【意见征求稿】第1章 深度学习图像分割概述
深度学习近年来在众多领域已取得了令人瞩目的成就,计算机视觉正是其中的典型代表。图像分割是图像处理和计算机视觉的一个重要应用方向,在深度学习的影响下,图像分割经历了由传统图像处理技术向深度学习主导的重要转变。本章作为一个概述性章节,主要对深度学习、计算机视觉和图像分割进行简单的综述,对本书涉及的主要工具和框架进行简介,对本书内容和章节做出简要安排。
1.1 深度学习与计算机视觉
在过去的几年里,以机器学习(Machine Learning,ML)和深度学习(Deep Learning,DL)为代表的人工智能(Artificial Intelligence,AI)技术一直为大众所津津乐道。从高铁站闸机的人脸识别通道到汽车最新的无人驾驶辅助系统,从手机的语音交互功能到实时的机器翻译系统,从个性化的用户推荐到各种电子竞技游戏,人工智能技术早已普及到我们生活中的各个角落。人工智能、机器学习和深度学习之间存在着如下关系(如图1-1)。
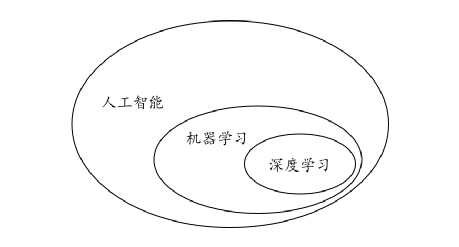
图1-1 人工智能、机器学习与深度学习的关系
可以看到,人工智能、机器学习和深度学习之间存在着一种递进的包含关系,机器学习是人工智能的一个主要分支,而深度学习则是机器学习的一个主要分支。相较于机器学习中线性模型、决策树、支持向量机和集成学习等模型范式,深度学习则是机器学习中神经网络(Neural Networks,NN)这一模型范式的延伸和发扬。颇具深度的各种层级化神经网络结构、可供模型训练的大量数据集以及消费级的计算力资源,这些都使得神经网络从传统的机器学习模型中脱颖而出,经过近些年的开枝散叶,目前深度学习的风头俨然超过传统的机器学习。
在深度学习的众多应用方向中,计算机视觉(ComputerVision,CV)是神经网络应用最广泛、最深入的方向之一。从十几年前的个人计算机时代到如今的移动互联网时代,图像和视频早已无处不在,简单而言,计算机视觉就是通过计算机编写算法来理解图像中有什么,为计算机赋予视觉能力,是人工智能的一个重要体现。深度学习的各大应用领域如图1-2所示,计算机视觉是深度学习的一个重要应用领域。

图1-2 深度学习的应用领域
1.2 计算机视觉的三大任务
传统的计算机视觉应用方向广泛,单从应用上来讲一定不止三大任务,所以这里的“计算机视觉的三大任务”指的是基于深度学习的三大任务:
l图像分类(Image Classification)聚焦于整张图像,对整张图片进行分类,判断图中主要目标物体是猫还是狗,如图1-3左图所示。
l目标检测(Object Detection)定位于图像具体区域,判断图中每个目标物体的类别及其所在图中的位置。如图1-3中间的图所示,需要判断猫、狗、小黄鸭的类别和对应坐标。
l图像分割(Image Segmentation)细化到每一个像素,判断每个物体所属的像素边界,如图1-3右图所示,将猫、狗、小黄鸭的像素边界分割出来。
可见三大任务之间明显存在着一种递进的层级关系,如图1-3所示。

图1-3 计算机视觉三大任务
下面简单回顾一下近年来这三大任务的研究进展情况。
1.2.1 图像分类
从传统的图像处理和机器学习的角度来看,图像分类可以看作一种模式识别、决策理论以及统计分类器的应用范畴。深度学习大规模介入图像分类领域是在2012年的ILSVRC(ImageNet大规模视觉识别挑战赛,如图1-4所示),当年由Alex Krizhevsky提出的AlexNet将该项比赛Top 5错误率降至16.4%,这一成绩引起了当时学界和业界的极大关注。

图1-4 ImageNet项目
此后在历年的ILSVRC挑战赛上,都有层出不穷的深度卷积网络结构设计涌现,比如2014年的Inception和VGG、2015年的ResNet、2016年的ResNeXt、2017年的SENet等,图像分类正式进入深度学习主导的时代。ILSVRC挑战赛历年经典模型如表1-1所示。
表1-1ILSVRC历年经典模型
年份 |
网络名称 |
Top 5成绩(错误率) |
论文 |
2012 |
AlexNet |
16.42% |
ImageNet Classification with Deep Convolutional Neural Networks |
2013 |
ZFNet |
13.51% |
Visualizing and understanding convolutional networks |
2014 |
GoogLeNet |
6.67% |
Going Deeper with Convolutions |
VGG |
6.8% |
Very deep convolutional networks for large-scale image recognition |
|
2015 |
ResNet |
3.57% |
Deep Residual Learning for Image Recognition |
2016 |
ResNeXt |
3.03% |
Aggregated Residual Transformations for Deep Neural Networks |
2017 |
SENet |
2.25% |
Squeeze-and-Excitation Networks |
受益于ImageNet数据集项目和大规模计算资源,此后基于深度学习的图像分类网络结构设计更加层出不穷。其中像NasNet、DenseNet和EfficientNet等网络不断刷新ImageNet的SOTA(state of the art)表现。
从算法设计的角度来看,层级化的卷积神经网络(Convolutional Neural Networks,CNN)结构是深度学习图像分类的最重要实现基础。CNN是一种包含卷积计算并具有深度结构的前馈神经网络,主要包括卷积层、池化层和全连接层。对图像进行自动化的特征提取,将图像的语义信息进行浓缩后送入分类器进行训练。经过近些年的沉淀,一些经典的图像分类网络结构设计对后来深度学习计算机视觉发展影响深远,比如VGG的平铺式(Plain)的卷积结构、ResNet的跳跃连接结构、DenseNet的密集连接结构、Inception系列的1×1卷积、SENet的squeeze and excitation结构等。
深度学习图像分类网络的另一个主要作用是为目标检测、图像分割、图像搜索等下游的视觉任务提供主干(Backbone)网络,即用于图像特征提取的CNN编码器。比如图像分割的UNet网络可以使用VGG16作为编码器的主干网络,Deeplab v3使用ResNet-101作为其编码器的主干网络等。
1.2.2 目标检测
伴随着深度学习在图像分类领域的逐渐流行,一些基于图像分类的下游视觉任务逐渐发展起来,目标检测就是其中之一。简单而言,目标检测就是在图像分类的基础上给出目标物体在图像中的具体位置。深度学习兴起之后,CNN也逐渐取代传统目标检测算法取得该领域的主导地位。从两阶段(Two Stage)的R-CNN系列算法到一阶段(One Stage)的YOLO系列算法,基于CNN的目标检测算法一直在刷新该领域的SOTA。
两阶段目标检测算法以R-CNN系列为代表,其主要思路是先对整张图像生成候选区域(Proposal Region),然后再基于CNN进行分类,主要代表网络包括R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和Mask R-CNN等。图1-5为Mask R-CNN网络框架。
图1-5 Mask R-CNN网络框架
两阶段目标检测算法虽然精度较高,但在实时检测场景需求下速度并不能很好的满足实时要求。先生成候选框再进行分类检测的策略能否做到一步到位?以YOLO系列为代表的一阶段目标检测算法给出了答案。YOLO系列算法的主要想法是输入图像后直接给出目标物体类别和对应坐标,不再像两阶段那样生成候选框。因为节省了一个步骤,YOLO系列算法的一大特点就是速度非常快,能够很好的满足实时检测的要求。YOLO系列算法包括v1、v2、v3、v4和v5五个不同的版本。图1-6是YOLO v3的实时检测效果。
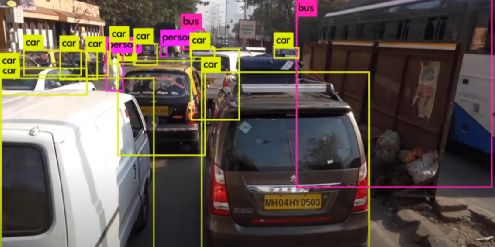
图1-6 YOLO v3实时检测效果
目标检测任务相较于图像分类而言,降低了图像的聚焦层次,关注图像中局部的目标物体,对局部物体的类别和具体定位进行研究。基于深度学习的目标检测应用广泛,在安防、自动驾驶、工业制造等领域都有着较为成熟的应用。
1.2.3 图像分割
在目标检测的基础上,图像分割是将分类任务的粒度进一步降低,对于图像的研究聚焦到每一个像素点上,对图像做像素级的分类。因为图像分割是本书的主题,所以有别于前两节直接介绍基于深度学习的图像分类和目标检测,在此之前,有必要对传统的图像分割算法进行一个大致的梳理和简介。
从图像处理的角度来看,图像分割是将图像细分为构成它的子区域或物体,主要是基于图像灰度值的两个特性来进行分割:不连续性和相似性。对于不连续的图像灰度值,传统图像分割方法主要以灰度突变为基础进行处理;对于相似的图像灰度值,主要是以一组预定义的规则把图像分割为相似的区域。
传统的图像分割方法主要包括5个大的分类:
l基于边缘检测的图像分割算法。
l基于阈值处理的图像分割算法。
l基于区域生长的图像分割算法。
l基于形态学的图像分割算法。
l基于图论的图像分割算法。
各类图像分割算法各具优缺点,具体将在第2章对传统图像分割的5大类算法进行一个较为系统的回顾。图1-7为Canny算子(一种基于边缘检测的图像分割算法)的分割效果。

图1-7 基于Canny算子的图像分割
相较于目标检测聚焦于图像局部区域,基于深度学习的图像分割关注的粒度则聚焦到具体的每一个像素,对每一个像素赋予一个语义标签,因而基于深度学习的图像分割最基本的一个大类也叫语义分割(Semantic Segmentation)。除此之外,基于深度学习的分割还包括实例分割(Instance Segmentation)和全景分割(Panoptic Segmentation)。三者之间有什么区别和联系呢?
l语义分割是对图像中的每个像素都划分出对应的类别,即实现像素级别的分类,例如图像中有多个人,那么语义分割的结果是,他们都被分到人这个类别。
l实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的个体。例如,图像有多个人,那实例分割的结果是不同的对象(每个人是一个对象)。
l全景分割则同时实现实例分割与不可数类别的语义分割。
可见,实例分割和全景分割都是以语义分割技术为基础的。语义分割、实例分割和全景分割具体如图1-8(b)、(c)和(d)图所示。
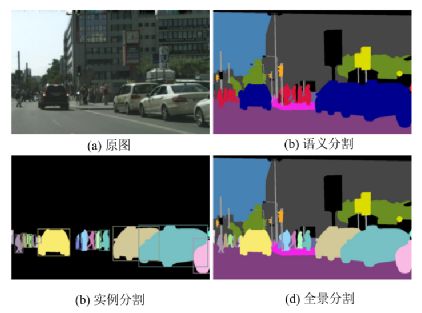
图1-8 语义分割、实例分割与全景分割
因为实例分割和全景分割都是建立在语义分割的技术框架质上的,所以本书以讲述语义分割为主。在语义分割发展早期,为了能够让深度学习进行像素级的分类任务,在分类任务的基础上对CNN做了一些修改,将分类网络中浓缩语义表征的全连接层去掉,提出用全卷积网络(Fully Convolutional Networks, FCN)来处理语义分割问题。然后UNet的提出,奠定了编解码结构的U形网络深度学习语义分割中的主导地位。UNet是一种基于CNN结构的语义分割网络,其主要包括编码器(Encoder)、解码器(Decoder)和跳跃连接(Skip Connection)三个部分,由于编码器和解码器一起构成了一个U形,故而称之为UNet。语义分割迄今为止最重要的两个设计有两个:
l一个是以UNet为代表的U形结构,目前基于UNet结构的创新就层出不穷,比如说应用于3D图像的V-Net、嵌套UNet结构的UNet++等。除此在外还有SegNet、RefineNet、HRNet和FastFCN。
l另一个是以DeepLab系列为代表的Dilation设计,主要包括DeepLab系列和PSPNet。
随着模型的基线(Baseline)效果不断提升,语义分割任务的主要矛盾也逐渐从下采样损失恢复像素逐渐演变为如何更有效地利用上下文信息。
除了上述两个重要设计之外,原先用于自然语言处理(Natural Language Processing, NLP)和序列模型领域的Transformer结构近两年也开始逐渐用于图像语义分割领域。由于CNN的平移不变性和捕捉长期依赖能力的不足,基于CNN的语义分割网络在一定程度上依然有较大的提升空间,而Tranformer正好以捕捉序列之间的长期依赖而见长。因而基于Tranformer的语义分割结构逐渐流行起来。像SETR、TransUNet、SwinUNet、TransAttUNet和LeVit-UNet等。
1.3 OpenCV简介
OpenCV(Open Source Computer Vision Library)是一款跨平台的开源计算机视觉库,为图像处理和计算机视觉提供大量可直接调用的函数,可用于开发实时的图像处理、计算机视觉以及模式识别等程序。OpenCV用C/C++编写,同时也提供了Python、Java、MATLAB等其他语言的接口。OpenCV为传统的图像分割算法也提供了大量可直接调用的函数,本节仅对OpenCV做一个简单介绍,基于OpenCV的图像分割算法我们将在第2章进行详细的介绍。图1-9为OpenCV官方主页。
图1-9 OpenCV主页
OpenCV图像处理模块imgproc涵盖了常用的图像处理功能,该模块主要包括基础部分(basic)、变换部分(Transformations)、直方图部分(Histograms)、绘制轮廓部分(Contours)和其他部分(Others)。代码1-1是一个C++版本的OpenCV代码示例,主要用于读取、展示和保存图像。
代码1-1 OpenCV代码示例(C++)
#include
#include
#include
#include
using namespace cv;
int main()
{
// 图片路径
std::string image_path = samples::findFile("example.jpg");
// 读取图片
Mat img = imread(image_path, IMREAD_COLOR);
if(img.empty())
{
std::cout << "Could not read the image: " << image_path << std::endl;
return 1;
}
// 显示图片
imshow("Display window", img);
int k = waitKey(0);
if(k == 's')
{
// 保存图片为png格式
imwrite("example.png", img);
}
return 0;
}
代码1-1对应的Python版本写法如代码1-2所示。
代码1-2 OpenCV代码示例(Python)
# 导入opencv库
import cv2
import sys
# 读取图片
img = cv2.imread(cv2.samples.findFile("starry_night.jpg"))
if img is None:
sys.exit("Could not read the image.")
# 显示图片
cv2.imshow("Display window", img)
k = cv2.waitKey(0)
if k == ord("s"):
# 保存图片为png格式
cv2.imwrite("starry_night.png", img)
对上述读取图像的例子分别给出了C++和Python的代码版本,本书中涉及图像处理的例子一般都用C++代码给出,涉及深度学习的图像分割都用Python代码给出。
1.4 PyTorch深度学习框架简介
PyTorch是一款可以媲美于TensorFlow的深度学习开源计算框架,但又相比于TensorFlow在语法上更具备灵活性。PyTorch由Facebook开发,原生于一款小众语言Lua,后来基于Python版本具备了强大的生命力。作为一款基于Python的深度学习计算库,PyTorch提供了高于NumPy的强大的张量计算能力和兼具灵活性和速度的深度学习研究和生产环境下使用的功能。随着最新的1.10版本发布后,PyTorch已经具备更加完备和强大的深度学习技术生态系统。图1-10为PyTorch官网页面。
图1-10 PyTorch官网
本书主要关注PyTorch在搭建一个深度学习项目过程中的主要范式及其相关功能,包括数据流的导入(DataLoader)、数据增强(torchvision.transforms)、模型搭建(torch.nn)、模型训练、验证和推理,以及模型部署(libtorch)等代码范式。代码1-3是使用PyTorch搭建的一个LeNet5网络示例,可以看到基于torch.nn模块能够非常快速便捷的搭建神经网络。
代码1-3 PyTorch LeNet5网络搭建示例
# 导入torch.nn相关模块
import torch.nn as nn
import torch.nn.functional as F
# 搭建一个LeNet5
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积层1
self.conv1 = nn.Conv2d(3, 6, 5)
# 池化层
self.pool = nn.MaxPool2d(2, 2)
# 卷积层2
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接层1
self.fc1 = nn.Linear(16 * 5 * 5, 120)
# 全连接层2
self.fc2 = nn.Linear(120, 84)
# 全连接层3
self.fc3 = nn.Linear(84, 10)
# 定义网络的前向推理流程
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
关于PyTorch本节仅作简要介绍,更加详细的代码示例和功能描述我们将在本书第11章进行阐述。
1.5 本书章节安排
本书定位于深度学习图像分割,是一本兼具理论阐述和代码实战的专业读物。全书总共15章:
l第1章(本章)为概述性介绍,主要对深度学习、计算机视觉、图像分割等概念,以及对全书用到的两个主要工具OpenCV和PyTorch进行简单介绍。
l第2~10章为全书理论部分,其中第2章对传统图像分割算法和OpenCV应用进行介绍;第3章对深度学习图像分割进行总览,包括语义分割、实例分割和全景分割,对基于深度学习的图像分割任务进行详细阐述;第4~9章为全书理论核心内容,对深度学习图像分割的技术组件、三种代表性的模型结构、三维图像分割等进行详细解读;第10章则是梳理图像分割领域的一些经典数据集,为实战部分提供数据基础。
l第11~14章为全书实战部分。实战部分则是基于PyTorch进行全流程的深度学习图像分割项目展示。其中第11章主要是对PyTorch图像分割代码框架进行演示,对数据流、模型搭建、实验管理、可视化、快速推理和模型部署等模块进行讲解;第12章基于MIT ADE20K公开数据集进行实战演示,介绍深度学习在场景感知方向上的应用;第13章对医学影像数据集进行三维的病灶分割,了解图像分割在医学影像上的应用;第14章则是基于遥感数据进行图像分割,了解深度学习在地理信息系统中的应用。
l第15章为全书总结。
全书内容安排如图1-11所示。
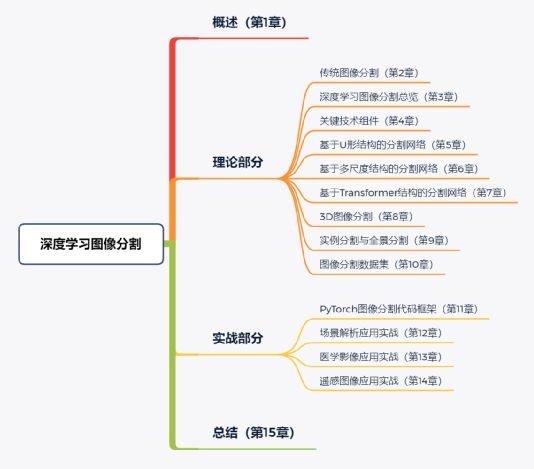
图1-11 本书内容导图
1.6 本章小结
本章为全书概述性章节,对全书内容进行总览,对深度学习、计算机视觉、三大任务之间的关系进行简介,对传统图像分割算法与深度学习图像分割算法进行概述。对全书所用到的两个基本工具,OpenCV和PyTorch进行简介,最后对全书内容进行提要,以便读者对本书有一个基本的把握。
往期精彩:
《机器学习:公式推导与代码实现》1-7章PPT下载
《机器学习 公式推导与代码实现》随书PPT示例
时隔一年!深度学习语义分割理论与代码实践指南.pdf第二版来了!
新书首发 | 《机器学习 公式推导与代码实现》正式出版!
《机器学习公式推导与代码实现》将会配套PPT和视频讲解!