
撰文|李响
1
前言
为了简化分布式训练,OneFlow 提出了全局视角(Global View) 的概念,在全局视角下,可以像单机单卡编程,进行分布式训练。在 OneFlow 的设计中,使用 Placement、SBP 和 SBP Signature 来实现这种抽象。其中,Global Tensor 是为了能够满足 Global View 所需抽象的一种 Tensor。本文重点讨论了 Global Tensor 的全局视角与物理视角的映射。
此外,从去年 11 月中旬开始,我在 OneFlow 五个月的实习告一段落,在文末,我对这段时间的工作和收获做了简单总结。
2
Global Tensor
2.1 OneFlow 分布式全局视角的基础保证
这部分内容对应 OneFlow 论文(https://arxiv.org/pdf/2110.15...) 的 3.1 节,Placement 与 SBP、SBP Signature 是 OneFlow 分布式全局视角的重要保证,OneFlow 的全局视角使分布式训练与单机单卡一样易用。
首先,Global Tensor 的 Placement 属性可以指定该 Tensor 存放在哪个物理设备上。我们重点看下 SBP 的设计,它完成了全局张量和相应的局部张量之间映射的数学抽象。
下图是一个形状为 2x2 的 Global Tensor 在 4 种 SBP 映射(每一种都被称为 SBP Signature)下被映射为 2 个局部张量(Local Tensor),分别为 split(0),split(1),broadcast 和 partial-sum,分别是按维度分割、复制并广播和按位置相加的思路。
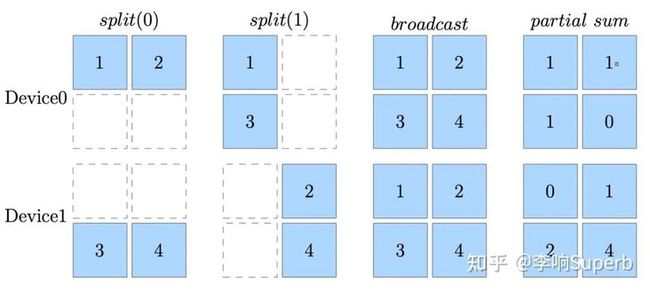
对于一个 Global Tensor,我们可以任意设置它的 SBP。但是,对于有输入、输出数据的 Ops,不允许随意设置它的输入、输出的 SBP 属性。因为随意设置 Ops 的输入输出 SBP 属性,可能不符合全局视角下算子的运算法则,所以 SBP Signature 的概念被提出。
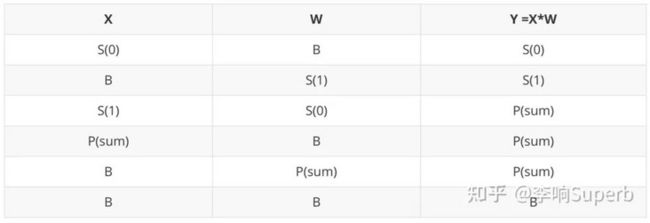
以 MatMul 为例,给定一个数据张量X 和一个权重张量 W,Y=X*W 的 SBP Signature 可以从 X 和 W 的 Signature 中推断出来。如下表,是合法的合法 SBP 组合。当然,SBP Signature 是不需要被我们显式指定的,OneFlow 存在自动推导机制。
以上介绍的是 1D SBP,为了兼容更复杂的分布式训练场景,OneFlow 也提供了 2D SBP。我们简单来看下区别,首先是 Placement 配置的区别:
>>> placement1 = flow.placement("cuda", ranks=[0, 1, 2, 3]) # 1D SBP 配置集群
>>> placement2 = flow.placement("cuda", ranks=[[0, 1], [2, 3]]) # 2D SBP 配置集群当 placement 中的集群是 1/2 维的设备阵列时;Global Tensor 的 SBP 也必须与之对应。比如,对于上面的第二种情况,可以配置 (broadcast, split(0)) 的 2D SBP。这时,在设备阵列上,第 0 维做 broadcast 操作;在第 1 维做 split(0)。
再举个例子:对于 ranks=[[0, 1], [2, 3]]),假设看作是 ranks = [Dim0_DeviceGroupA, Dim0_DeviceGroupB],Dim0_DeviceGroupA = [0, 1],Dim0_DeviceGroupB=[2, 3]。那么 rank0 的数据就是先把 Global Tensor 完整数据 broadcast 到第 0 维的两个设备小组 Dim0_DeviceGroupA 和 Dim0_DeviceGroupB;然后再把 Dim0_DeviceGroupA 小组得到的数据 split(0) 到第 1 维即 Dim0_DeviceGroupA 内的 rank 0 和 rank 1(ranks=[[0, 1]]),对于 Dim0_DeviceGroupB 也同理。
>>> sbp = (flow.sbp.broadcast, flow.sbp.split(0))
>>> tensor_to_global = tensor.to_global(placement=placement, sbp=sbp)对于 SBP Signature,同样也有 2D 的版本,在 1D 的基础上,在两个维度上分别独立推导,做矩阵乘。
2.2 SBP 自动转换
同一 Global Tensor 的生产者和消费者(上游算子输出和下游算子输入)可能需要不同的 SBP Signature。如下图中所示 ,两个 MatMul Ops 通过 Global Tensor Y0 连接。S(0) 是 M0 推断的 Y0 的 SBP Signature。然而,M1 期望它的 SBP Signature 是 B。在这种情况下,在 M0 和 M1 之间需要一个转换 Y0 对应的的局部张量 SBP 类型的操作。这样就完成了 SBP 自动转换,也就是 OneFlow 的 Boxing 机制。
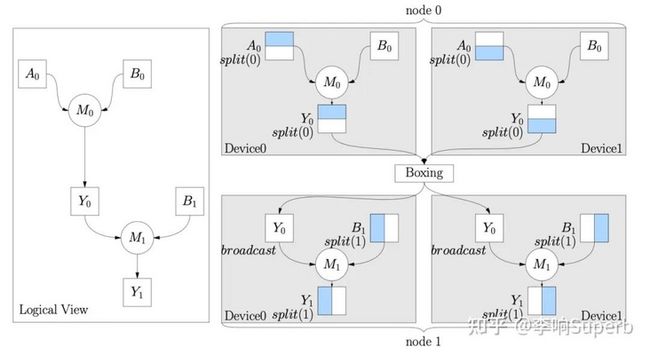
Boxing 机制有不用的方法,如 all2all、broadcast、reduce-scatter、all-reduce 和 all-gather 等,每种操作会产生不同的通信成本。上面的 split(0) 转换为 broadcast,相当于做了一次 all-gather 操作。其实很好理解,这部分内容更详细的解释对应 OneFlow 论文(https://arxiv.org/pdf/2110.15...)的 3.2 节,比如每种操作的通信成本大小计算。
2.3 to_global 方法
基于上面两节的内容看下代码,其中有典型的 to_global 方法使用,这部分内容也对应 OneFlow 论文的 3.4 节。
import oneflow as flow
P0 = flow.placement("cuda", ranks=[0, 1])
P1 = flow.placement("cuda", ranks=[2, 3])
a0_sbp = flow.sbp.split(0)
b0_sbp = flow.sbp.broadcast
y0_sbp = flow.sbp.broadcast
b1_sbp = flow.sbp.split(1)
A0 = flow.randn(4, 5, placement=P0, sbp=a0_sbp)
B0 = flow.randn(5, 8, placement=P0, sbp=b0_sbp)
Y0 = flow.matmul(A0, B0)
Y0 = Y0.to_global(placement=P1, sbp=y0_sbp)B1 = flow.randn(8, 6, placement=P1, sbp=b1_sbp)
Y2 = flow.matmul(Y0, B1)上面代码中,我们首先初始化了 Global Tensor 的 placement 和 SBP。上一层算子 matmul 的输出 SBP 本来是 split(0),但是下一层算子 matmul 的输入,被转成了 broadcast。
此时,上一层的输出与下一层的输入,它们的 SBP 并不一致,这是不允许的。所以,基于 Boxing 机制,我们使用 to_global 方法将 split(0) 转换为 broadcast,也就是代码参数中的 sbp=y0_sbp。
2.4 GlobalTensor 类代码跟踪
基于上面的内容,其实 Global Tensor 的概念就更清晰了,在 OneFlow 的设计中,它就是为了能够满足 Global View(全局一致性视角)所需抽象的一种特殊 Tensor。
OneFlow 的 Tensor 设计更像桥接模式,把 Tensor 基类作为抽象化角色,TensorIf 作为 Tensor 的子类充当实现化角色接口,GlobalTensor 和 MirroredTensor 都给出了实现化角色接口的具体实现,如下图。
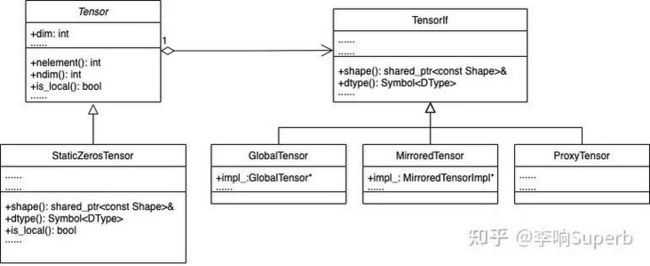
上图是简单的 Tensor 的设计模式,这里我们直接重点定位到 GlobalTensor 实现类中,代码位置在 github.com/Oneflow-Inc/ ,类名为 ConsistentTensor,在 OneFlow v0.7.0 中已经叫做 GlobalTensor。相关的代码也可以在这个位置开始追踪。在 ConsistentTensor 中,有指向 ConsistentTensorImpl 的指针,EagerConsistentTensorImpl 和 EagerConsistentTensorImpl 又分别继承 ConsistentTensorImpl ,代码位置在 github.com/Oneflow-Inc/ 。值得注意的是, ConsistentTensor 的实现类 ConsistentTensorImpl 里,代码中存在 ConsistentTensorMeta 的成员指针,TensorMeta 系列类维护了除包括 Tensor 的设备、形状和数据类型等基本变量外,包括 placement 和 SBP 的信息。
前面说过,Global Tensor 是为了能够满足 Global View 分布式抽象的一种特殊 Tensor,关于上图的 MirroredTensor ,就是实际存储各个设备 Tensor data 的地方。EagerConsistentTensorImpl 成员中有指向 MirroredTensor 的指针,同样的,MirroredTensor 持有指向 MirroredTensorImpl 的指针,MirroredTensorImpl 的实现类中则持有指向 TensorStorage 的指针,Tensor 中的数据最终是存在于 TensorStorage 成员中,代码位置在https://github.com/Oneflow-In...
2.5 如何做 Global Ops 的执行测试
最后,简单看一下 OneFlow 如何完成 Global Ops 的测试任务。之前的文章「深度学习框架如何优雅地做算子对齐任务」,已经介绍过 OneFlow 的 AutoTest 框架的依赖文章。
在这篇文章里,主要围绕 Local Ops 的单测任务介绍, Global Ops 的执行测试也基于该 AutoTest 框架。区别在于,我们只需要使用文章前面介绍过的 to_global() 方法,由 local tensor 转换得到 global tensor。并且需要枚举 placement 和 SBP 信息。
还是以 matmul Op 为例,对于 matmul 这类 Binary Ops,同一 placement 下,分别需要遍历两次 SBP,代码如下所示。
@autotest(n=1, check_graph=False)
def _test_matmul(test_case, placement, x_sbp, y_sbp):
x = random_tensor(ndim=2, dim0=8, dim1=16).to_global(placement=placement, sbp=x_sbp)
y = random_tensor(ndim=2, dim0=16, dim1=8).to_global(placement=placement, sbp=y_sbp)
return torch.matmul(x, y)
class TestMatMulModule(flow.unittest.TestCase):
@globaltest
def test_matmul(test_case):
for placement in all_placement():
for x_sbp in all_sbp(placement, max_dim=2):
for y_sbp in all_sbp(placement, max_dim=2):
_test_matmul(test_case, placement, x_sbp, y_sbp)
if __name__ == "__main__":
unittest.main()
3
总结
上面简单介绍了下我对 Global Tensor 的理解,在这一部分总结下我的实习工作和收获:
在 OneFlow 的这段实习时间并不长,但这是我第一段工作经历,并且是远程工作,我还有忙学校的一些事情。至今为止我只认识啸宇哥(许啸宇)的脸,哈哈哈~ 还见过 BBuf (张晓雨)的结婚证件照,还有迟哥(姚迟)的个人头像。总的来讲,算是一段比较有趣轻松(也许因为我个人不作为:))的经历。
刚入职时,首先是提交 OneFlow 仓库几个简单的 PR,熟悉 CI 的流程,还有性能测试、使用 OneFlow 完成多卡训练 U-Net 网络和 python 代码搬运等一些简单的工作,更快的适应工作节奏。在这期间,学习了 ONNX,认真读了 github.com/BBuf/onnx_le 下的一系列文章,并且参与了 OneFlow2ONNX 的一些工作。
实习中期,自己修复了 OneFlow 一些算子代码的 bug,并且自学了 C++ 的新标准和 CUDA 优化,这时才觉得自己大学三年好像什么都没学到一样,是一个没有感情的 Java、408 考试机器。此外,开发了一些算子,也写了很多 bug,这里不得不感谢 OneFlow 的保安 zzk(郑泽康)。搭建了 libai 和 flowvision 仓库 RTD 文档的 CI,负责相关文档的 Oncall 工作。
实习后期,完成了 nn.Graph 支持 Local Ops 单测的项目,也就是不改代码实现同一段代码的 Graph 和 Eager 模式的自动化执行测试,这里面要解决很多子问题,但是通过一点一点的 hack,基本完成了这个任务。基于此,我对静态图(Graph)的构建、编译流程、训练和调试会更加熟悉。
在 OneFlow 仓库大概提了 30+ 的 PR,参与开源有非常实际的好处,收获比每天实习做软件黑盒测试要大,比如成为 Committer 或提交了多少 PR,面试时就可以把这些放在简历上,但如果没有参与开源的经历,就得从其他方面花费很大精力去证明自己的能力。
在 OneFlow 工作,总体上还是挺轻松的。在新手村期间,一直有同事帮助,让我不至于面对很多不懂的技术而痛苦。有时间还想能有机会回 OneFlow 一直实习,如果反思自己,就是真的还需要好好沉淀一下碎片化的知识。
接下来一小段时间开始做实验和写论文啦,I'm a fight until free~
参考链接
1. https://arxiv.org/pdf/2110.15...
2. https://github.com/Oneflow-In...
欢迎下载体验OneFlow v0.7.0最新版本:
https://github.com/Oneflow-In...