使用Python+selenium爬取百度文库文档并存入word文档
最近因为穷,买不起百度文库的会员了,贫穷使我动手写代码。
本文的例子是爬取“老舍研究”习题
地址:https://wenku.baidu.com/view/88702202f56527d3240c844769eae009591ba245.html#
该文仅供学习使用哦
爬取的逻辑是,阅读全文–》跳转页面–》读取文本–》存入word文档
1.阅读全文
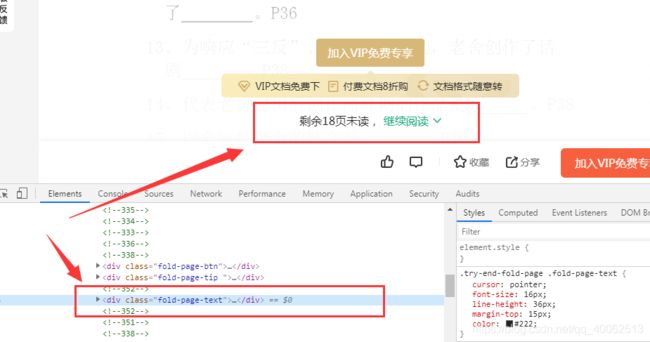
代码是:
driver.find_element_by_xpath("//div[@class='fold-page-text']").click()
这里有个问题是,如果当前页面没有拖到这个位置就无法获取这个元素
所以可以用js代码定义到这个位置,然后再执行上面的代码
#####js document.documentElement.scrollTop获取当前页面的位置,这段代码可以在浏览器的开发工具的控制台输入,然后得到当前位置
driver.execute_script("window.scrollTo(0,4004)");####跳转到页面“阅读所有页面”的位置
2.得到当前文档的总页数

driver.find_element_by_xpath("//div[@class='goto-page']").text.replace("/ ","")###得到总页数
####定位input标签,并输入跳转的页数
driver.find_element_by_xpath("//input[@class='cur-page']").clear()####清除输入值
driver.find_element_by_xpath("//input[@class='cur-page']").send_keys(1)###设置跳转页面编号
driver.find_element_by_xpath("//input[@class='cur-page']").send_keys(Keys.ENTER,'\ue007')#回车键
3.读取文本
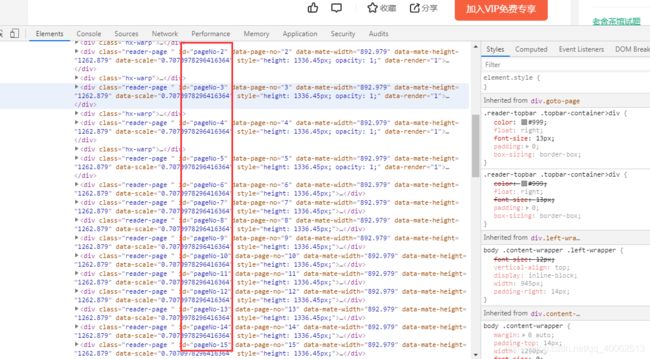
在上面的截图中,div中有共同的id,只要替换掉pageNo-后的数字就可以得到内容
driver.find_element_by_xpath("//div[@id='pageNo-{0}']".format(i)).text####得到页面的文本
4.存入word文档
需要引入第三方库python-docx
from docx import Document ##需要安装第三方库,python-docx
from docx.shared import Pt #用于设置字体样式
from docx.oxml.ns import qn # 中文格式
docx_path="老舍研究.docx"
doc=Document()
doc.styles["Normal"].font.name = u"微软雅黑"#设置字体样式
doc.styles["Normal"].font.size = Pt(14)#设置字体大小
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑')#设置文档的基础样式
doc.add_paragraph(result_text)#增加一个paragraph,写入内容
doc.save(docx_path)#保存文档
完整代码
import selenium
import pandas
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from docx import Document ##需要安装第三方库,python-docx
from docx.shared import Pt #用于设置字体样式
from docx.oxml.ns import qn # 中文格式
import time
driver=webdriver.Chrome("chromedriver.exe")
driver.get("https://wenku.baidu.com/view/88702202f56527d3240c844769eae009591ba245.html#")
time.sleep(5)
####为了避免百度页面变为旧版页面,需要刷新
driver.refresh()
time.slepp(2)
driver.execute_script("window.scrollTo(0,4004)");####跳转到页面“阅读所有页面”的位置
driver.find_element_by_xpath("//div[@class='fold-page-text']").click()####点击“阅读所有页面“
driver.execute_script("window.scrollTo(0,400)");####跳转到页面初始位置
#####得到当前总页面
all_page=driver.find_element_by_xpath("//div[@class='goto-page']").text.replace("/ ","")
result_text=""
i=1
while(i<=int(all_page)):
driver.find_element_by_xpath("//input[@class='cur-page']").clear()####清除输入值
driver.find_element_by_xpath("//input[@class='cur-page']").send_keys(i)###设置跳转页面编号
driver.find_element_by_xpath("//input[@class='cur-page']").send_keys(Keys.ENTER,'\ue007')#回车键
time.sleep(2)
result_text=result_text+driver.find_element_by_xpath("//div[@id='pageNo-{0}']".format(i)).text####得到页面的文本
time.sleep(2)
i+=1
result_text=result_text.replace("\n","")
zf=0
while zf<=9:
s=str(zf)+"、"
#print (s)
result_text=result_text.replace(s,"\n"+s)
zf+=1
for zf_s in ('一','二','三','四','五','六','七','A','B','C','D','E'):
s=zf_s+"、"
t=zf_s+"."
result_text=result_text.replace(s,"\n"+s).replace(t,"\n"+t)
result_text=result_text.replace("\n\n","\n")
docx_path="老舍研究.docx"
doc=Document()
doc.styles["Normal"].font.name = u"微软雅黑"#设置字体样式
doc.styles["Normal"].font.size = Pt(14)#设置字体大小
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑')#设置文档的基础样式
doc.add_paragraph(result_text)#增加一个paragraph,写入内容
doc.save(docx_path)#保存文档