Text to image论文精读SSA-GAN:基于语义空间感知的文本图像生成 Text to Image Generation with Semantic-Spatial Aware GAN
目录
- 一、原文摘要
- 二、为什么提出SSA-GAN
- 三、SSA-GAN
- 3.1、文本编码器
- 3.2、SSACN 块
- 3.2.1、上采样块
- 3.2.2、掩码预测器
- 3.2.3、语义条件批量规范化(SCBN)
- 3.2.4、语义空间条件批量规范化(S-SCBN)
- 3.3、鉴别器
- 3.4、损失函数
- 四、实验
- 4.1、数据集
- 4.2、评价指标
- 4.3、实验细节
- 4.4、实验结果
- 4.4.1、定量分析
- 4.4.3、定性分析
- 4.4.2、消融研究
- 五、总结
- 最后
Semantic-Spatial Aware GAN提出了一种新的语义空间感知GAN框架,文章发表于2021年10月。
论文地址:https://arxiv.org/pdf/2104.00567v3.pdf
代码地址:https://github.com/wtliao/text2image
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
文本到图像生成(T2I)模型旨在生成语义上与文本描述一致的照片逼真图像。在生成性对抗网络(GAN)最新进展的基础上,现有的T2I模型取得了巨大进展。然而,仔细检查它们生成的图像会发现两个主要局限性:(1)条件批量归一化方法平等适用于整个图像特征映射,忽略了局部语义;(2) 文本编码器在训练过程中是固定的,它应该与图像生成器一起训练,以学习更好的文本表示,从而生成图像。为了解决这些局限性,我们提出了一种新的语义空间感知GAN框架,该框架以端到端的方式进行训练,以便文本编码器能够利用更好的文本信息。具体来说,我们介绍了一种新的语义空间感知卷积网络,该网络(1)学习以文本为条件的语义自适应变换,以有效地融合文本特征和图像特征;(2)以弱监督的方式学习掩码映射,该方法依赖于当前的文本-图像融合过程,以在空间上指导变换。在具有挑战性的COCO和CUB bird数据集上进行的实验表明,我们的方法在视觉保真度和与输入文本描述的一致性方面优于最近的最新方法
二、为什么提出SSA-GAN
- 堆叠式的结构虽然能够从粗到细生成图像,但是多个生成器-鉴别器对会导致更高的计算量和更不稳定的训练过程,且前两阶段的生成图像质量决定了最终的输出,如果前阶段没有生成大致框架的图像,后面生成的图像完全无法提高质量。
- 在以往的研究中,文本编码器在预训练完成后,就固定了参数,不再参与GAN整体框架的训练,如果文本编码器可以与图像生成器联合训练,它将更好地利用文本信息生成图像。
三、SSA-GAN
SSA-GAN的框架如下:

整体来看,和DF-GAN很像,也是单级主干结构,但是把UPBlocks改成了 SSACN Blocks。SSA-GAN包括一个文本编码器,一个生成器,一个鉴别器,首先由一个随机整体噪声输入,经过FC层和一次Reshape后,连接七个SSACN层,生成图片后输入鉴别器进行鉴别,需要注意的是,在SSA-GAN中,文本编码器不固定参数,其也是生成器的一部分。
3.1、文本编码器
依旧采用的是AttnGAN的那套,其是一个双向LSTM,通过最小化深度注意多模态相似模型(DAMSM)损失,使用真实图像-文本对进行预训练。
唯一不同的是,在之前的工作中,文本编码器都是固定参数了的,但是作者在这里试着把文本编码器归入生成器一起进行微调,实验显示其与SSA-GAN有一个微妙的相容,能进一步提高性能。
3.2、SSACN 块
SSACN块全称为:Semantic-Spatial Aware Convolutional Network
结构如下:
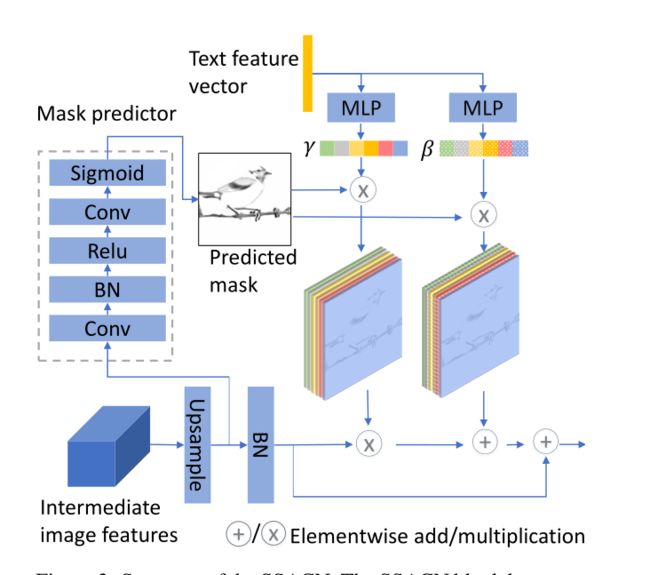
输入为上一个阶段输出的图像特征(图左下) f i − 1 ∈ R c h i − 1 × h i 2 × w i 2 f_{i-1} \in \mathbb{R}^{c h_{i-1} \times \frac{h_{i}}{2} \times \frac{w_{i}}{2}} fi−1∈Rchi−1×2hi×2wi和文本特征向量(图上方),输出为 f i ∈ R c h i × h i × w i f_{i} \in \mathbb{R}^{c h_{i} \times h_{i} \times w_{i}} fi∈Rchi×hi×wi并传递给下一阶段作为输入。其中 w i 、 h i 、 c h i w_i、h_i、ch_i wi、hi、chi分别为第i个块的宽、高和通道数。
每个SSACN块包括一个上采样块,一个掩码预测器,一个语义空间条件批量规范化(SSCBN)和一个残差块。
3.2.1、上采样块
上采样块使用双线性插值将图像特征的宽度和高度加倍
3.2.2、掩码预测器
模型使用的弱监督掩码预测器如下图所示,灰色框内为主体
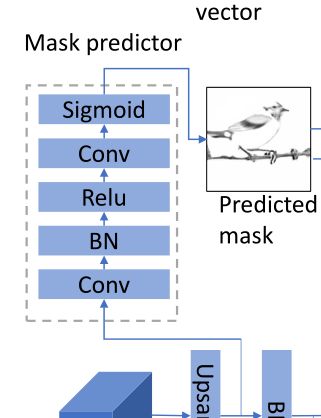
以上采样后的图像特征为输入,经过卷积、BN、Relu、卷积和Sigmoid后输出掩码图 m i ∈ R h i × w i m_{i} \in \mathbb{R}^{h_{i} \times w_{i}} mi∈Rhi×wi,该掩码图直观的指示了当前图像特征映射的哪些部分需要使用文本信息进行细节增强,以便增强语义一致性。
3.2.3、语义条件批量规范化(SCBN)
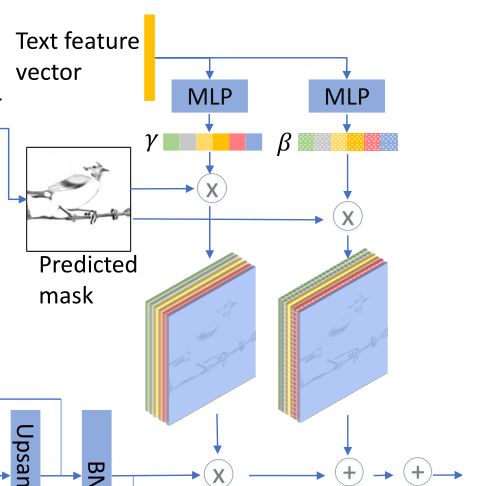
SCBN全称为:Semantic Condition Batch Normalization,其框架图如下,主体结构和DF-GAN很像,主要还是两个MLP。
首先解释什么是标准BN:给定一个输入为 x∈ R n ∗ c ∗ h ∗ w R^{n*c*h*w} Rn∗c∗h∗w,n是batch size,c是通道,h和w是高和宽,BN首先将x标准化为每个特征通道的零平均值和单位偏差:
x ^ n c h w = x n c h w − μ c ( x ) σ c ( x ) μ c ( x ) = 1 N H W Σ n , h , w x n c h w σ c ( x ) = 1 N H W Σ n , h , w ( x n c h w − μ c ) 2 + ϵ \begin{aligned} \hat{x}_{n c h w} &=\frac{x_{n c h w}-\mu_{c}(x)}{\sigma_{c}(x)} \\ \mu_{c}(x) &=\frac{1}{N H W} \Sigma_{n, h, w} x_{n c h w} \\ \sigma_{c}(x) &=\sqrt{\frac{1}{N H W} \Sigma_{n, h, w}\left(x_{n c h w}-\mu_{c}\right)^{2}+\epsilon} \end{aligned} x^nchwμc(x)σc(x)=σc(x)xnchw−μc(x)=NHW1Σn,h,wxnchw=NHW1Σn,h,w(xnchw−μc)2+ϵ
其中 ϵ \epsilon ϵ为一个数值稳定性的小正常数。
然后进行通道仿射变换 x ~ n c h w = γ c x ^ n c h w + β c \tilde{x}_{n c h w}=\gamma_{c} \hat{x}_{n c h w}+\beta_{c} x~nchw=γcx^nchw+βc,学习参数γc和βc。
在CBN中,公式被重述为:
x ~ n c h w = γ ( con ) x ^ n c h w + β ( con ) \tilde{x}_{n c h w}=\gamma(\text { con }) \hat{x}_{n c h w}+\beta(\text { con }) x~nchw=γ( con )x^nchw+β( con )
其就是将参数换成了一个函数,CBN能学习自适应于仿射变换给定条件的调制参数γ和β。
SCBN就是在CBN的具体实现,文本向量e作为自变量的函数: γ c = P γ ( e ˉ ) , β c = P β ( e ˉ ) \gamma_{c}=P_{\gamma}(\bar{e}), \quad \beta_{c}=P_{\beta}(\bar{e}) γc=Pγ(eˉ),βc=Pβ(eˉ), P γ ( ) P_γ() Pγ()和 P β ( ) P_β() Pβ()代表了MLP块。
3.2.4、语义空间条件批量规范化(S-SCBN)
不添加更多的空间信息,则上一步的SCBN将在图像特征图上均匀地工作。理想情况下,我们希望微调只对特征图中与文本相关的部分起作用。
于是作者将掩码预测器输出的掩码图添加到SCBN中作为空间条件,学习参数的公式被修改为:
x ~ n c h w = m i , ( h , w ) ( γ c ( e ˉ ) x ^ n c h w + β c ( e ˉ ) ) . \tilde{x}_{n c h w}=m_{i,(h, w)}\left(\gamma_{c}(\bar{e}) \hat{x}_{n c h w}+\beta_{c}(\bar{e})\right) . x~nchw=mi,(h,w)(γc(eˉ)x^nchw+βc(eˉ)).
其中,可以看出 m i ( h , w ) m_{i(h,w)} mi(h,w)不仅决定在何处添加文本信息,还起到了权重作用即决定要在某个部分上加强多少文本信息。这就是S-SCBN的原理。
3.3、鉴别器
鉴别器与DF-GAN相同,一样是单向输出和匹配感知梯度惩罚(MA-GP),这里不再赘述。
3.4、损失函数
鉴别器损失:采用了单向输出鉴别器,使用了MA-GP损失相关的对抗性损失
L a d v D = E x ∽ p d a t a [ max ( 0 , 1 − D ( x , s ) ) ] + 1 2 E x ∼ p G [ max ( 0 , 1 + D ( x ^ , s ) ) ] + 1 2 E x ∼ p d a t a [ max ( 0 , 1 + D ( x , s ^ ) ) ] + λ M A E x ∽ p d a t a [ ( ∥ ∇ x D ( x , s ) ∥ 2 + ∥ ∇ s D ( x , s ) ∥ 2 ) p ] , \begin{aligned} \mathcal{L}_{a d v}^{D}=& E_{x \backsim p_{d a t a}}[\max (0,1-D(x, s))] \\ &+\frac{1}{2} E_{x \sim p_{G}}[\max (0,1+D(\hat{x}, s))] \\ &+\frac{1}{2} E_{x \sim p_{d a t a}}[\max (0,1+D(x, \hat{s}))] \\ &+\lambda_{M A} E_{x \backsim p_{d a t a}}\left[\left(\left\|\nabla_{x} D(x, s)\right\|_{2}\right.\right.\\ &\left.\left.+\left\|\nabla_{s} D(x, s)\right\|_{2}\right)^{p}\right], \end{aligned} LadvD=Ex∽pdata[max(0,1−D(x,s))]+21Ex∼pG[max(0,1+D(x^,s))]+21Ex∼pdata[max(0,1+D(x,s^))]+λMAEx∽pdata[(∥∇xD(x,s)∥2+∥∇sD(x,s)∥2)p],
其中s是给定的文本描述, s ^ {\hat{s}} s^是不匹配的文本描述,x是对应于s的真实图像, x ^ \hat{x} x^是生成的图像,D()是鉴别器给出的是否匹配的判断, λ M A λ_MA λMA和p是MA-GP的超参数。
生成器损失:生成器损失由对抗损失和DAMSM(单词级细粒度图像文本匹配)损失构成:
L G = L a d v G + λ D A L D A M S M L a d v G = − E x ∽ p G [ D ( x ^ , s ) ] , \begin{aligned}\mathcal{L}_{G} &=\mathcal{L}_{a d v}^{G}+\lambda_{D A} \mathcal{L}_{D A M S M} \\ \mathcal{L}_{a d v}^{G} &=-E_{x \backsim p_{G}}[D(\hat{x}, s)], \end{aligned} LGLadvG=LadvG+λDALDAMSM=−Ex∽pG[D(x^,s)],
四、实验
4.1、数据集
CUB-Birds、COCO
4.2、评价指标
IS、FID
4.3、实验细节
硬件:4块 2080Ti
架构:Pytorch
优化器:Adam: β 1 β_1 β1=0.0, β 2 β_2 β2=0.9
学习率:生成器0.0001,鉴别器0.0004
超参数:p=6, λ M A λ_{MA} λMA=2, λ D A λ_{DA} λDA=0.1
epoch轮数: CUB 600轮 COCO 120轮
4.4、实验结果
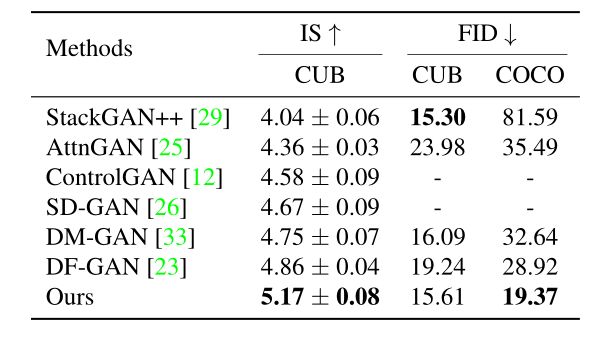
4.4.1、定量分析
4.4.3、定性分析
生成图片的效果:

在不同SSACN块中预测的掩码贴图,从左到右七个由浅至深的预测掩码图:

详情请看原文
4.4.2、消融研究

3是指把文本编码器也代入进行微调。可以看到虽然IS有提高,但是FID的指标却没那么好了,作者分析的原因是微调文本编码器有助于文本图像融合,提高文本图像的一致性,从而提高is分数,文本与图像一致的同时导致图像多样性下降,所以FID会变差。个人认为这个说服力不太强,有待商榷。
使用的不同数量的掩码图对实验效果的影响:

五、总结
该论文提出了一种新的用于T2I生成的语义空间感知GAN(SSA-GAN)框架,主要是在生成器上做的工作,创新如下:
- 一种语义空间感知卷积网络(SSACN)模块,通过基于当前生成的图像特征预测掩码映射草图,这种掩码图不仅可以决定在何处添加文本信息,还起到了权重作用即决定要在某个部分上加强多少文本信息。
- 一种新的仿射参数计算方法,将掩码图添加到SCBN中作为空间条件,然后从编码的文本向量中学习仿射参数,对语义空间条件进行批量归一化。
最后
个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
个人主页:中杯可乐多加冰
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言