语音降噪的Matlab实现
一.设计目的
本设计针对单麦克风语音降噪采用谱减法。谱减法的算法复杂度小、容易编程实现、处理速度快。本设计首先基于MATLAB实现了频谱相减算法,进行了仿真验证,计算降噪前后的信噪比并评估语音质量。
二.仿真实现步骤
(1)MATLAB读取一段.wav格式的纯净音频。可以调用audioread函数读取音频,采样频率默认为19.2kHz;
(2)对语音信号加Hamming窗,计算每帧信号的长度;
(3)纯净音频进行加噪处理。在MATLAB调用随机数函数产生高斯白噪声。为了得到信噪比为10dB的带噪语音,先计算原始语音功率和噪声功率。然后根据信噪比定义式,求出噪声的方差,噪声的方差除以噪声能量再开方,得到10dB的信噪比中对应的噪声能量。再加上纯净语音就得到带噪语音;
(4)计算每一帧的幅度谱和相位谱;
(5)调用谱减法程序,每一个窗口的每一帧信号的含噪功率减去噪声功率,对所有窗口的每一帧进行循环,直到最后一个窗口的最后一帧信号为止;
(6)把去噪语音的功率谱开平方,进行傅里叶逆变换;
(7)计算去噪语音的输出信噪比;
(8)分别作出去噪前后语音的时域波形图、频谱图,观察图像特点。同时MATLAB播放纯净语音和处理后的语音,听一下它们有哪些区别。
三.仿真结果与分析
本次设计使用音频的来源于中国科学院声学研究所的标准普通话测试材料,音频材料可以通过网络下载到。它是纯净语音,没有受到噪声的任何干扰。为了得到准确的实验结果,降低偶然性,要对音频截取其中5段,每段长度大约十三秒。截取好的音频文件放在电脑的同一个文件夹下。在MATLAB里分别读取每段音频,观察结果,比较5段音频输出增强语音的效果。现在以第一段测试音频为例,在10dB信噪比的环境下,分析MATLAB仿真的结果,然后比较所有的测试音频结果处理后的输出信噪比和语音质量。

图3-1 纯净语音时域波形
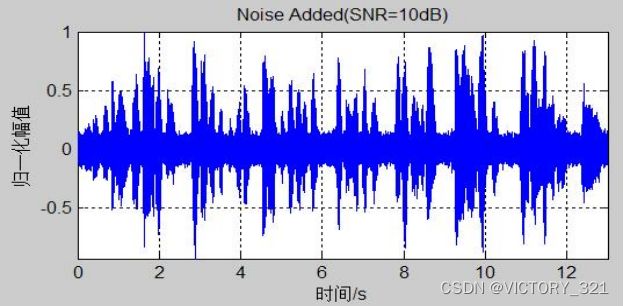
图3-2 加噪语音时域波形

图3-3 去噪后语音时域波形
接下来从频域观察一下去噪前后的效果。

图3-4 原始语音频谱图

图3-5 加噪语音频谱图

图3-6 去噪语音频谱图
在图3-4中,很明显看到语音信号的频率大约集中在200-3700Hz范围内,低频分量比较集中。在图3-5中,噪声的频谱从0到很高的频率范围内均匀分布。语音的高频成分淹没在噪声里。在图3-6中,可以明显观察到白噪声被滤除了很大一部分,但是存在一部分残留噪声
由于语音信号频率通常分布于300-3400Hz,所以可以设计一个带通滤波器,把语音的所有频率成分保留,把语音频率范围之外的残留噪声滤除。
设计滤波器通常是用MATLAB里自带的滤波器设计工具箱。本次实验设计IIR切比雪夫II型带通滤波器。它的过渡带非常陡峭。滤波器阶数为50阶,采样频率Fs=19200kHz。由于本次语音的频率范围大约在200-3700Hz,所以阻带截止频率1设置为170Hz,阻带截止频率2为3800Hz,阻带衰减为30dB。这样不仅保留了有效信号,而且很大程度上滤掉噪声。如图3-7所示。

图3-7 带通滤波器幅频特性
设计好带通滤波器后,调用filter函数对信号滤波,也就是让信号通过带通滤波器得到滤波后的输出。输出的图形分别如图3-8、3-9所示。

图3-8 滤波后的语音时域波形图

图3-9 滤波后的语音频域波形图
四.仿真代码
%clc;
clear; %初始化,清除命令窗口和工作空间的内容
close all; %关闭所有figure窗口
[speech,fs]=audioread('E:\测试音频1.wav');%读入wav音频文件,此时采样频率为fs=19.2KHz
size=length(speech); %语音信号长度
time=(0:size-1)/fs; %设置时间
winsize=512; %窗长, 窗长除以采样频率=窗长持续时间
j=sqrt(-1); %虚数单位
numofwin=floor(size/winsize);%窗数, floor(x)表示不超过(x)的最大整数
%定义汉明窗
ham=hamming(winsize)';%加汉明窗,实现对语音加窗、分帧处理
%初始化
hamwin=zeros(1,size); %加窗、分帧后的信号
enhanced=zeros(1,size);%语音增强处理后的信号
Ps=zeros(1,winsize); %增强语音功率谱
yframe=zeros(1,winsize);%分帧处理后的信号
%% 加噪
SNR=10; %输入信噪比10dB
noise1=randn(size,1);%产生和语音长度相同的噪声
sigal_power=sum(abs(speech).^2)/length(speech); %求出原信号功率
noise_power=sum(abs(noise1).^2)/length(noise1); %求出噪声功率
noise_variance=sigal_power/(10^(SNR/10)); %根据信噪比公式,计算出噪声设定的方差值
noise1=sqrt(noise_variance/noise_power)*noise1; %按噪声的平均能量构成相应的白噪声
%把噪声数据保存成.dat文件,
fid=fopen('noise1.dat','w'); %以写入的方式打开文件,fid为文件句柄,指定要写入数据的文件
fprintf(fid,'%0.4f\n',noise1); %将数据按四位小数格式写入到.dat文件中
fclose(fid); %关闭一个打开的fid的文件
fid1=fopen('noise1.dat','r'); %打开数据文件noise1.dat
noise=fscanf(fid1,'%g'); %读取文件数据到MATLAB,%g为自动识别控制符
y=speech+noise; %产生加噪语音y
%% 求输入信噪比
Psig=sum((speech).^2)/length(speech); %信号能量
Pnoise=sum((noise).^2)/length(noise); %噪声能量
SNR_in=10*log10(Psig/Pnoise); %由信噪比定义求出信噪比,单位为dB
Q=fft(speech); %原信号fft
N=fft(noise); %噪声fft
npow=abs(N); %噪声幅度谱
for q=1:2*numofwin-1
yframe=y(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2);%分帧
hamwin(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)=hamwin(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)+ham;
y1=fft(yframe'.*ham);%加噪信号FFT
ypow=abs(y1);%加噪信号幅度
yangle=angle(y1);%相位
Py=ypow.^2; %计算加噪信号功率
Pn=npow.^2; %计算噪声信号功率
%谱减法
for i=1:winsize
if (Py(i)-0.0045*Pn(i))>0
Ps(i)=Py(i)-0.0045*Pn(i);
else
Ps(i)=0.001* Py(i);
end
end
s=sqrt(Ps).*exp(j*yangle);%去噪语音频率响应
%去噪语音分帧,每帧求出IFFT
enhanced(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)=enhanced(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)+real(ifft(s));
end
%去除汉明窗引起的增益
for i=1:size
if hamwin(i)==0
enhanced(i)=0;
else
enhanced(i)=enhanced(i)/hamwin(i);
end
end
%% 设计带通滤波器
%滤除经过谱减后频率在170Hz-3800Hz之外的残留噪声
%利用Filter Design工具箱,设计IIR带通滤波器,Chebyshev Type2,Fs1=160Hz,Fs2=3800Hz,阶数50阶,阻带衰减40dB
speech1=filter(IIRBPF3,speech);
output=filter(IIRBPF3,enhanced);%滤波
[b,a]=tf(IIRBPF3); %把带通滤波器Hd转化成传输函数,系数为b,a
freqz(b,a,512,19200);%作IIR带通滤波器幅频特性曲线图
%% 计算输出信噪比
Pnoise2=sum((enhanced-speech').^2)/size;%增强语音里噪声的功率
Penhance=sum((enhanced).^2)/size;%求出增强语音功率
Pnoise3=sum((output-speech1').^2)/size;%低通滤波后噪声的功率
Poutput=sum((output).^2)/size;%求出低通滤波后的信号功率
SNR_out1=10*log10(Penhance/Pnoise2); %增强语音信噪比
SNR_out2=10*log10(Poutput/Pnoise3); %低通滤波后语音信噪比
snr1=SNR_out1-SNR_in; %增强语音信噪比-含噪语音信噪比
snr2=SNR_out2-SNR_in; %低通滤波后语音信噪比-含噪语音信噪比
fprintf('fs=%d\n',fs);
fprintf('SNR_in=%5.4f SNR_out1=%5.4f snr1=SNR_out1-SNR_in=%5.4f\n',SNR_in,SNR_out1,snr1);
fprintf('SNR_in=%5.4f SNR_out2=%5.4f snr2=SNR_out2-SNR_in=%5.4f\n',SNR_in,SNR_out2,snr2);
%% 作时域图
figure(2);
subplot(211);
plot(time,speech/max(speech)); %原始语音时域波形
grid on; %开启坐标网格
axis tight; %自动设置x轴和y轴的范围使图形区域正好占满整个显示空间
title('Original Voice'); %设置标题
ylabel('归一化幅值');
xlabel('时间/s');
subplot(212);
plot(time,y/max(y)); %含噪语音时域波形
grid on;
axis tight;
title(['Noise Added(SNR=',num2str(SNR_in),'dB)']);%mun2str表示将数值转换成字符串
ylabel('归一化幅值');
xlabel('时间/s');
figure(3);
subplot(211);
plot(time,enhanced/max(enhanced)); %降噪语音时域波形
grid on;
axis tight;
title(['Enhanced Voice(SNR=',num2str(SNR_out1),'dB)']);
ylabel('归一化幅值');
xlabel('时间/s');
subplot(212);
plot(time,output/max(output));
grid on;
axis tight;
title(['Bandpass output(SNR=',num2str(SNR_out2),'dB)']);
ylabel('归一化幅值');
xlabel('时间/s');
%% 作频谱图
f=(size/2:size-1)*fs/size-fs/2; %调整频率范围:0-9600Hz
fspeech1=abs(fftshift(fft(speech)));
%fft求出speech频谱,频谱图是以Nyquist频率为对称轴,fftshift将频谱调整为关于0Hz对称,abs求出幅度谱
fspeech2=fspeech1(size/2:size-1);%幅值修正得到真实幅值
figure(4);
subplot(211);
plot(f,10*log10(fspeech2));%幅值取对数,得到分贝(dB)值
axis([0 9600 0 30]);
grid on;
title('原信号频谱');
xlabel('频率/Hz');
ylabel('dB');
subplot(212);
fy1=abs(fftshift(fft(y)));
fy2=fy1(size/2:size-1);
plot(f,10*log10(fy2));
axis([0 9600 0 30]);
grid on;
title('加噪语音频谱');
xlabel('频率/Hz');
ylabel('dB');
figure(5);
subplot(211);
fenhanced1=abs(fftshift(fft(enhanced)));
fenhanced2=fenhanced1(size/2:size-1);
plot(f,10*log10(fenhanced2));
axis([0 9600 0 30]);
grid on;
title('增强语音频谱');
ylabel('dB');
xlabel('频率/Hz');
subplot(212);
foutput1=abs(fftshift(fft(output)));
foutput2=foutput1(size/2:size-1);
plot(f,10*log10(foutput2));
axis([0 9600 0 30]);
grid on;
title('带通滤波后频谱');
ylabel('dB');
xlabel('频率/Hz');
%% 播放音频
sound(speech,fs); %播放原信号音频
pause(2); %暂停2秒
sound(y,fs); %播放加噪信号音频
pause(2);
sound(enhanced,fs); %播放去噪后信号音频
pause(2);
sound(output,fs); %播放带通滤波后音频
五.小结
本文详细讲述了谱减法作为语音增强算法并在MATLAB仿真实现的步骤,通过仿真输出的图形窗口观察信号的时频特性,加以分析。经过多次实验,增强语音的输出信噪比维持在16dB到17dB,滤波后语音的输出信噪比维持在18dB到19dB,信噪比得到部分改善,同时滤波后的语音基本滤除了高频残留噪声,听觉质量得到改善。由于在谱减法中,把带噪语音谱与噪声估计谱相减会存在误差,噪声无法滤除干净,声音听上去还是不可避免地有一些音乐噪声。