机器学习入门:主题模型-4
机器学习入门:主题模型
1、实验描述
- 本实验是关于主题模型LDA的,首先介绍了LDA的应用方面有哪些?然后通过以python编程方式调用LDA相关的API,实现对LDA自带数据集的文档主题的分析,并将最终结果可视化。
- 实验时长:45分钟
- 主要步骤:
- 导入实验相关的包
- 加载lda数据集
- 观察数据样本
- 利用特定的样本做测试
- 创建LDA模型
- 分析文档的主题分布
- 计算对应主题的TOP N单词
- 结果展示
2、实验环境
- 虚拟机数量:1
- 系统版本:CentOS 7.5
- LDA版本:1.0.5
- scikit-learn版本: 0.19.2
- numpy版本:1.15.1
- matplotlib版本:2.2.3
- python版本:3.5
- IPython版本:6.5.0
3、相关技能
- Python编程
- Numpy编程
- LDA 模型的使用
- Matplotlib绘图
4、相关知识点
- conda 虚拟环境
- LDA API
- matplotlib 绘图
5、实现效果
- 给定编号的文档最有可能属于某个主题的概率效果示意图如下:

6、实验步骤
6.1主题模型介绍:
6.1.1涉及的主要问题有:共轭先验分布、Dirichlet分布、LDA模型、Gibbs采样算法学习参数
6.1.2举例:共有m篇文章,一共涉及K个主题;每篇文章(长度为Nm)都有各自的主题分布,主题分布是多项分布,该多项分布的参数服从Dirichlet分布,该Dirichlet分布的参数为α;每个主题都有各自的词分布,词分布为多项分布,该多项分布的参数服从Dirichlet分布,该Dirichlet分布的参数为β;对于某篇文章中的第n个词,首先从该文章的主题分布中采样一个主题,然后在这个主题对应的词分布中采样一个词。不断重复这个随机生成过程,直到m篇文章全部完成上述过程。
6.1.3应用方向:信息提取和搜索、语义分析、文档分类/聚类、文章摘要、社区挖掘、基于内容的图像聚类、目标识别、以及其他计算机视觉应用、生物信息数据的应用
6.1.4由于在词和文档之间加入的主题的概念,可以较好的解决一词多义和多词一义的问题。在实践中发现,LDA用于短文档往往效果不明显:因为一个词被分配给某个主题的次数和一个主题包括的词数目尚未敛。往往需要“连接”成长文档。
6.2进入Anaconda创建的虚拟环境“ML”
6.2.1在zkpk的家目录下执行如下命令
[zkpk@master ~]$ cd
[zkpk@master ~]$ source activate ML
(ML) [zkpk@ master ML]$
6.2.2此时已进入虚拟环境。键入如下命令,进入ipython交互式编程环境
(ML) [zkpk@ master ML]$ ipython
Python 3.5.4 |Anaconda, Inc.| (default, Nov 3 2017, 20:01:27)
Type 'copyright', 'credits' or 'license' for more information
IPython 6.2.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
6.3在Ipython交互式编程环境中开始进行实验
6.3.1导入实验所需的包
In [1]: import numpy as np
...: import lda
...: import lda.datasets
...: import matplotlib.pyplot as plt
...:
6.3.2加载自带数据集
In [2]: X = lda.datasets.load_reuters() #X为输入矩阵,共395个文档,4258个单词,
6.3.2.1打印数据的类型
In [3]: print("type(X): {}".format(type(X)))

6.3.2.2打印输入矩阵的shape
In [4]: print("shape: {}\n".format(X.shape)) # 矩阵大小395*4258

6.3.2.3打印前几个样本
In [5]: print(X[:5, :5])

6.3.2.4观察相应的词汇
In [6]: vocab = lda.datasets.load_reuters_vocab() # vocab为具体的单词,共4258个,
...: #它对应X的一行数据
...: print("type(vocab): {}".format(type(vocab)))
...: print("len(vocab): {}\n".format(len(vocab)))
...: print(vocab[:5])
# 输出的前5个单词,X中第0列对应church,其值为词频

6.3.2.5观察相应的title
In [7]: titles = lda.datasets.load_reuters_titles() # 文章标题,共395篇文#章
...: print("type(titles): {}".format(type(titles)))
...: print("len(titles): {}\n".format(len(titles)))
...: print(titles[:5]) #输出0~4篇文章标题如下

6.3.3利用指定的样本进行测试
6.3.3.1指定对应的文档、单词
In [8]: doc_id, word_id = 23, 2324
6.3.3.2查看对应的单词的词频
In [9]: X[doc_id,word_id]
![]()
6.3.3.3查看对应的单词内容
In [10]: vocab[word_id]
![]()
6.3.3.4查看对应的文档标题
In [11]: titles[doc_id]

6.4创建LDA模型,对输入数据进行训练
6.4.1建立模型, 指定主题个数为20, 迭代次数为500
In [12]: model = lda.LDA(n_topics=20, n_iter=500, random_state=1)
6.4.2训练数据
In [13]: model.fit_transform(X)
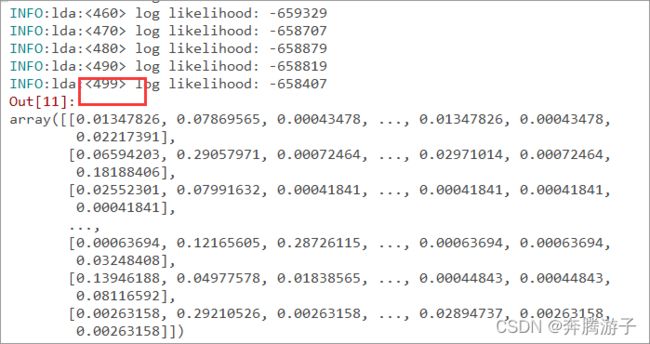
6.4.3计算前三个单词在指定的主题中的比重
In [15]: topic_word = model.topic_word_ # 获取模型的主题及对应单词
...: print("type(topic_word): {}".format(type(topic_word))) # 打开topic_word类型
...: print("shape: {}".format(topic_word.shape)) # 查看topic_word的shape
...: print(vocab[:3]) #获取前三个词,'church', 'pope', 'years'三个单词
...: print(topic_word[:, :3])

6.4.4输出top N 主题的比重,均值为1
In [16]: for n in range(5):
...: sum_pr = sum(topic_word[n, :])
...: print("topic: {} sum: {}".format(n, sum_pr))

6.4.5计算各个主题对应的top -N 单词
In [17]:
...: n = 5 # 这里n设置为5
...: for i, topic_dist in enumerate(topic_word):
...: topic_words = np.array(vocab)[np.argsort(topic_dist)][:-(n+1):-1] # vocab为4258个词汇;topic_dist中保存着第i个主题的,4258个词汇的与此主题关联的几率;argsort返回数据值从小到大排列后,对应的索引;
...: print('*Topic {}\n- {}'.format(i, ' '.join(topic_words)))

6.4.6计算20~23 对应的文章最有可能的主题
In [18]: doc_topic = model.doc_topic_
...: print("type(doc_topic): {}".format(type(doc_topic)))
...: print("shape: {}".format(doc_topic.shape))
...: for n in range(20,24):
...: topic_most_pr = doc_topic[n].argmax() # argmax()返回最大值的索引
...: print("doc: {} topic: {}".format(n, topic_most_pr))
...:

6.5输出给定的文档最有可能属于某个主题的概率图示效果
f, ax =plt.subplots(5,1,figsize=(8,6), sharex=True) # 前两个参数,5和1,说明创建一个figure画布对象,其中包括5个子图,figure中共5行、1列;sharex参数表示5个子图共享x轴;f用于接收figure对象;ax用于接收5个子图
for i, k in enumerate([1,3,4,8,9]): # 1,3,4,8,9分别对应文档的编号
ax[i].stem(doc_topic[k,:], linefmt = 'r-',markerfmt='ro', basefmt='w-') # stem画出的是离散图,杆图;
ax[i].set_xlim(-1,21) # 设置x轴的范围
ax[i].set_ylim(0,1)
ax[i].set_ylabel('Prob')
ax[i].set_title("Document {}".format(k)) # 两次回车执行for循环
ax[4].set_xlabel("Topic")
plt.tight_layout()
plt.show()

图 15
7、参考答案
- 代码清单lda_code.py

8、总结
完成本次实验,可以基本了解LDA主题模型相关知识,包括模型的创建、训练、利用模型做分析等等;实验最后通过LDA模型分析了给定的文章最有可能属于哪个主题,并将结果做了pyplot的可视化。