应用需要视觉识别任务(如目标检测和语义分割)在资源受限的移动设备上实时运行。因此,用于这类任务的ViT模型应该是轻量级和低延迟的。然而,即使减小ViT模型的大小以匹配移动设备的资源约束,其性能也明显低于轻量级CNN。因此,设计轻量级的ViT模型势在必行。
轻量级CNN促进了许多移动端的视觉任务发展,但ViT网络目前还是很难部署在移动设备上。与轻量级CNN不同,ViT更加庞大,并且更难优化,因此需要大量的数据增强和L2正则化以防止过拟合。
例如,基于ViT的分割网络学习了约3.45亿个参数,但是只取得了与基于CNN的网络DeepLabv3 (5900万个参数)相似的性能。为了建立鲁棒和高性能的ViT模型,一些工作开始同时结合卷积和Transformer,创建新的网络。然而,这些混合模型仍然很大,并且对数据增强很敏感。
目前,结合CNN和Transformer的优势,为移动视觉任务构建ViT模型仍然是一个悬而未决的问题。移动视觉任务需要轻量、低延迟和精确的模型,以满足设备的资源限制,并且是通用的,因此它们可以应用于不同的任务(例如,分割和检测)。此外,只优化浮点操作(FLOPs)不足以在移动设备上实现低延迟,因为FLOPs忽略了几个重要的相关因素,如内存访问、并行度和平台特性。
因此,本文的重点不是只针对FLOPs进行优化,而是为移动视觉任务设计轻量级 、通用性和低延迟的网络。作者通过MobileViT实现了这一目标,它结合了CNN(例如,空间归纳偏置和对数据增强的较低敏感性)和ViT(例如,输入自适应加权和全局处理)的优点。
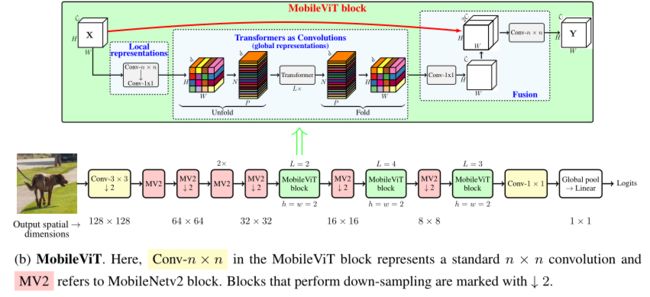
具体来说,MobileViT引入了MobileViT块(如上图所示),它可以有效地将局部和全局信息进行编码。与ViT及其变体不同,MobileViT从不同的角度学习全局表示。标准卷积涉及三个操作:展开(unfloading)、局部处理(local processing)和展开(folding)。MobileViT块使用Transformer将卷积中的局部建模替换为全局建模。这使得MobileViT块具有CNN和ViT的性质,有助于它用更少的参数和简单的训练方式学习更好的表示。
02
方法
对于ViT模型来说,首先将输入reshape为一系列patch,然后将其投影到固定的维度空间中得到,然后使用一组Transformer块学习patch间的表示,其中Self-Attention的计算复杂度为。
C、H和W分别表示张量的通道、高度和宽度,P=wh为patch中的像素数,N为patch数。由于这些模型忽略了CNN固有的空间归纳偏置,因此需要更多的参数来学习视觉表征。此外,与CNN相比,这些模型的优化能力更弱,需要大量的数据增强以防止过度拟合。
为了克服上面的缺点,本文提出了一种轻量级ViT模型——MobileViT,其核心思想是用Transformer作为卷积来学习全局表示。
2.1. MobileViT
MobileViT block

MobileViT块的结构如上图所示,可以用较少的参数在输入张量中建模局部和全局信息。对于输入的张量,MobileViT块首先用n×n和1×1卷积对输入进行操作,得到。其中n×n卷积用于学习局部的空间信息,1×1卷积用于将输入特征投影到高维空间。
为了获取更长距离的关系,有一种方法是利用空洞卷积(dilated convolution)进行建模。然而,这种方法需要仔细选择扩张率(dilation rate)。另一个解决方案是自注意力,具有多头自注意的视觉Transformer(ViT)被证明对视觉识别任务是有效的。然而,ViT的参数量很大,并且优化能力较弱,因为ViT缺少归纳偏置。
为了使MobileViT能够学习具有空间归纳偏置的全局表示,作者首先将展开为N个不重叠的patch 。其中,,为patch的数量,,为patch的高和宽。跨patch中的每个像素通过Transformer来进行建模,得到:
![]()

与丢失像素空间顺序的ViT不同,MobileViT既不会丢失patch顺序,也不会丢失每个patch内像素的空间顺序,如上图所示。因此,作者折叠了来获得,然后被用1x1的卷积得到C维的特征。然后nxn的卷积用于融合局部和全局特征。
由于使用卷积对n×n区域的局部信息进行编码,而对P个patch中的第p个位置的全局信息进行编码,因此可以对中的全局信息进行感知。因此,MobileViT块的整体有效感受野为H×W,也就是一个全局感知的操作。
Relationship to convolutions
标准卷积可以看作是三个连续操作的堆叠:(1)展开(2)矩阵乘法(学习局部表示)和(3)折叠。MobileViT块与卷积相似,因为它也利用相同的构建块。MobileViT块用更深的全局处理(Transformer层的堆叠)取代卷积中的局部处理(矩阵乘法)。因此,MobileViT具有类似卷积的特性(例如,空间的归纳偏置)。因此,MobileViT块在某种程度上也可以看作是卷积。
Light-weight
MobileViT块使用标准卷积和Transformer分别学习局部和全局表示。由于之前的工作表明,使用这些层设计的网络参数量和计算量都很大,因此自然会产生一个问题:为什么MobileViT是轻量级的?
主要的原因在于,在以前的工作中,通常是将patch进行投影,然后用Transformer学习patch之间的全局信息,这就丢失了图像的归纳偏置,因此这些模型需要更多的参数来进行学习,也就导致这些模型又深又宽。而MobileViT使用卷积和Transformer,使得MobileViT块既具有卷积的性质,又能进行全局的建模。这使得MobileViT的设计可以使轻量级的,可以用更少的通道数和更浅的网络实现更好的性能。
Computational cost
在MobileViT和ViT中,多头自注意的计算成本分别为和。理论上,与ViT相比,MobileViT效率较低。然而,在实践中,MobileViT比ViT效率更高。
MobileViT architecture
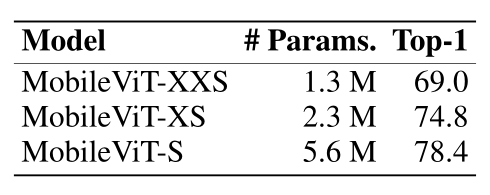
基于上面的设计思想,作者提出了三种不同的MobileViT 实例化,如上表所示。

上图显示了不同实例化模型参数的分布。
2.2. Multi-Scale Sampler For Training Efficiency
在基于ViT的模型中,学习多尺度表示的标准方法是微调。ViT的学习多尺度表示的位置嵌入需要基于输入大小进行插值,并且网络的性能取决于插值方法。与CNN类似,MobileViT不需要任何位置嵌入,并且可以在训练期间受益于多尺度输入。
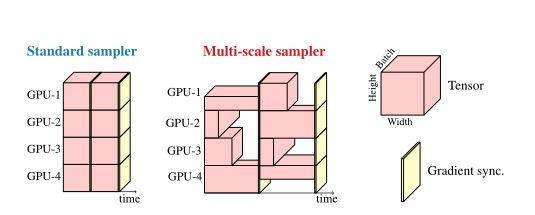
先前基于CNN的工作表明多尺度训练是有效的。然而,这些工作中的大多数都是在经过固定次数的迭代后获得新的空间分辨率。然而,这会导致GPU利用率不足、训练速度较慢,因为所有分辨率都使用相同的batch大小。
为了便于MobileViT在不进行微调的情况下学习多尺度表示,并进一步提高训练效率,作者将多尺度训练方法扩展到可变大小的batch大小。给定一组排序的空间分辨率和一个batch大小,最大空间分辨率为,然后在第每个GPU第t次迭代中随机抽样一个空间分辨率, 并将第t次迭代的batch大小计算为:。
因此,较大的batch大小用于较小的空间分辨率。这就减少了迭代的次数,提高了GPU的利用率,有助于更快的训练。下图展示了多尺度采样训练的示意图:
多尺度采样的pytorch代码如下:

03
实验
3.1. Image Classification
Comparison with CNN

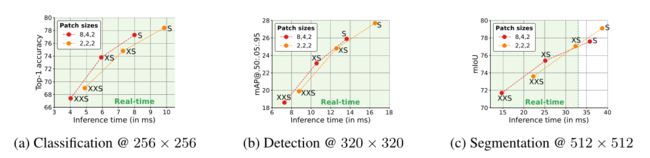
上图展示了本文方法和其他轻量级CNN网络的对比,可以看出本文方法的优越性。

上表对比了本文方法和其他轻量级网络在相似参数量下的性能对比,可以看出,本文方法具有更高的性能。

上表展示了本文方法和 heavy-weight CNN的对比,可以看出,本文方法可以用更少的参数,达到更高的准确率。
Comparison with ViT
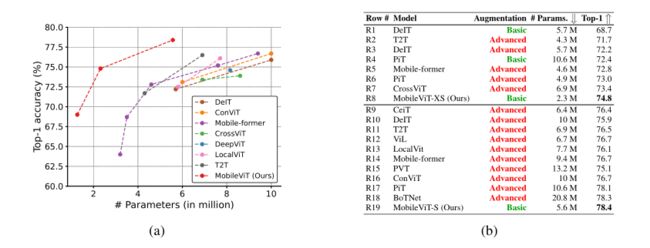
上图对比了本文方法和ViT结构的的参数量和性能,可以看出,本文可以用更少的参数、更简单的数据增强,达到更高的性能。
3.2. Object Detection
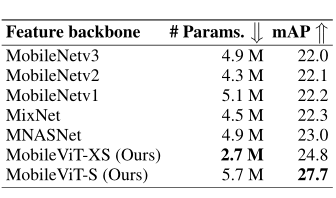
上表展示了目标检测任务上,不同轻量级网络的作为Backbone时的性能对比,可以看出MobileViT性能远超其他模型。
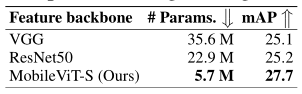
上表展示了目标检测任务上,本文方法和 heavy-weight CNN的作为Backbone时的性能对比,可以看出,MobileViT在参数量更少的情况下,性能远超其他模型。
3.3. Semantic Segmantation

上表展示了语义分割任务上,基于不同主干网络的DeepLabv3性能和参数对比,可以看出,本文的方法在各种轻量级网络中,能够达到更高的性能。
3.4. Performance on Mobile Device
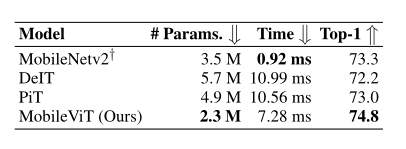
上表展示了 iPhone 12上,本文提出的MobileViT的推理时间和性能对比,可以看出本文的方法对于移动设备是非常友好的。
从上表可以看出,本文的方法在移动设备上的推理速度明显优于各种ViT结构。
04
总结
在本文中,作者提出了MobileViT,这个网络同时具备了卷积和Transformer结构,因此具备Transformer全局建模的能力,也具备CNN的归纳偏置。因此,它不需要有ViT那么多参数,也不需要特别复杂的数据增强的方法来训练,因此,本文提出的ViT结构是真正对于移动设备友好的,并且参数量和计算量也非常小。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
加入「Transformer」交流群备注:TFM
