【Python实践】关于python多任务设计基础
据说,看我文章时 关注、点赞、收藏 的 帅哥美女们 心情都会不自觉的好起来。
前言:
作者简介:大家好我是 user_from_future ,意思是 “ 来自未来的用户 ” ,寓意着未来的自己一定很棒~
✨个人主页:点我直达,在这里肯定能找到你想要的~
专栏介绍:Python实践 ,一个专注于分享实际案例的专栏~
专栏文章直链:
【Python实践】你可能没有见过的码代码小技巧1
史上最最最没用程序——自写平衡化学方程式
Python进阶——对Python“脚本”的理解与使用
十大排序算法整理(含JavaScript版本与Python版本源码)
从常用实例学习正则2
从常用实例学习正则1
自制小功能——cmd中的规则加密输入
文件目录操作实例2
文件目录操作实例1

关于python多任务设计基础
- 前言
- 概念介绍
-
- 进程、线程、协程之间的区别
-
- 进程、线程之间的区别
- 线程、协程之间的区别
- 进程、线程、协程之间的联系
- 多进程、多进程与协程的优缺点
- 串行、并行与并发的区别
- 同步、异步与阻塞、非阻塞的区别
- 同步、异步与阻塞、非阻塞的联系
- 协程程序的简单设计
-
- 先简单了解一下生成器
- 为什么生成器对象占用内存这么小
- 一个协程程序的诞生
- 一个可以用来接收数据协程程序的诞生
- 一个稍微实际一点的例子
- 关于生成器中需要终止生成提前结束
- 关于上面生成器的两个小栗子
-
- `yield` 与 `return` 共存
- `for` 循环中 `next` 操作
- 栗子解答
- 常见协程库的使用
-
- 协程模块有哪些
- `asyncio` 模块与 `async` / `await` 关键字
- `greenlet` 模块
- `gevent` 模块
-
- 认识 `gevent` 模块
- 多协程并发下载器
- 协程加锁
- 协程池
- 多线程程序的简单设计
-
- GIL锁
- 多线程模块
- 启动多线程、多线程加锁
- 线程池
- 线程间通信
- 线程安全
- 多进程程序的简单设计
-
- 启动多进程、多进程加锁、多进程通信
- 进程池
- 总结
- 结束语
前言
经详细阅读有关 “ 协程、线程、进程,同步、异步,并发、并行,堵塞、非堵塞,IO密集型、CPU密集型 ” 的各类资料,并再次整理成本篇文章,力求结合实际素材全面整理。
本文中的栗子说明是以博主自己所想为基准所写,适合阅读,但可能不太适合直观的参考。
本文可能比较会比你看到过的大部分文章都长,建议收藏后慢慢看。
概念介绍
- 进程:
- 应用程序的启动实例,比如运行一个游戏,打开一个软件、跑一个程序。
- 操作系统分配资源的最小单位,拥有代码文本、被分配的系统资源、独立的虚拟内存地址、堆栈空间。
- 线程:
- CPU调度和分配的最小单位,拥有自己的栈空间。
- 从属于进程,主抓 CPU 执行代码的过程,它可以被抢占(中断)和临时挂起(睡眠)。
- 协程:
- 线程的优化,实现多任务的同步,而又不用加锁。
- 不被操作系统内核所管理,而完全是由程序所控制。
- 同步:
- 一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会 一直等待下去,直到收到返回信息才继续执行下去。
- 异步:
- 进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态,当有消息返回式系统会通知进程进行处理,这样可以提高执行的效率。
- 并发:
- 实际并不是同时执行。
- 一个 CPU 通过在任务间快速切换(时分交替执行),达到多任务”一起”执行的错觉。
- 并行:
- 实际是真正的同时执行。
- 每个任务都有不同 CPU 去执行(利用多核性能),达到多任务一起执行。
- 堵塞:
- 从调用者的角度出发,如果在调用的时候,被卡住,不能再继续向下运行,需要等待。
- 非堵塞:
- 从调用者的角度出发, 如果在调用的时候,没有被卡住,能够继续向下运行,无需等待。
- IO密集型:
- 指系统的CPU性能相对硬盘性能、内存性能的需求要高很多。此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU使用率并不高。
- CPU密集型:
- 也叫计算密集型,指对系统的硬盘性能、内存性能相对CPU性能的需求要高很多。此时,系统运作大部分的状况是CPU使用率100%。即使CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU使用率很高。
进程、线程、协程之间的区别
- 进程切换需要的资源最大,效率很低。
- 线程切换需要的资源一般,效率一般。
- 协程切换需要的资源很小,效率很高。
进程、线程之间的区别
- 一个进程至少有一个主线程。
- 进程是操作系统资源分配的单位,线程是CPU调度的单位。
- 进程是资源分配的最小单位,线程是CPU调度的最小单位.。
- 同一个进程中的线程共享同一内存空间,但是进程之间是独立的。
- 创建新的线程很容易,但是创建新的进程需要对父进程做一次复制。
- 线程启动速度快,进程启动速度慢(但是两者运行速度没有可比性)。
- 一个线程可以操作同一进程的其他线程,但是进程只能操作其子进程。
- 由于线程之间能够共享地址空间,因此,需要考虑线程的同步和互斥操作。
- 同一个进程中的所有线程的数据是共享的(进程通讯),进程之间的数据是独立的。
- 同一个进程的线程之间可以直接通信,但是进程之间的交流需要借助中间代理(队列)来实现。
- 对主线程的修改可能会影响其他线程的行为,但是父进程的修改(除了删除以外)不会影响其他子进程。
- 一个线程的意外终止会影响整个进程的正常运行,但是一个进程的意外终止不会影响其他的进程的运行。因此,多进程程序安全性更高。
- 进程是资源的分配和调度的独立单元。进程拥有完整的虚拟地址空间,当发生进程切换时,不同的进程拥有不同的虚拟地址空间。而同一进程的多个线程是可以共享同一地址空间。
线程、协程之间的区别
- 线程进程都是同步机制,而协程则是异步。
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态。
- 一个线程可以有多个协程,一个进程也可以单独拥有多个协程,通过多进程 + 多协程,python中能使用多核CPU。
进程、线程、协程之间的联系
进程和线程都有五种基本状态:
- 初始状态:进程(线程)刚被创建,由于其他进程(线程)正占有CPU所以得不到执行,只能处于初始状态。
- 执行状态:任意时刻处于执行状态的进程(线程)只能有一个。
- 就绪状态:只有处于就绪状态的经过调度才能到执行状态。
- 等待状态:进程(线程)等待某件事件完成。
- 停止状态:进程(线程)结束。

每启动一个程序,操作系统都会创建一个主进程,可能有其他子进程。每个进程里有一个主线程,可能有其他子线程。每个线程里可能有若干协程,是一种用户态的轻量级线程,协程又被称作:微线程、纤程。
多任务的实现原理就是如此,设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,所以多任务的环境下,通常是一个Master和多个Worker,主进程、主线程就是Master,子进程、子线程就是Worker。
多进程、多进程与协程的优缺点
- 多进程:
- 优点:
- 稳定性高:一个子进程崩溃了,不会影响主进程和其他紫禁城,当然主进程挂了那所有进程就全挂了,但通常主进程只负责分配任务,挂掉的概率低。
- 缺点:
- 创建进程的代价大:在Unix/Linux系统下,用fork调用还行,但在Windows下创建进程开销巨大。
- 操作系统能同时运行的进程数是有限的:在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会非常困难。
- 优点:
- 多线程:
- 优点:
- 程序设计简单、响应更快。
- 在Windows下,多线程的资源利用效率比多进程要高。
- 多线程模式通常比多进程快一点,但是也快不到哪里去。
- 缺点:
- 任何一个线程挂掉都可能直接造成整个进程崩溃:可能有这样的提示“该程序执行了非法操作,即将关闭”。
- 优点:
- 协程:
- 优点:
- 方便切换控制流,简化编程模型。
- 单线程内就可以实现并发的效果,最大限度地利用cpu。
- 高并发 + 高拓展性 + 低成本,一个CPU可以支持上万个协程。
- 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级,提高的性能。
- 缺点:
- 协程指的是单个线程,因而一旦协程出现堵塞,将会堵塞整个线程。
- 协程的本质是单线程下,无法利用多核。但协程可以和进程匹配使用运行在多CPU上,一般除非是CPU计算密集型应用,不然不需要。
- 优点:
串行、并行与并发的区别

同步、异步与阻塞、非阻塞的区别
- 同步、异步与阻塞、非阻塞不相关。
- 同步与异步区别在于:调用者是否得到了想要的最终结果。
- 阻塞与非阻塞的区别在于,调用者是否还能干其他的事情。
- 同步、异步强调的是结果。阻塞和非阻塞强调的是时间,是否等待。。
- 阻塞,调用者只能干等。非阻塞,调用者可以先忙别的事情,不用一直等。
- 同步就是一直要执行到返回最终结果。异步就是直接返回了,但是返回的不是最终的结果,调用者不能通过这种调用得到结果,还要通过被调用者,使用其他方式通知调用者,来取回最终结果。
同步、异步与阻塞、非阻塞的联系
同步阻塞:调用者阻塞,直到等到拿到最终结果。
同步非阻塞:在等待的过程中可以干点其他事情,干其他事情的间隙看看结果。
异步阻塞:调用者阻塞,直到收到最终结果通知。
异步非阻塞:在等待的过程中可以干点其他事情,最终结果出来会通知调用者。
协程程序的简单设计
在这里我们将用学驾照科目三所用的三段话来见证我们多任务设计:多语句打印。
我们将三句话分为三个列表,如下:
# 起步动作1挂空档2启动发动机3打转向灯4挂1档5松手刹起步走同时观察
start_steps = [
'挂空档',
'启动发动机',
'打转向灯',
'挂1档',
'松手刹起步走同时观察'
]
# 起步用1档,移动两个车身加2档,25码左在加3档,40码左右加4档,45码加5档,50码以上必须加5档
speed_steps = [
'起步用1档',
'移动两个车身加2档',
'25码左右加3档',
'40码左右加4档',
'45码左右加5档',
'50码以上必须加5档'
]
# 停车动作:1关转向灯,2拉手刹,3挂空档,4熄火,5挂1档,6松安全带,7观察右手开门下车
stop_steps = [
'关转向灯',
'拉手刹',
'挂空档',
'熄火',
'挂1档',
'松安全带',
'观察右手开门下车'
]
接下来就让我们来使用这些数据疯狂输出吧!
先简单了解一下生成器
import sys
start_steps = [
'挂空档',
'启动发动机',
'打转向灯',
'挂1档',
'松手刹起步走同时观察'
]
speed_steps = [
'起步用1档',
'移动两个车身加2档',
'25码左右加3档',
'40码左右加4档',
'45码左右加5档',
'50码以上必须加5档'
]
stop_steps = [
'关转向灯',
'拉手刹',
'挂空档',
'熄火',
'挂1档',
'松安全带',
'观察右手开门下车'
]
all_steps = start_steps + speed_steps + stop_steps
def yield_function(steps):
for item in steps:
yield item
function = yield_function(all_steps)
print(function)
print(sys.getsizeof(function))
print(sys.getsizeof(yield_function(start_steps)))
print(sys.getsizeof(start_steps))
print(sys.getsizeof(all_steps))
for index, step in enumerate(all_steps):
print(str(index + 1) + "、" + step)
在函数中有yield 关键字的,那这个函数就成为了生成器。yield 关键字不同于 return 关键字,如果相同位置换成 return 关键字 ,那只会返回列表的第一个,就不再执行了,但是这里的 yield 关键字只要还有下一个元素,就能一直等待继续运行。上述代码运行结果:
120
120
104
208
1、挂空档
2、启动发动机
3、打转向灯
4、挂1档
5、松手刹起步走同时观察
6、起步用1档
7、移动两个车身加2档
8、25码左右加3档
9、40码左右加4档
10、45码左右加5档
11、50码以上必须加5档
12、关转向灯
13、拉手刹
14、挂空档
15、熄火
16、挂1档
17、松安全带
18、观察右手开门下车
可以看到第 1 行代表了函数对象 yield_function 是个generator 对象。
第 2-5 行是对象所占用内存空间的大小,可以看到不管传入多大的列表,生成器对象占用的内存大小始终是 120 ,但列表对象占用的内存大小是跟其本身长度成正比的,列表越长,列表对象占用内存越大,所以遇到大量数据时,为了减轻你电脑内存条压力,使用 yield 返回生成器对象吧!
后面的是打印了列表所有的元素。
为什么生成器对象占用内存这么小
生成器,顾名思义,是用来生成的,所以他并不直接将数据写入内存,而是将数据是如何生成出来的方式写入内存,读取的时候就执行一次生成的方式,就能获取数据,这也是为什么生成器对象占用空间大小很小的原因。
这里 for 循环生成器,实际上一直在调用 next(step) ,也就是调用 step.__next__() 方法,直到当生成器运算到结尾没有下一个元素并抛出 StopIteration 异常的时候,结束继续生成。
一个协程程序的诞生
到上面为止暂时和 for 循环好像还没什么区别,接下来开始 巴啦啦能量,生成器全身变 :
import time
from functools import partial
start_steps = [
'挂空档',
'启动发动机',
'打转向灯',
'挂1档',
'松手刹起步走同时观察'
]
def yield_toggle(text):
while True:
print(text)
yield
time.sleep(0.5)
yield1 = partial(yield_toggle, text="1、" + start_steps[0])
yield2 = partial(yield_toggle, text="2、" + start_steps[1])
yield3 = partial(yield_toggle, text="3、" + start_steps[2])
yield4 = partial(yield_toggle, text="4、" + start_steps[3])
yield5 = partial(yield_toggle, text="5、" + start_steps[4])
y1 = yield1()
y2 = yield2()
y3 = yield3()
y4 = yield4()
y5 = yield5()
while True:
next(y1)
next(y2)
next(y3)
next(y4)
next(y5)
这里的 functools.partial 方法主要是用来生成函数的,根据给的 text 值的不同生成不同的函数,相当于五个函数,每个函数都 pinrt 一句不同的话,来模拟五个输出任务。
执行结果很“长”:
1、挂空档
2、启动发动机
3、打转向灯
4、挂1档
5、松手刹起步走同时观察
1、挂空档
2、启动发动机
3、打转向灯
4、挂1档
5、松手刹起步走同时观察
1、挂空档
...
后面自然是无限循环了,自然很“长”,来看下代码,这里相当于实现五个不同函数的轮流调用,通过yield 关键字 “ 挂起” ,然后执行其他函数,然后再 “ 挂起” …这也就是协程的简单理解。
当然这里面我们的数据只能在函数内定义,用处也不大,现在代码处理的不都是从外部接收的数据嘛,接下来,就让外面的数据进到函数里面,实现 “外面提供什么,里面就接收什么”。
一个可以用来接收数据协程程序的诞生
先上代码:
import time
speed_steps = [
'起步用1档',
'移动两个车身加2档',
'25码左右加3档',
'40码左右加4档',
'45码左右加5档',
'50码以上必须加5档'
]
def yield_loop():
date = ''
for prefix in ['1、', '2、', '3、', '4、', '5、', '6、']:
res = yield date
print(prefix + res)
time.sleep(0.5)
yield
t = yield_loop()
t.send(None)
for step in speed_steps:
t.send(step)
这段代码就简短的打印了速度匹配,运行结果如下:
1、起步用1档
2、移动两个车身加2档
3、25码左右加3档
4、40码左右加4档
5、45码左右加5档
6、50码以上必须加5档
观察到这里 yield 后面跟了个变量,如果从生成器的 for 循环中打印元素,那只能打印出一堆空白,但他返回的同时也会接收参数,如果你在下面使用 generator.send(XXX) 的话。
所以如果一个函数中出现了 res = yield data ,那么 data 就是返回的值,同时会接收 generator.send(XXX) 传入的参数值,并将参数值赋值给 res 变量,可以用来打印等处理。
注意这里要使用 generator.send(None) 来启动生成器(此时 generator.send(None) 返回的是 date 的初始化值)。
为什么要在最后再单独加个 yield 呢?这里实际上是因为生成器在启动后就会 延时返回参数 ,意思就是先会接收传入的值,等到代码再次执行到 yield 时再返回当前的 date 变量值,所以最后加个 yield 是让他最后返回一次参数,这样上下等数循环时,就不会出现 StopIteration 异常了。
一个稍微实际一点的例子
还是一样,先看代码:
import time
stop_steps = [
'关转向灯',
'拉手刹',
'挂空档',
'熄火',
'挂1档',
'松安全带',
'观察右手开门下车'
]
def yield_function():
date = '[语音提示:]请靠路边停车。'
for operate in stop_steps:
res = yield date
if res != operate:
yield f'[语音提示:]考生未 “{operate}” , 扣 100 分,成绩不合格。'
else:
date = f"{'[考生操作:]' if date == '[语音提示:]请靠路边停车。' else f'{date[:-1]},'}{res}。"
time.sleep(1)
yield f'{date}\n[语音提示:]成绩合格,成绩 100 分,请回考试中心打印成绩单。'
t = yield_function()
print(t.send(None))
for step in stop_steps:
req = t.send(step)
print('\r' + req, end='')
if req.endswith('成绩不合格。') or req.endswith('成绩单。'):
break
上面的代码稍微看看应该能看出来,这是一个模拟科目三语音提示和考生操作的例子,模拟的是考试通过的例子,最终的运行的结果就三行:
[语音提示:]请靠路边停车。
[考生操作:]关转向灯,拉手刹,挂空档,熄火,挂1档,松安全带,观察右手开门下车。
[语音提示:]成绩合格,成绩 100 分,请回考试中心打印成绩单。
假如让外部输入的操作内容变一变,比如少掉挂1挡这个操作,最后控制代码变成如下代码:
t = yield_function()
print(t.send(None))
steps = stop_steps[:4] + stop_steps[5:]
for step in steps:
req = t.send(step)
print('\r' + req, end='')
if req.endswith('成绩不合格。') or req.endswith('成绩单。'):
break
就变成了两行考试不通过的情景:
[语音提示:]请靠路边停车。
[语音提示:]考生未 “挂1档” , 扣 100 分,成绩不合格。
现在可以多给一条,在正常操作之外再给一条操作,试试他会不会报错,最后控制代码修改如下:
t = yield_function()
print(t.send(None))
for step in stop_steps + ['跟安全员摆手再见']:
req = t.send(step)
print('\r' + req, end='')
if req.endswith('成绩不合格。') or req.endswith('成绩单。'):
break
依然是三行考试通过:
[语音提示:]请靠路边停车。
[考生操作:]关转向灯,拉手刹,挂空档,熄火,挂1档,松安全带,观察右手开门下车。
[语音提示:]成绩合格,成绩 100 分,请回考试中心打印成绩单。
从这个例子我们可以看出来,我们此时由 yield 关键字构成的生成器已经可以和外部输入的操作内容正常交互了,可以一边接收数据一边检验数据,这就是协程的方便之处,不然你只能等到所有操作都操作完(获取到一个结果列表),你才能统一分析(比如你当中有步骤做错了,等到全部做完才会有结果,协程让你边做边判断结果)。慢慢琢磨这个例子,能让你了解 yield 关键字是如何接收参数值和传出变量值的。
关于生成器中需要终止生成提前结束
在函数中一旦有 yield 关键字,那么这个函数就变成了一个生成器。一般我们想要提前结束生成器就会想到 return 关键字,但如果运行到 return 关键字时还在使用 next() 函数来获取值,肯定会报 StopIteration 异常,因为对于 yield 关键字已经完成了所有返回,所以 next() 无法再等到 yield 关键字的返回所以报错,不过如果使用 for 循环那就会自动捕获异常且终止生成器生成。
但对于使用 generator.send() 方法传递参数的生成器来说,最好的方式还是通过外部捕获返回的值,当接收到的返回值是结束信号,那就能提前结束生成器。上面例子中的 if req.endswith('成绩不合格。') or req.endswith('成绩单。') 就是判断结束的条件,是否返回成绩合格不合格相应的字符串,当然我们也可以多个返回值,来进行判断,比如将程序改成:
import time
stop_steps = [
'关转向灯',
'拉手刹',
'挂空档',
'熄火',
'挂1档',
'松安全带',
'观察右手开门下车'
]
def yield_function():
date = '[语音提示:]请靠路边停车。'
for operate in stop_steps:
res = yield date, 0
if res != operate:
yield f'[语音提示:]考生未 “{operate}” , 扣 100 分,成绩不合格。', 1
else:
date = f"{'[考生操作:]' if date == '[语音提示:]请靠路边停车。' else f'{date[:-1]},'}{res}。"
time.sleep(1)
yield f'{date}\n[语音提示:]成绩合格,成绩 100 分,请回考试中心打印成绩单。', 1
t = yield_function()
print(t.send(None)[0])
for step in stop_steps + ['跟安全员摆手再见']:
req, code = t.send(step)
print('\r' + req, end='')
if code:
break
此时生成器中返回了提示字符串还有是否结束的标志位,在有结果的 yield 后面返回 1 这个状态,在没有结果的 yield 后面返回 0 这个状态。这样外部控制语句只需要判断返回的 code 是否为 1 ,就知道是否可以结束生成器的生成。
关于上面生成器的两个小栗子
接下来有两个 “不一般” 的小栗子,看看他会不会如你所想的执行:
yield 与 return 共存
# 为了不把答案同屏显示,此注释用于给代码块增高。
# 为了不把答案同屏显示,此注释用于给代码块增高。
# 为了不把答案同屏显示,此注释用于给代码块增高。
# 为了不把答案同屏显示,此注释用于给代码块增高。
def yield_function():
return 6
for i in range(6):
yield i
y = yield_function()
print(y)
猜猜这个 y 收到的值是什么?
for 循环中 next 操作
# 为了不把答案同屏显示,此注释用于给代码块增高。
# 为了不把答案同屏显示,此注释用于给代码块增高。
# 为了不把答案同屏显示,此注释用于给代码块增高。
# 为了不把答案同屏显示,此注释用于给代码块增高。
def yield_function():
for i in range(6):
yield i
y = yield_function()
for t in y:
print(next(y))
猜猜这段代码会打印出来什么?
栗子解答
栗子1:y 的值是:
栗子2:返回结果如下:
1
3
5
怎么样,你都想对了吗?初学者不出意外想到的 y 的值是 6,返回结果是 1-6 ,答案有没有刷新你们的小脑袋瓜?
这里的函数虽然 return 写在了 yield 上面,但不管 yield 有没有被运行到,有 yield 就是生成器,不管这段代码会不会被运行,哪怕他下面的代码块都被编辑器标黄表示不会运行那段代码了:

所以 return 写在 yield 上面,你是什么返回值都获取不到,用 next() 函数反而还会给你一个 StopIteration 异常。
至于下面的for 循环中 next 为什么会获取偶数呢,这要从 for 循环对迭代器(生成器是一种特殊的迭代器)的运行机制说起了。
迭代器肯定是可迭代对象,但可迭代对象不一定是迭代器,从组成来说,可迭代对象一定有 __iter__() 方法,但迭代器除了拥有这个方法,还有 __next__() 这个方法。对于 for 循环来说,他会自动调用 next() 函数,也就是迭代器的 __next__() 方法,当捕获到 StopIteration 异常之后,就会停止调用 next() 函数并结束循环。
所以在栗子2中, for 循环每次进去循环体都会调用一次 next() 函数,这样生成器中就执行到第二次,所以循环体中调用 next() 函数返回 1,之后一样,只会打印偶数次调用生成器。原本生成的是 0-5,偶数位置就是 1、3、5 了,所以他只会打印偶数数字。
常见协程库的使用
上面那些设计,你会感觉到使用一个普通函数也能完成这项操作,但不要急,这是因为仅仅使用了一个 yield 关键字,所以功能不够强大。接下来该我们专业的协程库上场了,专业的协程库能让我们真正体会到使用协程的好处:
协程模块有哪些
协程最主要的两个关键字是: async / await ,然后还有上文所述的 yield 关键字。
asyncio:异步IO模块。greenlet:核心还是yield关键字。gevent:更强大,更常用。- 其他异步框架:
aiohttp:基于异步IO模块实现的HTTP框架。aiomysql:异步操作mysql。aioredis:异步操作redis。
接下来我们来一个个的使用尝试。
asyncio 模块与 async / await 关键字
asyncio 模块是 python3.4 版本开始引入的标准库,直接内置了对异步IO的操作。
编程模式:是一个消息循环,我们从 asyncio 模块中直接获取一个 EventLoop 的引用,然后把需要执行的协程扔到 EventLoop 中执行,就实现了异步。
接下来请欣赏一段自己编写的小栗子:( 代码是编的,但知识是实实在在的~ )
import time
import asyncio
def callback(future):
res = future.result()
print(f'{res} \t[当前用时:{time.time() - now:.2f}秒]')
async def boil_water():
print("开始烧水...")
await asyncio.sleep(10)
return "水烧开了"
async def wash_vegetables():
print("叫孩子过来洗菜...")
await asyncio.sleep(20)
return "菜洗好了"
async def cook():
global fan
print("开始热饭...")
await asyncio.sleep(40)
fan = True
return "饭热好了"
async def cooking():
global cai
while not task3.done():
await asyncio.sleep(0.2)
print("开始烧菜...")
await asyncio.sleep(30)
cai = True
return "菜烧好了"
async def set_the_cutlery():
global tool
while not task3.done():
await asyncio.sleep(0.2)
print("叫孩子过来摆放餐具...")
await asyncio.sleep(4)
tool = True
return "餐具摆放好了"
async def have_a_meal():
while not (fan and cai and tool):
await asyncio.sleep(0.2)
print("开始吃饭...")
await asyncio.sleep(15)
now = time.time()
cai = False # 是否烧好菜
fan = False # 是否热好饭
tool = False # 是否摆放好餐具
print('一个家庭吃一顿饭的全过程。 \t[当前用时:0.0 秒]')
task1 = asyncio.ensure_future(cook())
task2 = asyncio.ensure_future(boil_water())
task3 = asyncio.ensure_future(wash_vegetables())
task4 = asyncio.ensure_future(cooking())
task5 = asyncio.ensure_future(set_the_cutlery())
task1.add_done_callback(callback)
task2.add_done_callback(callback)
task3.add_done_callback(callback)
task4.add_done_callback(callback)
task5.add_done_callback(callback)
loop = asyncio.get_event_loop()
loop.run_until_complete(task1)
loop.run_until_complete(task2)
loop.run_until_complete(task3)
loop.run_until_complete(task4)
loop.run_until_complete(task5)
loop.run_until_complete(have_a_meal())
# loop.run_until_complete(asyncio.gather(*[task1, task2, task3, task4, task5, have_a_meal()]))
loop.close()
print(f'很满足这一顿饭~ \t[总共用时:{time.time() - now:.2f}秒]')
这段代码的运行结果就是:
一个家庭吃一顿饭的全过程。 [当前用时:0.0 秒]
开始热饭...
开始烧水...
叫孩子过来洗菜...
水烧开了 [当前用时:10.02秒]
菜洗好了 [当前用时:20.00秒]
开始烧菜...
叫孩子过来摆放餐具...
餐具摆放好了 [当前用时:24.08秒]
饭热好了 [当前用时:40.01秒]
菜烧好了 [当前用时:50.08秒]
开始吃饭...
很满足这一顿饭~ [总共用时:65.10秒]
其中,loop.run_until_complete(asyncio.gather(*[task1, task2, task3, task4, task5, have_a_meal()])) 这一行顶的上上面 6 行代码,可以统一添加到消息循环中。通过将多人不同耗时任务分割,最终以最短时间完成所有操作,接下来来分析一下上面这段代码每个操作的耗时以及如何运行的。
首先来看每一个操作单独要多长时间:(请不要在意数据的真实性,毕竟是为了执行快点编造的~)
热饭:40秒
烧水:10秒
洗菜:20秒
烧菜:30秒
摆放餐具:4秒
吃饭:15秒
如果按顺序一件事一件事的来,那总共需要40+10+20+4+15=119秒,而看看协程,只用了65秒。
为什么相差时间这么多呢,来看一下“家长”和“孩子”在各个时间段的分工:

如图所示,这里所写的堵塞和非堵塞是相对的,我把机器运行认为是非堵塞(异步,只需要获取结果),因为期间人能自由做其他事(同步,人得专心做完一件事再做另外一件事);
但如果你把每个机器当个人看,那全都是堵塞的,因为机器同一时间只能干一个活,那这里就相当于是好多人在同时干活。
接下来分析代码,需要先了解一些基础知识:
asyncio.sleep():这是协程专用的等待,和time.sleep()最大的区别就在于,asyncio.sleep()它不会堵塞线程,而是会切换到事件循环中的其他没有协程等待的事件中去;但time.sleep()会堵塞线程。经过上文我们知道,协程是个微线程,既然被堵塞了线程,那协程还能切换并继续运行吗?肯定不行了,因为被一起堵塞了。asyncio.ensure_future(function):可以将协程函数封装成Task对象,从而可以使用添加回调函数等操作。asyncio.get_event_loop():获取事件循环,自动切换不同任务(遇堵塞就切换任务)。loop.run_until_complete(function):将任务添加到循环中,保持运行直到结束任务。
使用装饰生成器( @asyncio.coroutine 装饰有 yield from 的函数实现协程),对于**Python3.5+**版本,从实用的角度来看,已经不建议使用了(比如:遇到IO堵塞不会自动切换)。主要原因是 async / await 关键字实现起来比之更简单,且功能更加强大和灵活。
协程所作的事就是,不断的检查是否发生IO操作等堵塞,如果发生堵塞,那就将CPU资源让给下一位,循环一圈后再来检测是否IO操作等堵塞或者执行完毕。
greenlet 模块
首先说一说我第一次使用这个模块有什么感受:我感觉我能自由切换想要的程序,而且切换的代码很直观,不过它没法自动跳过IO阻塞。可以预先设置好切换方式,不像之前携程的 send() 方法,使用起来没有那么顺手。
接下来是一段由上方代码修改后的栗子:
import time
import greenlet
from functools import partial
start_steps = [
'挂空档',
'启动发动机',
'打转向灯',
'挂1档',
'松手刹起步走同时观察'
]
def function(text):
while True:
print(text, f'\033[31my{int(text[0]) + 1 if int(text[0]) < 5 else 1}.switch()\033[0m')
eval(f'y{int(text[0]) + 1 if int(text[0]) < 5 else 1}').switch()
time.sleep(0.5)
yield1 = partial(function, text="1、" + start_steps[0])
yield2 = partial(function, text="2、" + start_steps[1])
yield3 = partial(function, text="3、" + start_steps[2])
yield4 = partial(function, text="4、" + start_steps[3])
yield5 = partial(function, text="5、" + start_steps[4])
y1 = greenlet.greenlet(yield1)
y2 = greenlet.greenlet(yield2)
y3 = greenlet.greenlet(yield3)
y4 = greenlet.greenlet(yield4)
y5 = greenlet.greenlet(yield5)
y1.switch()
这是他的运行结果,右边是切换方式,有颜色但这上面不好显示,这里偷懒了点,都放一块执行了。
1、挂空档 y2.switch()
2、启动发动机 y3.switch()
3、打转向灯 y4.switch()
4、挂1档 y5.switch()
5、松手刹起步走同时观察 y1.switch()
1、挂空档 y2.switch()
2、启动发动机 y3.switch()
3、打转向灯 y4.switch()
4、挂1档 y5.switch()
5、松手刹起步走同时观察 y1.switch()
1、挂空档 y2.switch()
...
上面使用的是 switch() 不带参数,所以代码可能多了点,下面使用 switch() 传递函数初始值,再来看看:
import time
import greenlet
start_steps = [
'挂空档',
'启动发动机',
'打转向灯',
'挂1档',
'松手刹起步走同时观察'
]
def function(text):
while True:
next_index = int(text[0]) + 1 if int(text[0]) < 5 else 1
print(text, f'\033[31my{next_index}.switch(\'{next_index}、{start_steps[next_index - 1]}\')\033[0m')
eval(f'y{next_index}').switch(f'{next_index}、{start_steps[next_index - 1]}')
time.sleep(0.5)
(y1, y2, y3, y4, y5) = (greenlet.greenlet(function) for _ in range(5))
y1.switch("1、" + start_steps[0])
这是他的运行结果,右边是切换方式,有颜色但这上面不好显示。我这是越来越偷懒了…
1、挂空档 y2.switch('2、启动发动机')
2、启动发动机 y3.switch('3、打转向灯')
3、打转向灯 y4.switch('4、挂1档')
4、挂1档 y5.switch('5、松手刹起步走同时观察')
5、松手刹起步走同时观察 y1.switch('1、挂空档')
1、挂空档 y2.switch('2、启动发动机')
2、启动发动机 y3.switch('3、打转向灯')
3、打转向灯 y4.switch('4、挂1档')
4、挂1档 y5.switch('5、松手刹起步走同时观察')
5、松手刹起步走同时观察 y1.switch('1、挂空档')
1、挂空档 y2.switch('2、启动发动机')
...
使用下来有几点需要注意:
greenlet创建之后,一定要结束,不能switch()出去就不回来了,否则容易造成内存泄露。- python 中每个线程都有自己的主协程 ,不同线程之间的协程是不能相互切换的。
- 不能存在循环引用,就是不能你引用我,我引用你。这个是官方文档明确说明:Greenlets do not participate in garbage collection; cycles involving data that is present in a greenlet’s frames will not be detected. 。
gevent 模块
认识 gevent 模块
自从有了 yield 关键字,协程诞生了,但 yield 关键字设计程序过于复杂并且不具备良好的代码理解。所以 greenlet 模块就出现了,但他仍然继承了 yield 关键字的缺点——无法自动切换IO密集等堵塞情况,还得程序员手动设计代码。
于是乎, gevent 模块横空出世,既能方便设计出友好的代码,又能自动切换IO密集等堵塞情况,使用也简单,全都添加到主协程上去就可以了。比较适合用于代码没有运行顺序要求(比如并发下载、并发加载网页)的情况。
提到这个库,不得不先说一下里面的monkey插件,他必须写在所有导入库的语句后面,能自动替换掉导入模块中所有会堵塞线程的部分,接下来来看一下他的原理:
import time
import gevent
from gevent import time as time_
from gevent import monkey
print(time.sleep)
monkey.patch_all()
print(time.sleep)
print(time_.sleep)
print(gevent.sleep)
通过这段代码可以看到,原先的 time.sleep 是一个内置的方法,但经过 monkey.patch_all() 后,他就变成了一个自定的函数方法,其原理就是替换模块属性,展示替换过程如下:
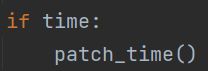
首先会执行patch函数:

里面会有个替换模块的方法,再点进去:
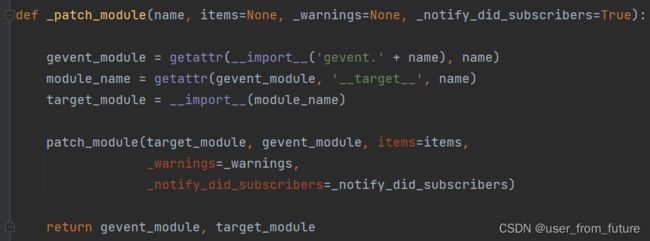
此处的gevent_module 就是从 gevent 中对应的模块对象,在此处的例子就是 gevent.time 模块对象;module_name 是模块的名字,在此处的例子就是 time 字符串;target_module 是原模块对象,在此处的例子就是 time 模块对象。
然后下面的 patch_module 函数就开始正式替换模块的方法:先从 gevent 对应的模块中找到 __implements__ 属性,比如 time 的就是如图下所示:

将 time 的全局属性和方法进行复制,除了堵塞函数方法。
然后将当前文章里的 sleep 方法用 gevent.hub 中的 sleep 方法替换,实际上 gevent.sleep 和 gevent.time.sleep 是同一个函数方法,内存地址都一模一样。

从这里可以看到整个模块里,有非常多的常见子模块,里面的其他方法可以自己进去看看,基本上都被重写了堵塞方法,让 gevent 能够更加方便的运行。
多协程并发下载器
这边举一个使用多协程实现并发下载的小栗子:
import os
import re
import time
import gevent
import requests
from gevent import monkey
from bs4 import BeautifulSoup
monkey.patch_all(ssl=False)
def download(file, url):
if not os.path.isfile(file):
img = requests.get(url)
f = open(file, 'ab')
f.write(img.content)
f.close()
print(f'{file} 保存成功!')
if not os.path.isdir('王者荣耀皮肤'):
os.mkdir('王者荣耀皮肤')
start = time.time()
html = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
html.encoding = 'utf-8'
data = html.json()
all_gevent = []
for d in data:
html = requests.get(f"https://pvp.qq.com/web201605/herodetail/{d['ename']}.shtml")
html.encoding = 'gbk'
soup = BeautifulSoup(html.text, 'html.parser')
skins = soup.find('ul', class_='pic-pf-list pic-pf-list3')
skin_names = [re.findall(r'[\u4E00-\u9FA5]*', r)[0] for r in str(skins['data-imgname']).split('|')][::-1]
for s in range(len(skin_names)):
img_url = f"http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{d['ename']}/{d['ename']}-bigskin-{s+1}.jpg"
img_name = f"王者荣耀皮肤\\{d['cname']}_{skin_names[::-1][s]}{img_url[-4:]}"
all_gevent.append(gevent.spawn(download, img_name, img_url))
# download(img_name, img_url)
gevent.joinall(all_gevent)
print(f'共花时间:{time.time() - start:.2f}')
这里是顺序下载所用的时间:


这里是使用了多协程并发下载所用的时间,相当于前面都使用 .start() 最后使用 .join() 堵塞主线程:


都测了两次,发现使用多协程下载所花的时间明显比顺序下载所花的时间少不少时间,磁盘读写都几乎跑满了。
协程加锁
gevent 也有锁机制,比如示例如下代码:
import gevent
from gevent.lock import Semaphore
sem = Semaphore(1)
public = []
def maker1():
for i in range(0, 10, 2):
sem.acquire()
print(f'maker - {i}')
public.append(str(i))
gevent.sleep(0)
sem.release()
def maker2():
for i in range(1, 11, 2):
sem.acquire()
print(f'maker - {i}')
public.append(str(i))
gevent.sleep(0)
sem.release()
def consumer():
for i in range(10):
print(f'consumer - {i}(GET {".".join(public)})')
gevent.sleep(0)
gevent.joinall([
gevent.spawn(maker1),
gevent.spawn(maker2),
gevent.spawn(consumer)
])
这里的 gevent.joinall() 方法相当于将所有 gevent.spawn() 对象执行一遍 start() 操作,然后在最后等待所有协程完成。
协程锁 Semaphore 有 __enter__ 和 __exit__ 两个方法,所以支持上下文管理,可以使用 with 来自动释放。
在不加锁(所有锁代码注释)时的输出结果是:
maker - 0
maker - 1
consumer - 0(GET 0.1)
maker - 2
maker - 3
consumer - 1(GET 0.1.2.3)
maker - 4
maker - 5
consumer - 2(GET 0.1.2.3.4.5)
maker - 6
maker - 7
consumer - 3(GET 0.1.2.3.4.5.6.7)
maker - 8
maker - 9
consumer - 4(GET 0.1.2.3.4.5.6.7.8.9)
consumer - 5(GET 0.1.2.3.4.5.6.7.8.9)
consumer - 6(GET 0.1.2.3.4.5.6.7.8.9)
consumer - 7(GET 0.1.2.3.4.5.6.7.8.9)
consumer - 8(GET 0.1.2.3.4.5.6.7.8.9)
consumer - 9(GET 0.1.2.3.4.5.6.7.8.9)
在加锁时的输出结果是:
maker - 0
consumer - 0(GET 0)
maker - 2
consumer - 1(GET 0.2)
maker - 4
consumer - 2(GET 0.2.4)
maker - 6
consumer - 3(GET 0.2.4.6)
maker - 8
consumer - 4(GET 0.2.4.6.8)
consumer - 5(GET 0.2.4.6.8)
maker - 1
consumer - 6(GET 0.2.4.6.8.1)
maker - 3
consumer - 7(GET 0.2.4.6.8.1.3)
maker - 5
consumer - 8(GET 0.2.4.6.8.1.3.5)
maker - 7
consumer - 9(GET 0.2.4.6.8.1.3.5.7)
maker - 9
说明加锁可以有效让部分代码完整执行完再跳到其他代码块,而不会因为堵塞自动切换协程,一般情况下是不需要加锁的,除非是那种特殊情况,需要堵塞到完成才能切换其他任务,真实场景比如写入数据库(不等待完成可能会出现查询不到的情况~)。
协程池
关于协程池,引入方式为:from gevent.pool import Pool 。
先举个小栗子:
import os
import re
import time
import requests
from gevent import monkey
from gevent.pool import Pool
from bs4 import BeautifulSoup
monkey.patch_all(ssl=False)
def callback(file):
print(f'{file} 保存成功!')
def download(file, url):
if not os.path.isfile(file):
img = requests.get(url)
f = open(file, 'ab')
f.write(img.content)
f.close()
return file
if not os.path.isdir('王者荣耀皮肤'):
os.mkdir('王者荣耀皮肤')
start = time.time()
html = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
html.encoding = 'utf-8'
data = html.json()
all_gevent = []
pool = Pool(200)
for d in data:
html = requests.get(f"https://pvp.qq.com/web201605/herodetail/{d['ename']}.shtml")
html.encoding = 'gbk'
soup = BeautifulSoup(html.text, 'html.parser')
skins = soup.find('ul', class_='pic-pf-list pic-pf-list3')
skin_names = [re.findall(r'[\u4E00-\u9FA5]*', r)[0] for r in str(skins['data-imgname']).split('|')][::-1]
for s in range(len(skin_names)):
img_url = f"http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{d['ename']}/{d['ename']}-bigskin-{s+1}.jpg"
img_name = f"王者荣耀皮肤\\{d['cname']}_{skin_names[::-1][s]}{img_url[-4:]}"
pool.apply_async(download, args=(img_name, img_url), callback=callback)
print(f'共花时间:{time.time() - start:.2f}')
全部下载完毕所花时间也差不多是三四十秒,偶尔会出现下载很久的情况。个人认为不一定要用协程池,因为协程开销很小,创建很快,对于下载小文件,还没准备创建后面的协程,前面的就下载完毕了,所以这数字可以大,但不可以小,估计有个200下小文件就差不多了,大文件的话可以适当增大。
多线程程序的简单设计
上面说到协程用了很多内容,主要还是因为协程用起来没有线程常见,多线程一般都使用过吧,简单一行命令就能让程序速度“飞”起来(在IO密集型等任务中)~比较简单好上手。本小节就来讲解线程和线程池的使用方法。
GIL锁
说到多线程,就不得不提一下python的 GIL锁 机制了。
GIL 全称是 Global Interpreter Lock ,
中文名是 全局解释器锁 ,
本质是一把 互斥锁 ,
作用是 将并发运行变成串行运行 ,
目的是 保证同一时间内,共享的数据只能被一个任务修改,保证了数据的完整性和安全性 ,
好处是 自动上锁和解锁,不需要人为的添加,可以减轻开发人员的负担,有自动垃圾回收的线程 ,
影响是 在同一个进程下开启多线程,同一时刻只能有一个线程在运行,效率低下 ,
即诟病是 单进程的多线程不能利用多核,效率低下 ,
对 计算密集型 任务不起任何作用,反而会因为线程的开销导致程序变慢,
解决方案是 在处理计算密集型任务时,使用多进程;在处理IO密集型任务时,使用多线程 ,
可以去除吗?不可以,python的其他许多特性都是利用了GIL锁机制,即使影响了效率也没办法去除(曾今有实验去除,但以失败告终) 。
多线程模块
_thread模块threading模块
一般不用 _thread 模块,本文直接使用它的升级版—— threading 模块。
启动多线程、多线程加锁
由于 threading 模块主要被设计用于 IO密集型 任务,使用 threading.__all__ 能看到所有支持的对象、属性和方法。这里先简单看一下线程有哪些常用的对象、属性和方法:
threading.Lock:互斥锁threading.Event:事件对象(相当于全局Flag布尔值)threading.Thread:线程对象threading.enumerate():所有正在运行的线程实例(包括主线程)[未启动、已结束的线程不在其中]threading.active_count():列表threading.enumerate()的长度threading.Thread(target=function).setDaemon(True):当daemon设置为True时,主线程结束会杀死该子线程(守护线程),默认是False,即主线程结束,子线程不会结束。(必须在线程 启动前 设置!)threading.Thread(target=function).start():启动线程threading.Thread(target=function).join():逐个执行线程(等上一个线程执行完再执行这个线程),此时会堵塞线程,使多线程变得无意义。
需要注意,使用 threading.Thread 创建线程时应该始终使用关键字参数 key=value 的形式传递参数,首先从其源代码 This constructor should always be called with keyword arguments. 可以看出;其次对于常用的 threading.Thread(target=function, args=()).start() 传递 target 和 args 两个参数的时候,其定义方式:def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None): 中 target 的位置并不是在首位,所以直接使用位置参数容易出错。
此处采用多线程下载,来展现多线程的魅力,示例代码如下:
import os
import re
import time
import requests
import threading
from bs4 import BeautifulSoup
def download(file, url):
if not os.path.isfile(file):
img = requests.get(url)
f = open(file, 'ab')
f.write(img.content)
f.close()
print(f'{file} 保存成功!')
if not os.path.isdir('王者荣耀皮肤'):
os.mkdir('王者荣耀皮肤')
start = time.time()
html = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
html.encoding = 'utf-8'
data = html.json()
for d in data:
html = requests.get(f"https://pvp.qq.com/web201605/herodetail/{d['ename']}.shtml")
html.encoding = 'gbk'
soup = BeautifulSoup(html.text, 'html.parser')
skins = soup.find('ul', class_='pic-pf-list pic-pf-list3')
skin_names = [re.findall(r'[\u4E00-\u9FA5]*', r)[0] for r in str(skins['data-imgname']).split('|')][::-1]
for s in range(len(skin_names)):
img_url = f"http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{d['ename']}/{d['ename']}-bigskin-{s+1}.jpg"
img_name = f"王者荣耀皮肤\\{d['cname']}_{skin_names[::-1][s]}{img_url[-4:]}"
threading.Thread(target=download, args=(img_name, img_url), daemon=True).start()
while threading.active_count() - 1:
time.sleep(0.1)
print(f'共花时间:{time.time() - start:.2f}')
由于 threading.enumerate() 返回的列表中至少包含了主线程,所以当所有线程减一大于 1 的时候,仍然有子线程在下载。
多线程下载的时间有点不一样,时间在 25 秒或 50 秒左右(我更愿意相信 25 秒左右是个意外,正常线程调度起来比协程消耗资源,应该稍慢于协程才对,但我下了不少遍,出现 25 秒左右的次数虽然不多,但也有几次,绝非一次的偶然)。
这里采用了最常见的线程启动方法, threading.Thread(target=function).start() 方法,还有一种方法仍然常见,就是重写 threading.Thread 线程对象中的 run() 方法以执行函数:
import time
import threading
class Threading(threading.Thread):
def __init__(self, index, *args, **kwargs):
super().__init__(*args, **kwargs)
self.index = index
def run(self) -> None:
print(f'开始运行线程: {self.index}')
time.sleep(0.5)
print(f'继续运行线程: {self.index}')
def __call__(self):
self.start()
Threading(1)()
Threading(2)()
Threading(3)()
这里采用 __call__(self) 方法自动调用原先的 start() 方法(为了凸显博主和其他人不一样~),来看看结果:

发现线程正常运行了,还发现顺序错乱、打印单行的现象,这正好证明的线程的特点:
- 线程执行起来是无序的,是由操作系统随机调度,由于多线程一般用于下载,所以很容易无多线程的视执行顺序问题。
- 线程在不加锁的时候,容易出现没打印完就开始打印下一条的情况,所以尽量在
print()前后加锁、释放锁:(创建锁对象: `lock = threading.Lock()`` )

- 比如这样,打印起来肯定是行行分开,不会再连在一起了。
线程锁threading.Lock有__enter__和__exit__两个方法,所以支持上下文管理,可以使用with来自动释放。
线程池
顾名思义,多线程池就是将线程放进一个池子,设置一定的限制,比如最大同时运行多少线程,防止电脑负载太重。
曾今有个模块 threadpool 专门用于提供线程池,但现在已经被弃用,现在引用标准库中的线程池模块: from concurrent.futures import ThreadPoolExecutor
创建线程池有两种方式,一种是普通创建:pool = ThreadPoolExecutor(max_workers=8) ,其中 max_workers 代表线程池内最大线程数量(不包括主线程),提交任务使用 Executor.submit(self, fn, *args, **kwargs) 方法,其中 fn 是函数名,后面跟函数所需的参数。在不想提交新任务时应执行 shutdown() 操作,节省内存空间。
如果你不想每次使用都执行 shutdown() 操作,ThreadPoolExecutor 实现了上下文管理协议,可以使用 with ThreadPoolExecutor(max_workers=8) as pool: 来使用,跳出 with 代码块之后,线程池会自动执行 shutdown() 操作。
另外 shutdown 默认是会等待所有子线程结束。
注意 ThreadPoolExecutor 对象不能获取实例化对象方法的结果,原因是不能 pickle ,只能调用非类中的方法,或者类中的@staticmethod方法。
仍然使用上面并发下载程序,将正常的线程启动方式变成线程池提交后,使用如下代码:
import os
import re
import time
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
def download(file, url):
if not os.path.isfile(file):
img = requests.get(url)
f = open(file, 'ab')
f.write(img.content)
f.close()
print(f'{file} 保存成功!')
if not os.path.isdir('王者荣耀皮肤'):
os.mkdir('王者荣耀皮肤')
start = time.time()
html = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
html.encoding = 'utf-8'
data = html.json()
pool = ThreadPoolExecutor(max_workers=8)
for d in data:
html = requests.get(f"https://pvp.qq.com/web201605/herodetail/{d['ename']}.shtml")
html.encoding = 'gbk'
soup = BeautifulSoup(html.text, 'html.parser')
skins = soup.find('ul', class_='pic-pf-list pic-pf-list3')
skin_names = [re.findall(r'[\u4E00-\u9FA5]*', r)[0] for r in str(skins['data-imgname']).split('|')][::-1]
for s in range(len(skin_names)):
img_url = f"http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{d['ename']}/{d['ename']}-bigskin-{s+1}.jpg"
img_name = f"王者荣耀皮肤\\{d['cname']}_{skin_names[::-1][s]}{img_url[-4:]}"
pool.submit(download, img_name, img_url)
pool.shutdown()
print(f'共花时间:{time.time() - start:.2f}')
我发现他下载的越来越稳定了,而且更快,只需 30 秒左右。
经过多次对最大线程数 max_workers 的测试,我对最大线程数的理解是这样的,当你图片下载到线程池最后一个的时候,第一个线程刚刚下载完腾出线程位置,这样安排线程的开销最小,下载速度最快。所以在设计多线程程序时,要合理安排线程数量,避免过少或过多的线程数,否则反而会更慢,变得得不偿失。
线程间通信
最简单的就是事件通信,常用 threading.Event 对象表示一个全局 Flag 布尔值:
import time
import threading
def callback(res):
print(f'{res} \t[当前用时:{time.time() - now:.2f}秒]')
def boil_water():
print("开始烧水...")
time.sleep(10)
callback("水烧开了")
def wash_vegetables():
print("叫孩子过来洗菜...")
time.sleep(20)
callback("菜洗好了")
def cook():
print("开始热饭...")
time.sleep(40)
fan.set()
callback("饭热好了")
def cooking():
while task3.is_alive():
time.sleep(0.2)
print("开始烧菜...")
time.sleep(30)
cai.set()
callback("菜烧好了")
def set_the_cutlery():
while task3.is_alive():
time.sleep(0.2)
print("叫孩子过来摆放餐具...")
time.sleep(4)
tool.set()
callback("餐具摆放好了")
def have_a_meal():
cai.wait()
fan.wait()
tool.wait()
print("开始吃饭...")
time.sleep(15)
now = time.time()
cai = threading.Event() # 是否烧好菜
fan = threading.Event() # 是否热好饭
tool = threading.Event() # 是否摆放好餐具
print('一个家庭吃一顿饭的全过程。 \t[当前用时:0.0 秒]')
task1 = threading.Thread(target=cook)
task2 = threading.Thread(target=boil_water)
task3 = threading.Thread(target=wash_vegetables)
task4 = threading.Thread(target=cooking)
task5 = threading.Thread(target=set_the_cutlery)
task6 = threading.Thread(target=have_a_meal)
for task in [task1, task2, task3, task4, task5, task6]:
task.start()
while threading.active_count() - 1:
time.sleep(0.1)
print(f'很满足这一顿饭~ \t[总共用时:{time.time() - now:.2f}秒]')
threading.Event 对象的全部方法有:
| 方法 | 中文速记 | 作用 |
|---|---|---|
wait(timeout=None) |
等待 | 等待事件标记为 True ,否则会一直堵塞。设置 timeout 参数可以设置最长堵塞多久。 |
set() |
设置 | 设置事件标记,即事件标记为 True 。 |
clear() |
清除 | 清除事件标记,即事件标记为 False 。 |
is_set() |
查询 | 查询事件标志是否设置,即获取事件标记的布尔值。 |
其他通信当然是使用队列啦,上小例子:
import time
import threading
from queue import Queue
def maker1():
for i in range(0, 10, 2):
q.put(str(i))
print(f'maker - {i}')
def maker2():
for i in range(1, 11, 2):
q.put(str(i))
print(f'maker - {i}')
def consumer():
for i in range(10):
print(f'consumer - {i}(GET {q.get()})')
q = Queue(maxsize=2)
threading.Thread(target=maker1).start()
threading.Thread(target=maker2).start()
threading.Thread(target=consumer).start()
while threading.active_count() - 1:
time.sleep(0.1)
q.task_done()
输出结果:
maker - 0
maker - 2
consumer - 0(GET 0)
consumer - 1(GET 2)
maker - 4
consumer - 2(GET 4)
maker - 1
maker - 6
consumer - 3(GET 1)
maker - 3
consumer - 4(GET 6)
maker - 8
consumer - 5(GET 3)
consumer - 6(GET 8)
maker - 5
consumer - 7(GET 5)
maker - 7
maker - 9
consumer - 8(GET 7)
consumer - 9(GET 9)
Queue 队列是用来处理线程间信息交流安全的,maxsize 设置最大队列长度,原理就是堵塞,直到输入写入队列,或者直到读取出队列,常用 put() 入栈和 get() 出栈操作,先入先出,后入后出,能完美满足 生产者—消费者 模型,另外还能通过 qsize() 来查看队列中还有多少的数据。一般都会在使用完队列后执行 task_done() 释放内存,像这种直接能结束的程序可以不加。
因为多线程顺序不定加上没有加锁的原因,他的顺序可能会比较乱,而且会出现挤在一行输出的情况,那些都是小问题~
在线程中除了用 threading.active_count() - 1 判断是否所有子线程结束再继续主线程,还可以在所有线程 start() 后再 join() 一遍,全都堵塞在主线程等待子线程结束。
线程安全
都说 GIL锁 机制就是为了保护线程安全的,可它真的能100%保证线程的安全吗?答案是否定的。
来看下面的简单例子:
import time
import threading
class Account:
def __init__(self, account_no, balance):
self.account_no = account_no
self.balance = balance
def draw(account, draw_amount):
if account.balance >= draw_amount:
print(threading.current_thread().name + " 成功!吐出钞票:" + str(draw_amount))
time.sleep(0.001) # 模拟取钱时的等待操作
account.balance -= draw_amount
print(threading.current_thread().name + " 后,余额为: " + str(account.balance))
else:
print(threading.current_thread().name + " 失败!余额不足!")
acc = Account("123456789", 1000)
threading.Thread(name='从银行卡取钱', target=draw, args=(acc, 800)).start()
threading.Thread(name='发银行卡红包', target=draw, args=(acc, 800)).start()
猜猜结果是什么?
没错,就是余额为负!
从银行卡取钱 成功!吐出钞票:800
发银行卡红包 成功!吐出钞票:800
余额为: 200
余额为: -600
银行要是能这样,那估计得倒闭,所以多线程并无法实现绝对的线程安全,更多是要开发者们自己注意逻辑情况。
遇到这种情况有解决方案吗?有!就是在判断余额前加锁,保证同时只判断一次的同步操作:
import time
import threading
class Account:
def __init__(self, account_no, balance):
self.account_no = account_no
self.balance = balance
def draw(account, draw_amount):
with lock:
if account.balance >= draw_amount:
print(threading.current_thread().name + " 成功!吐出钞票:" + str(draw_amount))
time.sleep(0.001) # 模拟取钱时的等待操作
account.balance -= draw_amount
print(threading.current_thread().name + " 后,余额为: " + str(account.balance))
else:
print(threading.current_thread().name + " 失败!余额不足!")
acc = Account("1234567", 1000)
lock = threading.Lock()
threading.Thread(name='从银行卡取钱', target=draw, args=(acc, 800)).start()
threading.Thread(name='发银行卡红包', target=draw, args=(acc, 800)).start()
这下取钱就正常了:
从银行卡取钱 成功!吐出钞票:800
从银行卡取钱 后,余额为: 200
发银行卡红包 失败!余额不足!
两个任务反一下就会变成:
发银行卡红包 成功!吐出钞票:800
发银行卡红包 后,余额为: 200
从银行卡取钱 失败!余额不足!
基本上是谁先谁就能抢到锁并执行完。
多进程程序的简单设计
有句话说的好,“多进程才是真并行”,这是 python 中"绕过" GIL锁 的普遍方式,如果你不想更换 CPython 为其他版本或者用其他语言实现再链接到代码中的话。
多进程模块是众所周知的 multiprocessing 模块,一般进程会分配独立的空间,所以互相之间不会打扰。
多进程和多线程比较类似,都有 start() 、 join() 、 is_alive() 等常见方法。
多进程和多线程一样,不仅可以通过函数的方法创建进程,还能用继承并重写 run() 方法的方式创建进程
写到这里,它都已经开始提醒我了,但我偏不,我就要写,能一次发完就不分两次发~

但这里还是决定少写点,毕竟多进程用的不算很多。
启动多进程、多进程加锁、多进程通信
在使用多进程的时候要注意在 if __name__ == '__main__': 下启动多进程,否则他会报错如下:

而且他会每个进程执行 if __name__ == '__main__': 上面的部分。这段话意思就是说不让你直接使用多进程,除非证明你是本身程序在运行而不是被调用的时候运行,防止你进程开的太多电脑卡住,防止盲目启动(个人理解)。
先用一段代码弄清除多进程是如何工作的:
from multiprocessing import Process
print('init')
def add_num(num):
pass
if __name__ == '__main__':
print('main')
Process(target=add_num, args=(999, )).start()
Process(target=add_num, args=(9999, )).start()
Process(target=add_num, args=(99999, )).start()
Process(target=add_num, args=(999999, )).start()
它的执行结果是:

发现main只执行了一次,而init在初始化的时候先执行了一次,之后每次子线程启动都会执行一次,这个需要注意。
然后不用进程池是不太方便并发下载了(谁用谁作死,好在下载的只是图片,要是下载视频…那534个视频就会创建534个线程,就算是服务器也hold不住吧~),那就来个使用多进程的反面教材:
from multiprocessing import Process
number = 0
def add_num(num):
global number
number += num
print(number)
if __name__ == '__main__':
Process(target=add_num, args=(999, )).start()
Process(target=add_num, args=(9999, )).start()
Process(target=add_num, args=(99999, )).start()
Process(target=add_num, args=(999999, )).start()
你们以为的结果是不是:
999
10998
110997
1110996
No,No,No,它的结果是:

是不是感觉既在意料之外,又在情理之中?
上面我们说到,进程之间相互独立,有自己的空间,并会自己复制一份变量地址,具体为什么,打印一下程序中 number 的 id 值就知道了:

四个完全不一样对吧,再对比一下 num 的 id 和数字的 id 值:
from multiprocessing import Process
number = 0
def add_num(num):
global number
print('num id : ', id(num))
print('number id : ', id(number))
number += num
if __name__ == '__main__':
print(id(999))
print(id(9999))
print(id(99999))
print(id(999999))
print('----------')
Process(target=add_num, args=(999, )).start()
Process(target=add_num, args=(9999, )).start()
Process(target=add_num, args=(99999, )).start()
Process(target=add_num, args=(999999, )).start()
结果:

发现所有 id 完全不一样,因为一开始打印的数字 id 是主线程中的数字 id ,而线程中打印的分别是每个线程所处空间中的 id ,所以一样才怪。
此时我们必须使用进程间的通信才可以:
from multiprocessing import Process, Queue
def add_num(num, q):
number = q.get()
number += num
print(number)
q.put(number)
if __name__ == '__main__':
queue = Queue()
queue.put(0)
Process(target=add_num, args=(999, queue)).start()
Process(target=add_num, args=(9999, queue)).start()
Process(target=add_num, args=(99999, queue)).start()
Process(target=add_num, args=(999999, queue)).start()
由于子进程的调用机制,这里需要将队列传进参数中(传入一个列表,结果发现里面每个列表的 id 值都不一样!),虽然有点小复杂,但好在最后的结果是我们想要的。

为了防止加的时候出现和线程一样的安全问题,我们采用进程锁来管理:
from multiprocessing import Process, Queue, Lock
def add_num(num, q, l):
with l:
number = q.get()
number += num
print(number)
q.put(number)
if __name__ == '__main__':
lock = Lock()
queue = Queue()
queue.put(0)
Process(target=add_num, args=(999, queue, lock)).start()
Process(target=add_num, args=(9999, queue, lock)).start()
Process(target=add_num, args=(99999, queue, lock)).start()
Process(target=add_num, args=(999999, queue, lock)).start()
进程池
使用进程池就可以多进程下载了,而且还能回调,小栗子如下:
import os
import re
import time
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
def callback(file):
print(f'{file} 保存成功!')
def download(file, url):
if not os.path.isfile(file):
img = requests.get(url)
f = open(file, 'ab')
f.write(img.content)
f.close()
return file
if __name__ == '__main__':
pool = Pool(maxtasksperchild=8)
if not os.path.isdir('王者荣耀皮肤'):
os.mkdir('王者荣耀皮肤')
start = time.time()
html = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
html.encoding = 'utf-8'
data = html.json()
for d in data:
html = requests.get(f"https://pvp.qq.com/web201605/herodetail/{d['ename']}.shtml")
html.encoding = 'gbk'
soup = BeautifulSoup(html.text, 'html.parser')
skins = soup.find('ul', class_='pic-pf-list pic-pf-list3')
skin_names = [re.findall(r'[\u4E00-\u9FA5]*', r)[0] for r in str(skins['data-imgname']).split('|')][::-1]
for s in range(len(skin_names)):
img_url = f"http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{d['ename']}/{d['ename']}-bigskin-{s+1}.jpg"
img_name = f"王者荣耀皮肤\\{d['cname']}_{skin_names[::-1][s]}{img_url[-4:]}"
pool.apply_async(download, args=(img_name, img_url), callback=callback)
pool.close()
pool.join()
print(f'共花时间:{time.time() - start:.2f}')
最后的 pool.close() 方法是为了让进程池不再接受信的请求,然后才能执行 pool.join() 堵塞主进程并等待子进程结束。
完美下载!
总结
协程、线程、进程的简单小对比:
| 某程 | 性能消耗 | 上手难度 | 优点 | 缺点 |
|---|---|---|---|---|
| 协程 | 低 | 困难 | 开销小、性能高、有返回值 | 调试复杂、较为困难 |
| 线程 | 中 | 容易 | 创建简单、上手容易 | 无返回值、GIL锁使并行变并发 |
| 进程 | 高 | 均衡 | 解决GIL锁无法并行的问题、 运行稳定、可以真正实现并行 |
无返回值、变量完全隔离难联系、 进程间相对于其他方式比较消耗性能 |
一般只有计算密集型任务才用多线程,相对其他其他情况而言,线程和协程使用的效果会更好(并发下载、并发socket、并发网络访问等)。
结束语
感谢您能阅读到文末此处~ 下面没有东西咯,恭喜学完了全套基础设计,记得勤加练习实践哦~
我有一个大胆的想法,不如请您把您收藏的其他有关多任务的文章全都取消收藏,仅收藏本文?
给自己凑一个好看的数字吧:
