机器学习实战----信息增益、信息增益率和基尼指数
一 什么是信息熵
对信息的一种度量。
物品可以用重量度量,长度可以用尺子度量。那信息用什么度量呢?《机器学习实战》这本书的信息量是多少呢?用什么度量呢?直到1948年香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵是消除不确定性所需信息量的度量。一件事情的信息熵越高说明它需要的信息越多,来消除它的不确定性。
二 信息增益
1 概念解析
通过名字也能猜测出来,添加了信息之后能增加多少收益。也就是说增加信息之后能减少多少不确定性。
条件熵:H(X|A) 在已知随机变量A的条件下随机变量Y的不确定性。
信息增益:特征A对数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定的条件下D的经验熵H(D|A)之差
g(X,A)=H(X)-H(X|A)。由于特征A而使得对数据D的分类的不确定性减少的程度。显然,对于数据集而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益,信息增益大的特征具有更强的分类能力。
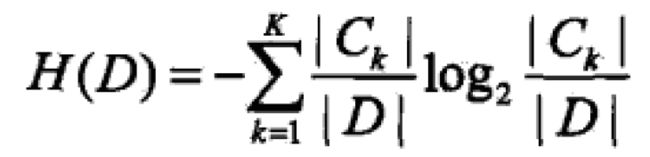

2 举例计算
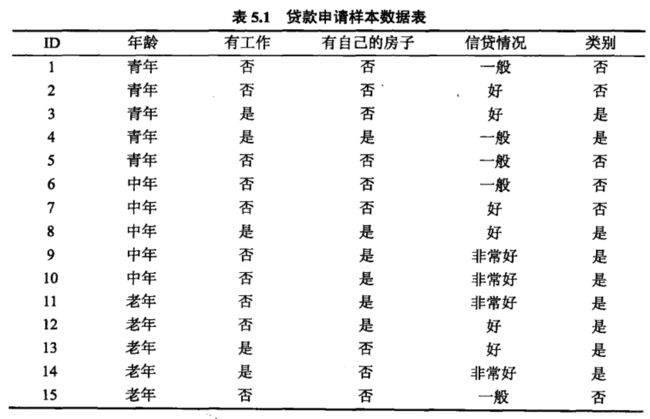
根据信息增益选择最优的特征,构建决策树。
(1)计算数据集的经验熵H(D)
=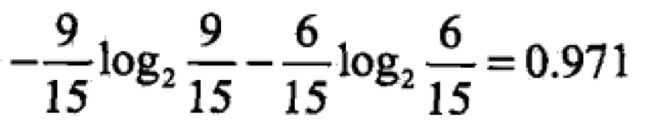
(2)计算各个特征对数据集的信息增益,分别以A1,A2,A3,A4表示年龄、有工作、有自己的房子和信贷情况4个特征



比较4个特征的信息增益,由于A3的信息增益最大,所以选择特征A3为数据集D的最优特征
3 弊端
信息增益作为划分特征集的特征,存在偏向于选择特征值较多的特征。比如计算特征ID的信息增益,一条数据一个ID,那么计算这些数据的条件熵H(D|ID) :

在经验熵相同的情况下,条件熵越小,最后的信息增益越大,所以ID这一特征自然被选为了对数据集D最优的特征。但是这个特征的选取并不是最优的,所以需要另一种计算方式对这种方法进行校正,这就是信息增益率。
三 信息增益率
1 概念解析
特征A对数据集D的信息增益比:
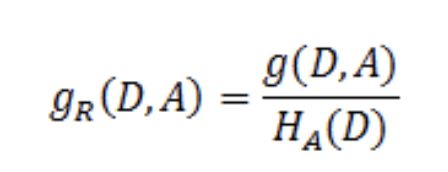
其中g(D,A)是特征A对数据集D的信息增益。![]() :对于数据集D,将当前特征A最为随机变量,得到的经验熵
:对于数据集D,将当前特征A最为随机变量,得到的经验熵
2 举例计算
根据表5.1计算特征A年龄的信息增益率:
3 弊端
缺点:信息增益比偏向取值较少的特征
原因: 当特征取值较少时HA(D)的值较小,信息增益比较大。A的特征值越少,A的不确定相对越低,A的经验熵越小。因而偏向取值较少的特征。
使用信息增益比:基于以上缺点,并不是直接选择信息增益率最大的特征,而是现在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征。
四 是基尼指数
1 概念解析
数据集D的纯度也可以用基尼指数来,基尼不纯度表示一个随机选中的样本在子集中被分错的可能性。基尼不纯度为这个样本被选中的概率乘以它被分错的概率。当一个节点中所有样本都是一个类时,基尼不纯度为零。
假设有K个类,样本点属于第k类的概率为pi,则概率分布的基尼指数为:
对于二分类问题,若样本点属于第一类的概率为p,属于第二类的概率为(1-p),则概率分布基尼指数为:
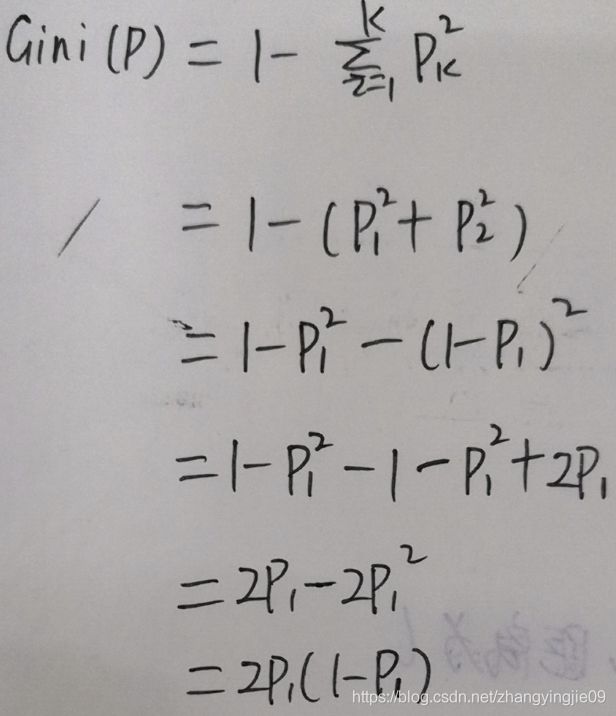
如果样本集合D根据特征A是否取某一可能值被分割为两部分,则在特征A条件下,集合D的基尼指数:
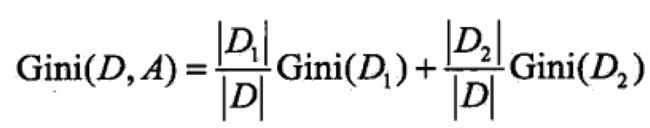
基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经过特征A的某个值分割集合后D的不确定性。基尼指数越大,集合的不确定想越大,这一点与熵相似。
2 举例计算
根据表5.1的数据计算特征A1年龄的基尼指数
五 总结:
1 每种方法都有自己的侧重点和弊端,根据数据的特征选择合适的方法,现在sklearn中决策树分类模型默认的是基尼指数
2 多总结,让学习有质感
参考资料:
决策树--信息增益,信息增益比,Geni指数的理解
《统计学习方法》----李航