python提取word表格中数据
程序分析
今天文章介绍一个实战案例,与自动化办公相关;案例思想是源于前两天帮读者做了一个 demo ,需求大致将一上百个 word 中表格内容提取出来(所有word 中表格样式一样),把提取到的内容自动存入 Excel 中。
原文地址 作者:zeroing
程序源码
from win32com import client as wc
import os
import pandas as pd
import docx
path="C:\\Users\Lenovo\PycharmProjects\infoexarct\\table\\" #设置文件的目录
def doc_to_docx(path):
path_list = os.listdir(path)
doc_list = [os.path.join(path,str(i)) for i in path_list if str(i).endswith('doc')]
word = wc.Dispatch('Word.Application')
wordlist_path=[]
print("正在读取文件目录....")
for doc_path in doc_list:
doxc_path_save=doc_path.replace(path,"C:\\Users\Lenovo\PycharmProjects\infoexarct\\table\\temp\\")
save_path = str(doxc_path_save).replace('doc','docx')
doc = word.Documents.Open(doc_path)
doc.SaveAs(save_path,12, False, "", True, "", False, False, False, False)
doc.Close()
wordlist_path.append(save_path)
print('{} Save sucessfully '.format(save_path))
word.Quit()
print("文件转换已完成,开始分析文件....")
return wordlist_path
def GetData_frompath(save_path):
document = docx.Document(save_path)
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
if (col_index==4 and row_index<7) :
continue
# print(' pos index is ({},{})'.format(row_index, col_index))
# print('cell text is {}'.format(cell.text))
if row_index<7:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
else:
if col_index >0 :
break
else:
if index_num % 2 == 0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num += 1
col_keys.pop(3)
col_values.pop(3)
col_values[11] = '\t' + col_values[11]
# print(f'col keys is {col_keys}')
# print(f'col values is {col_values}')
return col_keys,col_values
def create_csv(wordlist_path):
pd_data = []
for index,single_path in enumerate(wordlist_path):
col_names,col_values = GetData_frompath(single_path)
print(f"已录入{index+1}名学生信息")
if index == 0:
pd_data.append(col_names)
pd_data.append(col_values)
else:
pd_data.append(col_values)
df = pd.DataFrame(pd_data)
#csv_path="C:\\Users\Lenovo\PycharmProjects\infoexarct\\finsh.csv"
# df.to_csv(csv_path, encoding='utf_8_sig',index=False,header=None)
df.to_excel('data.xlsx', sheet_name='工作表1',index=False,header=None)
print("程序执行结束.....")
wordlist_path=doc_to_docx(path)
create_csv(wordlist_path)
常见错误
from win32com import client as wc
word = wc.Dispatch(‘Word.Application’)
安装包 pip install pypiwin32
如果报错 DLL load failed while importing win32api:找不到指定的模块

那么我们可以找到自己安装的环境的脚本目录 ,一般在python安装环境的
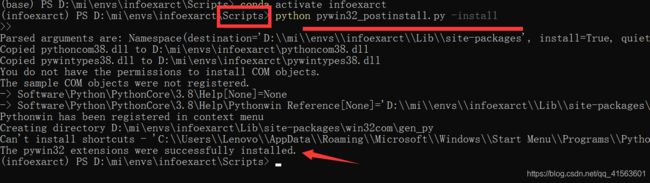
运行一下命令 python pywin32_postinstall.py -install 就安装完成了
安装处理docx的包
pip install docx
报错 from exceptions import PendingDeprecationWarning
ModuleNotFoundError: No module named ‘exceptions’
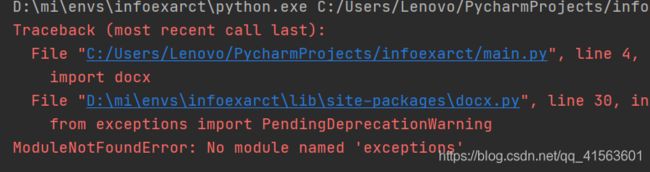
python3.x版本移除了exceptions模块,但是docx包中引用了该模块
安装最新版python-docx模块即可
#1 pip install python-docx安装问题解决
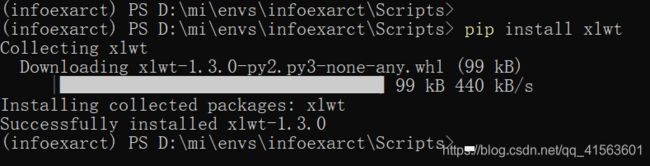
modulenotfounderror: no module named 'xlwt’解决方案 python padans 输出excel出错