【OpenCV】模拟图像、数字图像、表示图像
文章目录
-
- CCD 与CMOS 图像传感器
- yuyv和mjpeg视频编码格式
- uvc_cam和usb_cam
- opencv驱动USB摄像头
- 模拟图像、数字图像、OpenCV表示图像
- 图像是波
- 焦距
- 光心
- 基线
- ORB_SLAM2中基线的用法
- ORB_SLAM2中光心的用法
- 三个通道
- 频率
- 滤波器
- 图像的滤波
- 图像的基本原理
- 高斯平滑和高斯模糊的算法
- 高斯模糊的算法
- 离散傅里叶变换和仿射变换Affine Transformation在图像处理中的应用及原理
- 离散傅里叶变换
- 仿射变换(Affine Transformation)原理及应用
CCD 与CMOS 图像传感器
CCD 与CMOS 图像传感器光电转换的原理相同,
CMOS:响应快,功耗低,噪点高,不均匀,画质受噪声影响多,ISO较小
CCD:响应慢,功耗高,噪点低,均匀,画质高,ISO较高
随着CMOS图像传感器的技术日趋进步,同时具有成像速度快,功耗少,成本低的优势,所以现在市面上的工业相机大部分使用的都是CMOS的图像传感器。
yuyv和mjpeg视频编码格式
免驱摄像头一般有两种传输格式,YUY2和MJPG,
前者是无压缩图像格式的视频,系统资源占用少(因为不用解码),不需要解码器,缺点是帧率稍慢(受限于USB分配的带宽),
后者是相当于JPEG图像压缩格式,优点是帧率高(视频开启快,曝光快),缺点是影像有马赛克,并且需要解码器,会占用PC系统资源。
uvc_cam和usb_cam

https://github.com/ericperko/uvc_cam
sudo apt-get install ros-kinetic-uvc-camera
rosrun uvc_camera uvc_camera_node
rviz
uvc-camera图像采集视频像素格式是mjpeg
usb_cam图像采集默认视频像素格式是mjpeg
笔记本自带摄像头图像采集视频像素格式是yuyv
https://github.com/ros-drivers/usb_cam
sudo apt-get install ros-kinetic-usb-cam
插入摄像头判断设备
cd /dev &&find . -name "video*"
roslaunch usb_cam usb_cam-test.launch
opencv驱动USB摄像头
参考后面文章
模拟图像、数字图像、OpenCV表示图像
OpenCV表示图像 OpenCV 基于 C 语言接口而建,采用名为 IplImage 的C语言结构体在内存(memory)中存放图像, IplImage 和 CvMat 都是 C 语言的结构,IplImage 由 cvMat 派生,cvMat 由 CvArr 派生。使用这两个结构的问题是内存需要手动管理,开发者必须清楚的知道何时需要申请内存,何时需要释放内存。新版本 OpenCV 中引入 Mat 类能够自动管理内存。
Mat简介 Mat 是一个类,由两个数据部分组成:matrix header 矩阵头(包含矩阵尺寸,存储方法,存储地址等信息)和一个指向存储所有像素值的矩阵(根据所选存储方法的不同矩阵可以是不同的维数)的指针。矩阵头的尺寸是常数值,但矩阵本身的尺寸会依图像的不同而不同,通常比矩阵头的尺寸大数个数量级。因此,当在程序中传递图像并创建拷贝时,大的开销是由矩阵造成的,而不是信息头。 需要注意的是, copy 这样的操作只是 copy 了矩阵的 matrix header 和那个指针,而不是矩阵的本身,也就意味着两个矩阵的数据指针指向的是同一个地址,需要开发者格外注意。 如果想建立互不影响的Mat,是真正的复制操作,需要使用函数 clone() 或者 copyTo() 。Mat是一个多维的密集数据数组,可以用来处理向量和矩阵、图像、直方图等等常见的多维数据。OpenCV 访问图像中的像素需要先行,后列,先 Y 轴后 X 轴。
opencv中Mat的数据定义为指向uchar 的指针,而构造函数又提供了许多其他类型。
其实数据在内存中是一维存储的,而图像基本结构是二维的,3D图像还会是三维的;
同时,彩色图像还有多个channel(通道);
为了便于编程使用,opencv对一维数据进行矩阵的抽象封装,这个就是Mat类;
Mat是一个基础类,封装了构造函数,重载运算符和基础的运算函数(很多类似于matlab的函数);
Mat_ 类就是利用模板类型继承于Mat,所以opencv是有模板类型的,就是Mat_ 。
不管是什么类型,Mat类中的data成员是一个 unsigned char *,指向数据的第一个字节(同时还定义了datastart,dataend等,参看源代码),当你使用高级类型的getMat().data函数获得该对象的数据时,可以通过强制转换访问来获得你的数据类型比如我想看float类型图像的第[3,5]像素点的值,可以:((float )data)[5width+3]来访问,这样的访问比较原始。一般opencv core里面提供的算法是输入是InputArray和OutputArray;这两个和Mat有很大的关系,void * 就是指向Mat对象,同时加入了一些flag来判断Mat的类型比如是不是img等
/home/q/package/opencv-3.4.0/modules/core/include/opencv2/core/mat.hpp
opencv 源代码头文件
Mat属性的理解
/******************
* 读取一张二维三通图像
******************/
cv::Mat image;
// 新版本OpenCV中引入Mat类自动管理内存处理图像数据
image = cv::imread(argv[1]);
// cv::imread函数读取argv[1]指定路径下的图像
if (image.data == nullptr) {
std::cerr << "文件" << argv[1] << "不存在." << std::endl;
// 判断图像文件是否正确读取如果不能读取可能是文件不存在
return 0;
// 没有读取图片return 0终止函数
}
cv::namedWindow( "image", CV_WINDOW_AUTOSIZE );
// OpenCV创建显示图像窗口"image"
imshow( "image", image);
// 在窗口"image"显示图像image
cv::waitKey(0);
// 按任意键退出,不加这一句窗口会一闪而过
std::cout << "image.rows: " << image.rows << std::endl;
// image.rows图像的行数是: 674
std::cout << "image.cols: " << image.cols << std::endl;
// image.cols图像的列数是: 1200
std::cout << "image.dims: " << image.dims << std::endl;
// image.dims图像的维度是: 2
std::cout << "image.channels(): " << image.channels() << std::endl;
// image.channels()图像的通道是: 3
std::cout << "image.type(): " << image.type() << std::endl;
// image.type()图像的类型是: 16
std::cout << "image.depth(): " << image.depth() << std::endl;
// image.depth()图像的深度是: 0
std::cout << "image.elemSize(): " << image.elemSize() << std::endl;
// image.elemSize()图像的elemSize是: 3
std::cout << "image.elemSize1(): " << image.elemSize1() << std::endl;
// image.elemSize1()图像的elemSize1是: 1
/******************
* 创建一张二维三通图像
******************/
cv::Mat q_image(image.rows, image.cols, CV_8UC3, cv::Scalar(0,0,255));
/***************************************************************************
* cv::Mat定义一个矩阵行数/高为image.rows,列数/宽为image.cols
* CV_(位数)+(数据类型)+(通道数)
* 其中CV_后面紧接的数字表示位数,分别对应8bit(0~255或者-128~127)16bit(0~65535或者-32768~32767)
* U表示Unsigned无符号整数类型,即其内部元素的值不可以为负数
* S表示Signed有符号整数类型,其值存在负数
* F则表示浮点数类型,即矩阵的内部元素值可以为小数(32对应单精度float类型,64对应双精度double类型)
* C1~C4表示对应的通道数,即有1~4个通道
*
*【1】CV_8UC1---则可以创建----8位无符号的单通道---灰度图片------grayImg
* #define CV_8UC1 CV_MAKETYPE(CV_8U,1)
*
*【2】CV_8UC3---则可以创建----8位无符号的三通道---RGB彩色图像---colorImg
* #define CV_8UC3 CV_MAKETYPE(CV_8U,3)
*
*【3】CV_8UC4--则可以创建-----8位无符号的四通道---带透明色Alpha通道的RGB图像
* #define CV_8UC4 CV_MAKETYPE(CV_8U,4)
*
* cv::Scalar(0,0,255)每个像素由三个元素组成即三通道,初始化颜色值为(0,0,255)
*
*/
std::cout << "q_image.rows: " << q_image.rows << std::endl; // 674
std::cout << "q_image.cols: " << q_image.cols << std::endl; // 1200
std::cout << "q_image.dims: " << q_image.dims << std::endl; // 2
std::cout << "q_image.channels(): " << q_image.channels() << std::endl; // 3
std::cout << "q_image.type(): " << q_image.type() << std::endl; // 16
std::cout << "q_image.depth(): " << q_image.depth() << std::endl; // 0
// depth用来度量每一个像素中每一个通道的精度,但它本身与图像的通道数无关,depth数值越大精度越高
// 在Opencv中,Mat.depth()得到的是一个0~6的数字,分别代表不同的位数
// 对应关系如下: enum{CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6}
// 可见0和1都代表8位,2和3都代表16位,4和5代表32位,6代表64位
// 其中U是unsigned无符号数的意思,S表示signed有符号数的意思
std::cout << "q_image.elemSize(): " << q_image.elemSize() << std::endl; // 3
// 矩阵中元素的个数为image.rows*image.cols=674*1200
// elemSize表示矩阵中每一个元素的字节数大小
// 如果Mat中的数据类型是CV_8UC1,那么elemSize==1
// 如果是CV_8UC3或CV_8SC3,那么elemSize==3(8位/8字节*C3通道=3)
// 如果是CV_16UC3或者CV_16SC3,那么elemSize==6
// 即elemSize是以8位(一个字节)为一个单位
std::cout << "q_image.elemSize1(): " << q_image.elemSize1() << std::endl; // 1
// 以字节为单位的有效长度的step为eleSize()*cols=48
// elemSize加上一个"1"构成了elemSize1这个属性,可认为是元素内1个通道的意思,
// 表示Mat矩阵中每一个元素单个通道的数据大小,以字节为一个单位,所以eleSize1==elemSize/channels
std::cout << "q_image.step: " << q_image.step << std::endl; // 3600
// step可以理解为Mat矩阵中每一行的"步长",以字节为基本单位,每一行中所有元素的字节总量,是累计了一行中所有元素,所有通道,所有通道的elemSize1之后的值
std::cout << "q_image.step1(): " << q_image.step1() << std::endl; // 3600
// step1()以字节为基本单位,Mat矩阵中每一个像素的大小,累计了所有通道的elemSize1之后的值,所以有step1==step/elemSize1
cv::namedWindow( "q_image", CV_WINDOW_AUTOSIZE );
imshow( "q_image", q_image);
cv::waitKey(0);
通过at方法读取Mat类矩阵中的元素at 方法读取单通道矩阵元素
cv::Mat M4 = (cv::Mat_<double>(3, 3) << 0, -1, 0, -1, 0, 0, 0, 0, 1);
// 创建自定义数据的矩阵Mat
std::cout << "M4 = " << std::endl << M4 << std::endl;
double value = M4.at<double>(0,1); // -1
// 通过at方法读取元素需要在后面跟上<数据类型>以坐标的形式给出需要读取的元素坐标(行数,列数)
std::cout << "value = " << std::endl << value << std::endl;
at 方法读取多通道矩阵元素
cv::Mat M5(3, 4, CV_8UC3, cv::Scalar(0, 0, 1));
// 创建一个3行4列,深度为0(8U),3通道,每个通道的值都为(0,0,1)的图像矩阵
cv::Vec3b vc3 = M5.at<cv::Vec3b>(0, 0);
// 通过at方法读取多通道Mat矩阵类中的元素
// 多通道矩阵每一个元素坐标处都是多个数据,因此引入一个变量用于表示同一元素多个数据
// OpenCV中定义cv::Vec3b,cv::Vec3s,cv::Vec3w,cv::Vec3d,cv::Vec3f,cv::Vec3i六种类型表示同一个元素的三个通道数据
// 数字表示通道的个数,最后一位是数据类型的缩写,b是uchar类型的缩写,s是short类型的缩写,w是ushort类型的缩写,
// d是double类型的缩写,f是float类型的缩写,i是int类型的缩写
int first = (int)vc3.val[0];
int second = (int)vc3.val[1];
int third = (int)vc3.val[2];
std::cout << "first: " << first << "second: " << second << "third: " << third << std::endl;
通过指针ptr读取Mat类矩阵中的元素
cv::Mat M6(3, 4, CV_8UC3, cv::Scalar(0, 0, 1));
for (int i = 0; i < M6.rows; i++){
// 循环遍历图像的每一行
uchar* row_ptr = M5.ptr(i);
// 用cv::Mat::ptr获得图像的行头指针,再定义一个uchar类型的row_ptr指向第i行的头指针
for (int j = 0; j < M6.cols*M6.channels(); j++){
// 循环遍历图像矩阵中每一行所有通道的数据
// Mat类矩阵矩阵中每一行中的每个元素都是挨着存放,每一行中存储的数据数量为列数与通道数的乘积
// 即代码中指针向后移动cols*channels()-1位,当读取第2行数据中第3个数据时,可以直接用M6.ptr(1)[2]访问
std::cout << "(int)row_ptr[" << j << "]: " << (int)row_ptr[j] << std::endl;
// 循环输出每一个通道中的数值
}
}
通过迭代器访问Mat类矩阵中的元素
// Mat类变量同时也是一个容器变量,所以Mat类变量拥有迭代器,用于访问Mat类变量中的数据,通过迭代器可以实现对矩阵中每一个元素的遍历
cv::Mat M7(3, 4, CV_8UC3, cv::Scalar(0, 1, 2));
cv::MatIterator_<uchar> it = M7.begin<uchar>();
cv::MatIterator_<uchar> it_end = M7.end<uchar>();
// Mat类的迭代器变量类型是cv::MatIterator_< >,在定义时同样需要在括号中声明数据的变量类型
// Mat类迭代器的起始是Mat.begin< >(),结束是Mat.end< >(),与其他迭代器用法相同,通过"++"运算实现指针位置向下迭代
// 数据的读取方式是先读取第一个元素的每一个通道,之后再读取第二个元素的每一个通道,直到最后一个元素的最后一个通道
for(int i = 0; it != it_end; it++){
std::cout << (int)(*it) << " ";
if((++i% M7.cols) == 0){
std::cout << std::endl;
}
}
模拟图像通过一定的速率对图像进行周期性的扫描,把图像上不同亮度的点变成不同大小的电信号,然后传送出去的方法就是图像模拟传输。模拟图像是通过某种物理量的强弱变化来表现图像上各点的颜色 信息,画稿、电视上的图像、相片、印刷品图像都是模拟图像。
数字图像对于一幅图像,我们可以将其放入坐标系中,这里取图像左上定点为坐标原点,x 轴向右,和笛卡尔坐标系x轴相同;y 轴向下,和笛卡尔坐标系y轴相反。这样我们可将一幅图像定义为一个二维函数 f(x,y),图像中的每个像素就可以用 (x,y) 坐标表示,而在任何一对空间坐标 (x,y) 处的幅值 f 称为图像在该点的强度或灰度,当 x,y 和灰度值 f 是有限离散数值时,便称该图像为数字图像。
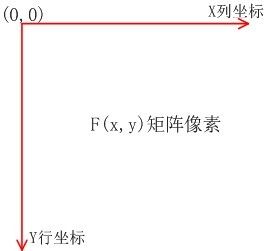
当图片尺寸以像素为单位时,每一厘米等于28像素,比如1515厘米长度的图片,等于420420像素的长度。
一个像素所能表达的不同颜色数取决于比特每像素(BPP)。
灰度图像:8bpp=2的8次方=256色, 高彩色:16bpp=2的16次方=65536色,真彩色:24bpps=2的24次方=16777216色。
图像的灰度值或强度值是由入射分量和反射分量决定的,入射分量i(x,y) 的性质取决于照射源,而反射分量r(x, y) 的性质取决于成像物体的特性,对于不同的照射源和成像物体则会有不同的取值。
分辨率图像总像素的多少,称为图像分辨率,由于图像通常用矩阵表示,所以分辨率常用,mn表示,注意:n表示行数(代表一列包含的像素),m表示列数(代表一行包含的像素)。如640480,表示图像的长和宽分别为640和480,总像素为640480=307200(相机中所说的30万分辨率),800600,表示图像的长和宽分别为800和600,总像素为800*600=480000(相机中所说的50万分辨率)。
显示数字图像数字图像f(x,y)主要有三种表示方式
● 画为三维表面图像,如下图(a)
● 可视化灰度阵列图像,如下图(b)
● 二维数值阵列图像,如下图(c )

图像亮度通俗理解便是图像的明暗程度,数字图像 f(x,y) = i(x,y) r(x, y) ,如果灰度值在[0,255]之间,则 f 值越接近0亮度越低,f 值越接近255亮度越高。而且我们也要把亮度和对比度区分开来,正如上述提的对比度指的是最高和最低灰度级之间的灰度差。下面通过图片感受一下亮度变化对数字图像的影响:

上面白色和红色两幅图中,图的右边相对于左边增加了亮度,可以看出图像右边相对于左边亮度有了一个整体的提升,这里只是对亮度做了一个小弧度的提升,我们尝试着将亮度提升的更高,如下图:

这里需要强调的是如果我们对亮度做这么一个剧烈的改变,那么便会在改变图片强度的同时也影响了图片的饱和度、对比度和清晰度,此时两个图片右边部分饱和度、对比度和清晰度都降低了,原因是过度增加亮度导致阴影赶上了高光,因为最大灰度值是固定的,所以最低灰度值快赶上了最大灰度值,因此影响了图片的饱和度、对比度和清晰度
饱和度指的是图像颜色种类的多少, 上面提到图像的灰度级是[Lmin,Lmax],则在Lmin、Lmax 的中间值越多,便代表图像的颜色种类多,饱和度也就更高,外观上看起来图像会更鲜艳,调整饱和度可以修正过度曝光或者未充分曝光的图片。使图像看上去更加自然
对比度上面已经介绍过,指的是图像暗和亮的落差值,即图像最大灰度级和最小灰度级之间的差值,看下图:

上面白色和红色辐条图像的右侧都增加了对比度,但我们可以看出右侧的白色辐条或是红色辐条随着对比度的增加,白/红色辐条都变亮了,背景变暗了,图像看起来更加清晰。
在红色辐条中增加对比度同时也增加了饱和度,但白色辐条的饱和度没有随着亮度的增加而增加,这印证了前面说的变化的程度取决于图像本身的特性。因为饱和度对于具有鲜艳颜色,颜色丰富的图像影响很大,而对于暗淡的颜色或几乎是中性颜色影响较小
图像锐化是补偿图像的轮廓,增强图像的边缘及灰度跳变的部分,使图像变得清晰。图像锐化在实际图像处理中经常用到,因为在做图像平滑,图像滤波处理的时候经过会把丢失图像的边缘信息,通过图像锐化便能够增强突出图像的边缘、轮廓

从山图中我们可以看出图像白色、红色辐条的接近中心的细辐条亮度、对比度和饱和度也有了明显的提升,但外侧确没有太明显的变化,这是因为图像锐化会更多的增强边缘数据,因此影响也就更加明显
小结一下:上面三个小节分别对图像的亮度、对比度、饱和度、锐化的概念做了基本的阐述,同时配图也着重强调了图像的亮度、对比度、饱和度、锐化之间也不是完全孤立存在的,是会互相影响的,So明白了他们之间的相互影响,在以后做数字图像处理的时候能根据更好的去调节图像亮度、对比度、饱和度、锐化这些属性
直方图
图像直方图
灰度直方图(histogram)是灰度级分布的函数,它表示图象中具有每种灰度级的象素的个数,反映图象中每种灰度出现的频率。灰度直方图的横坐标是灰度级,纵坐标是该灰度级出现的频率,是图象的最基本的统计特征。
生成图像灰度直方图的一般步骤:
1、统计各个灰度值的像素个数;
2、根据统计表画出直方图
灰度直方图的性质
1、只反映该图像中不同灰度值出现的次数(或频率),而不能反映某一灰度值像素所在的位置;
2、任何一张图像能唯一地确定一个与它对应的直方图,而一个直方图可以有多个不同的图像;
3、如果一张图片被剪裁成多张图片,各个子图的直方图之和就是这个全图的直方图。
直方图的用途
直方图有很多的用途,比如阀值分割,图像增强,还常常用于医疗影像。
帮助理解词袋模型
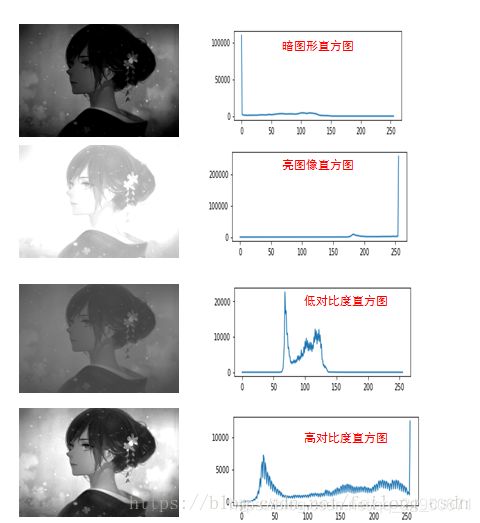
在暗图像中,直方图的分布都集中在灰度级的低(暗)端; 亮图像直方图的分布集中在灰度级的高端;低对比度图像具有较窄的直方图,且都集中在灰度级的中部;而高对比度的图像直方图的分量覆盖了很宽的灰度范围,且像素分布也相对均匀,此时图片的效果也相对很不错。于是我们可以得出结论:若一幅图像的像素倾向于占据整个可能的灰度级并且分布均匀,则该图像有较高的对比度并且图像展示效果会相对好,于是便引出图像直方图均衡化,对图像会有很强的增强效果

图像的取样
为了产生一幅数字图像,我们需要把连续的感知数据转化为数字形式,便是:取样和量化。取样和量化目的便是为了将连续的感知数据离散化,而且图像的质量在很大程度上也取决于取样和量化中所用的样本数和灰度级,图像的采样是把空域上或时域上连续的图像(模拟图像)转换成离散采样点(像素)集合(数字图像)的操作。采样越细,像素越小,越能精细地表现图像。不同采样间距的效果如下:
图像的量化
量化是把像素的灰度(浓淡)变换成离散的整数值的操作。最简单的量化是用黑(0)白(255)两个数值(即2级)来表示,成为二值图像。
量化越细致,灰度级数(浓淡层次)表现越丰富。计算机中一般用8bit(256级)来量化,这意味着像素的灰度(浓淡)是0—255之间的数值。化级数的效果图如下:
一直不理解像素的读取方式以及图形化是什么样子的,今天填坑了!
这是彩色三通道图像素的样子
 这是灰度单通道图像素的样子
这是灰度单通道图像素的样子
 读取像素的代码是
读取像素的代码是float grayscale = float ( gray.ptr<uchar> ( cvRound ( kp.pt.y ) ) [ cvRound ( kp.pt.x ) ] )
完成可运行代码
#include
#include ( cvRound ( kp.pt.y ) ) [ cvRound ( kp.pt.x ) ] );
cv::namedWindow("image_gray", CV_WINDOW_NORMAL);
imshow("image_gray",image_gray);
waitKey();
return 0;
}
cmake_minimum_required(VERSION 3.17)
project(untitled)
set(CMAKE_CXX_STANDARD 11)
find_package( OpenCV )
add_executable(untitled main.cpp)
target_link_libraries( untitled ${OpenCV_LIBS})
图像是波
图像由像素组成,一张 400 x 400 的图片共包含了 16 万个像素点。

数字图像坐标示意图

针孔相机模型

光心在物理成像平面前方,成的像是倒立的所以为了计算方便,我们把物理成像平面移动到了光心的前面,物理成像平面在焦点所在的平面
焦距
(focal lenth):
焦距是指从镜片映射中心到可呈清晰像的像平面的距离。
焦距的大小决定着视角的大小,焦距数值小,视角大,所观察的范围也大;焦距数值大,视角小,观察范围小。根据焦距能否调节,可分为定焦镜头和变焦镜头两大类。
焦距长度是指从透镜的光心到焦点的距离。

焦距,是光学系统中衡量光的聚集或发散的度量方式,指平行光入射时从透镜光心到光聚集之焦点的距离。亦是照相机中,从镜片中心到底片或CCD等成像平面的距离。

焦距是指镜头中心到焦点的距离
用凸透镜照太阳,会出现一个点,那个就是焦点,然后那个点到凸透镜的距离就是焦距
focal length 焦距,即焦长,是平行光入射时,从透镜光心到光线聚集之焦点的距离。在相机中,焦距是从镜片中心到底片或是CCD等成像平面的距离。

焦距越大,镜头角度越小。焦距越小,镜头角度越大。



光心

世界坐标系的原点是左摄像头凸透镜的光心。
f和d的单位是像素,那这个像素到底表示什么,它与毫米之间又是怎样换算的?
这个问题也与针孔模型相关。在针孔模型中,光线穿过针孔(也就是凸透镜中心)在焦距处上成像,因此,图3的像平面就是摄像头的CCD传感器的表面。每个CCD传感器都有一定的尺寸,也有一定的分辨率,这个就确定了毫米与像素点之间的转换关系。举个例子,CCD的尺寸是8mm X 6mm,分辨率是640X480,那么毫米与像素点之间的转换关系就是80pixel/mm。
理解这里有助于理解ORB_SLAM2的代码。
基线

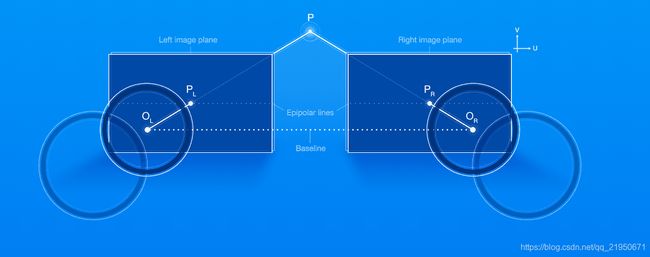
基线是两个光心之间的距离

ORB_SLAM2中基线的用法
// Check first that baseline is not too short
// 邻接的关键帧光心在世界坐标系中的坐标
cv::Mat Ow2 = pKF2->GetCameraCenter();
// 基线向量,两个关键帧间的相机位移
cv::Mat vBaseline = Ow2-Ow1;
// 基线长度
const float baseline = cv::norm(vBaseline);
ORB_SLAM2中光心的用法
计算该地图点的法线方向,也就是朝向等信息。能观测到该地图点的所有关键帧,对该点的观测方向归一化为单位向量,然后进行求和得到该地图点的朝向,初始值为0向量,累加为归一化向量,最后除以总数n。
cv::Mat normal = cv::Mat::zeros(3,1,CV_32F);
int n=0;
for(map<KeyFrame*,size_t>::iterator mit=observations.begin(), mend=observations.end(); mit!=mend; mit++){
KeyFrame* pKF = mit->first;
cv::Mat Owi = pKF->GetCameraCenter();
cv::Mat normali = mWorldPos - Owi;
normal = normal + normali/cv::norm(normali);
n++;
}
相机的成像过程

我们看到的图像是显卡帮我们渲染的的,多通道的图像(Mat类矩阵表示)是一个类似于三维的数据结构,而计算机的存储空间是一个二维空间,因此(Mat类矩阵)在计算机存储时是将三维数据变成二维数据,先存储第一个元素每个通道的数据,之后再存储第二个元素每个通道的数据。每一行的元素都按照这种方式进行存储,因此如果我们找到了每个元素的起始位置,便可以找到这个元素中每个通道的数据。
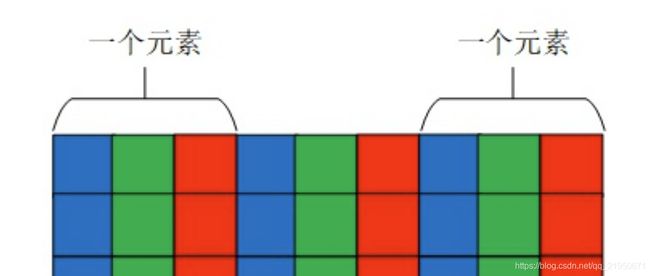
OpenCV中以BGR形式存储的彩色图片,每一个小格子代表一个像素

将彩色图片拆分成三个颜色通道存储的形式

图片数据的存储形式

三个通道


每个像素的颜色,可以用红、绿、蓝、透明度四个值描述,大小范围都是0 ~ 255,
比如黑色是[0, 0, 0, 255],白色是[255, 255, 255, 255]。
如果把每一行所有像素(上例是400个)的红、绿、蓝的值,依次画成三条曲线,就得到了下面的图形。

可以看到,每条曲线都在不停的上下波动。有些区域的波动比较小,有些区域突然出现了大幅波动(比如 54 和 324 这两点)。
对比一下图像就能发现,曲线波动较大的地方,也是图像出现突变的地方。

这说明波动与图像是紧密关联的。图像本质上就是各种色彩波的叠加。
频率
图像就是色彩的波动:波动大,就是色彩急剧变化;
波动小,就是色彩平滑过渡。因此,波的各种指标可以用来描述图像。
频率(frequency)是波动快慢的指标,单位时间内波动次数越多,频率越高,反之越低。

上图是函数sin(Θ)的图形,在2π的周期内完成了一次波动,频率就是1。

上图是函数sin(2Θ)的图形,在2π的周期内完成了两次波动,频率就是2。
所以,色彩剧烈变化的地方,就是图像的高频区域;色彩稳定平滑的地方,就是低频区域。
滤波器
滤波器(filter):过滤掉某些波,保留另一些波,
低通滤波器(lowpass):减弱或阻隔高频信号,保留低频信号
高通滤波器(highpass):减弱或阻隔低频信号,保留高频信号
下面是低通滤波的例子。

上图中,蓝线是原始的波形,绿线是低通滤波lowpass后的波形。可以看到,绿线的波动比蓝线小很多,非常平滑。
下面是高通滤波的例子。
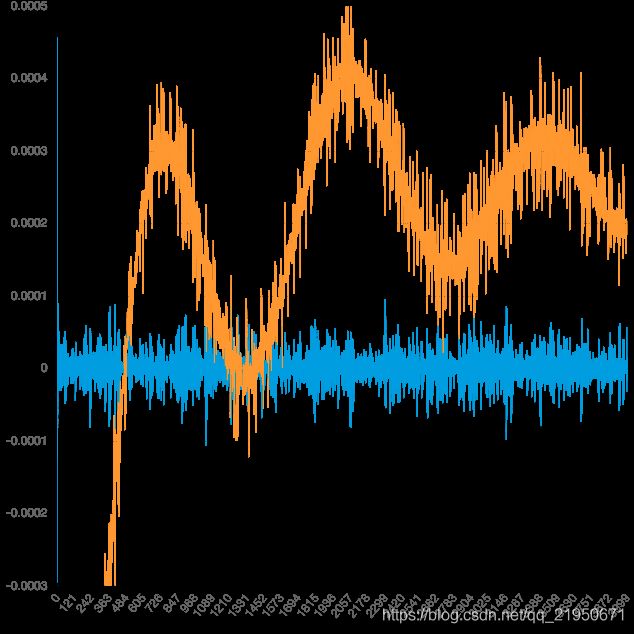
上图中,黄线是原始的波形,蓝线是高通滤波highpass后的波形。
可以看到,黄线的三个波峰和两个波谷(低频波动),
在蓝线上都消失了,而黄线上那些密集的小幅波动(高频波动),则是全部被蓝线保留。
再看一个例子。

上图有三根曲线,黄线是高频波动,红线是低频波动。它们可以合成为一根曲线,就是绿线。

上图中,绿线进行低通滤波和高通滤波后,得到两根黑色的曲线,它们的波形跟原始的黄线和红线是完全一致的。
图像的滤波
浏览器实际上包含了滤波器的实现,因为 Web Audio API 里面定义了声波的滤波。
这意味着可以通过浏览器,将lowpass和highpass运用于图像。
lowpass使得图像的高频区域变成低频,即色彩变化剧烈的区域变得平滑,也就是出现模糊效果。


上图中,红线是原始的色彩曲线,蓝线是低通滤波后的曲线。
highpass正好相反,过滤了低频,只保留那些变化最快速最剧烈的区域,也就是图像里面的物体边缘,所以常用于边缘识别。


上图中,红线是原始的色彩曲线,蓝线是高通滤波后的曲线。
图像的基本原理
亮度与对比度转换
一般来说,图像处理算子是将一幅或多幅图像作为输入数据,产生一幅输出图像的函数。图像变换可分为以下两种。
点算子:基于像素变换,在这一类图像变换中,仅仅根据输入像素值(有时可加上某些额外信息)计算相应的输出像素值。
邻域算子:基于图像区域进行变换。





高斯平滑和高斯模糊的算法
数字图像处理(四)图像增强之普通平滑、高斯平滑、laplacian、sobelprewitt锐化
就是卷积核的参数符合高斯分布

高斯模糊的算法
泊松分布是单位时间内独立事件发生次数的概率分布
指数分布是独立事件的时间间隔的概率分布
e就是增长的极限
通常,图像处理软件会提供"模糊"(blur)滤镜,使图片产生模糊的效果。

“模糊"的算法有很多种,其中有一种叫做"高斯模糊”(Gaussian Blur)。它将正态分布(又名"高斯分布")用于图像处理。

本文介绍"高斯模糊"的算法,你会看到这是一个非常简单易懂的算法。本质上,它是一种数据平滑技术(data smoothing),适用于多个场合,图像处理恰好提供了一个直观的应用实例。
一、高斯模糊的原理
所谓"模糊",可以理解成每一个像素都取周边像素的平均值。

上图中,2是中间点,周边点都是1。

“中间点"取"周围点"的平均值,就会变成1。在数值上,这是一种"平滑化”。在图形上,就相当于产生"模糊"效果,"中间点"失去细节。

显然,计算平均值时,取值范围越大,"模糊效果"越强烈。

上面分别是原图、模糊半径3像素、模糊半径10像素的效果。模糊半径越大,图像就越模糊。从数值角度看,就是数值越平滑。
接下来的问题就是,既然每个点都要取周边像素的平均值,那么应该如何分配权重呢?
如果使用简单平均,显然不是很合理,因为图像都是连续的,越靠近的点关系越密切,越远离的点关系越疏远。因此,加权平均更合理,距离越近的点权重越大,距离越远的点权重越小。
二、正态分布的权重
正态分布显然是一种可取的权重分配模式。

在图形上,正态分布是一种钟形曲线,越接近中心,取值越大,越远离中心,取值越小。
计算平均值的时候,我们只需要将"中心点"作为原点,其他点按照其在正态曲线上的位置,分配权重,就可以得到一个加权平均值。
三、高斯函数
上面的正态分布是一维的,图像都是二维的,所以我们需要二维的正态分布。

正态分布的密度函数叫做"高斯函数"(Gaussian function)。它的一维形式是:

其中,μ是x的均值,σ是x的方差。因为计算平均值的时候,中心点就是原点,所以μ等于0。
根据一维高斯函数,可以推导得到二维高斯函数:

有了这个函数 ,就可以计算每个点的权重了。
四、权重矩阵
假定中心点的坐标是(0,0),那么距离它最近的8个点的坐标如下:
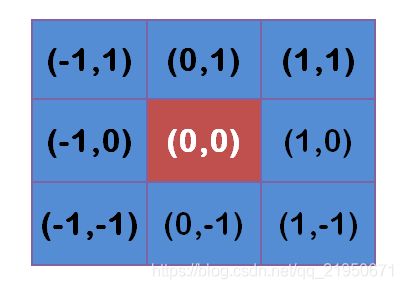
更远的点以此类推。
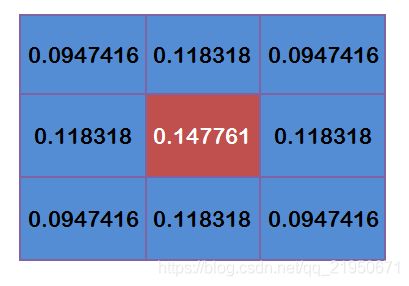
为了计算权重矩阵,需要设定σ的值。假定σ=1.5,则模糊半径为1的权重矩阵如下:

这9个点的权重总和等于0.4787147,如果只计算这9个点的加权平均,还必须让它们的权重之和等于1,因此上面9个值还要分别除以0.4787147,得到最终的权重矩阵。
五、计算高斯模糊
有了权重矩阵,就可以计算高斯模糊的值了。
假设现有9个像素点,灰度值(0-255)如下:

每个点乘以自己的权重值:

得到

将这9个值加起来,就是中心点的高斯模糊的值。
对所有点重复这个过程,就得到了高斯模糊后的图像。如果原图是彩色图片,可以对RGB三个通道分别做高斯模糊。
六、边界点的处理
如果一个点处于边界,周边没有足够的点,怎么办?
一个变通方法,就是把已有的点拷贝到另一面的对应位置,模拟出完整的矩阵。
离散傅里叶变换和仿射变换Affine Transformation在图像处理中的应用及原理
离散傅里叶变换
1.图像增强与图像去噪
绝大部分噪音都是图像的高频分量,通过低通滤波器来滤除高频——噪声; 边缘也是图像的高频分量,可以通过添加高频分量来增强原始图像的边缘;
2.图像分割之边缘检测
提取图像高频分量
3.图像特征提取:
形状特征:傅里叶描述
纹理特征:直接通过傅里叶系数来计算纹理特征
其他特征:将提取的特征值进行傅里叶变换来使特征具有平移、伸缩、旋转不变性
4.图像压缩
可以直接通过傅里叶系数来压缩数据;常用的离散余弦变换是傅立叶变换的实变换;
仿射变换(Affine Transformation)原理及应用
如何通俗地讲解「仿射变换」这个概念?
什么是仿射变换
仿射变换(Affine Transformation)其实是另外两种简单变换的叠加:一个是线性变换,一个是平移变换
仿射变换变化包括缩放(Scale、平移(transform)、旋转(rotate)、反射(reflection,对图形照镜子)、错切(shear mapping,感觉像是一个图形的倒影),原来的直线仿射变换后还是直线,原来的平行线经过仿射变换之后还是平行线,这就是仿射
仿射变换中集合中的一些性质保持不变:
(1)凸性
(2)共线性:若几个点变换前在一条线上,则仿射变换后仍然在一条线上
(3)平行性:若两条线变换前平行,则变换后仍然平行
(4)共线比例不变性:变换前一条线上两条线段的比例,在变换后比例不变
原文链接:https://blog.csdn.net/u011681952/article/details/98942207
