卷积神经网络优化
卷积神经网络优化–潘登同学的深度学习笔记
文章目录
- 卷积神经网络优化--潘登同学的深度学习笔记
- Alexnet网络结构
-
- 连续使用小的卷积核的作用
-
- 使用1*1的卷积核的作用
- 使用1*1卷积核代替全连接
- Dropout技术
-
- 使用方法
- 为什么Dropout技术多用在全连接层
- 数据增强技术
- VGG16网络Topolopy结构
-
- VGG16及其变形
- Inception-V1
-
- Inception的NIN
-
- 回顾1*1卷积核的作用
- 解决超深度网络的训练问题
- Inception-V2
- Inception-V3
-
- Inception-V3源码
-
- GlobalAveragePooling
- ResNet残差网络
-
- 残差单元的作用
- 为什么ResNet能更深
- ResNet残差单元优化
- 更多细节
- DenseNet
-
- DenseNet中的block
- DenseNet中的grow rate
- DenseNet中的transition
- MobileNet
-
- 深度可分离卷积
- Relu6
-
- 使用Relu6的三种解释
- V1的网络架构
- V2的改进
Alexnet网络结构

Alexnet与LeNet不同的地方
- LeNet基本上都是卷积接池化
- 而Alexnet却出现多次卷积才接池化
- 连续使用小的卷积核
- 使用了Dropout技术
- 使用了数据增强
连续使用小的卷积核的作用
举例说明
- 使用大的卷积核(VAILD)
- image 5*5
- filter 5*5
- feature map 1*1
- 使用小的卷积核(VAILD)
- image 5*5
- filter 3*3
- feature map 3*3
- filter 3*3
- feature map 1*1
优点
- 比较两个的参数个数: 前者25,后者18
- 更高阶特征: 后者比前者多一次非线性变换
- 可以感受更小的物体
使用1*1的卷积核的作用
- 当卷积核个数等于通道数时
降维! 将stride设置为(2,2)或者更大,就能使feature map比输入面积要小 - 当卷积核个数小于通道数时
降维! 将stride设置为(1,1),就能使feature map的通道比输入要少
使用1*1卷积核代替全连接
举例说明
- 输入层 m*3*3*128
- 卷积核 3*3*128*4096(VILDE)
- 隐藏层 m*1*1*4096
- 卷积核 1*1*4096*10(VILDE)
- 输出层 m*1*1*10
Dropout技术
在深度学习中,流行的正则化技术,它被证明非常成功,即使在顶尖水准(SOTA,state of the art)的神经网络中也可以带来 1%到 2%的准确度提升,这可能乍听起来不是特别多,但是如果模型已经有了 95%的准确率,获得 2%的准确率提升意味着降低错误率大概 40%,即从 5%的错误率 降低到 3%的错误率!!! 在每一次训练 step 中,每个神经元,包括输入神元,但是不包括输出神经元,有一个概率神经元被临时的丢掉,意味着它将被忽视在整个这次训练 step(一次正向传播+一次反向传播) 中,但是有可能下次再被激活
超参数p叫做dropout rate, 一般设置50%,在训练之后,神经元不会再被dropout;
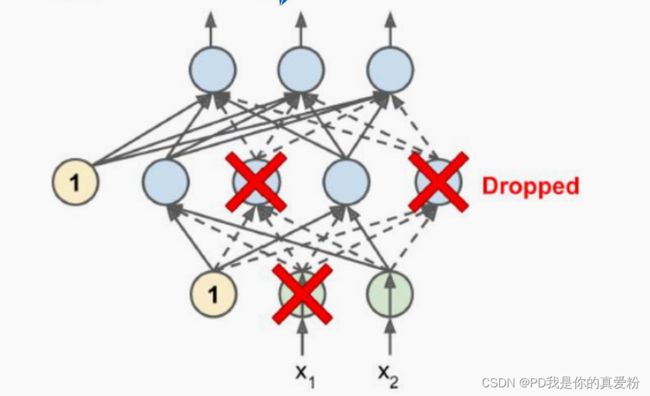
使用方法
from tensorflow.contrib.layers import dropout
is_training = tf.palceholder(tf.bool,shape=(),name='is_training')
keep_prob = 0.5 # 保留神经元的比例 注意tensorlfow中的keep_prob与dropout rate相反,他俩相加的结果为1
x_drop = dropout(X,keep_prob,is_tarining=is_training)
hidden1 = fully_connected(x_drop,n_hidden1,scope='hiddlen1')
hidden1_drop = dropout(hidden1,keep_prob,is_tarining=is_tarining)
hidden2 = fully_connected(x_drop,n_hidden2,scope='hiddlen2')
hidden2_drop = dropout(hidden2,keep_prob,is_tarining=is_tarining)
logits = fully_connected(hidden2_drop,n_outputs,activation_fn=None,scope='outputs')
为什么Dropout技术多用在全连接层
(当然也可以用在别的层)
答: 因为全连接层的参数数量多
数据增强技术
与Dropout一样,也是深度学习的Regularization正则化方法
从现有的数据产生一些新的训练样本,人工增大训练集,这将减少过拟合
例如如果你的模型是分类蘑菇图片,你可以轻微的平移,旋转,改变大小,然后增加这 些变化后的图片到训练集,这使得模型可以经受位置,方向,大小的影响,如果你想用模型可以经受光条件的影响,你可以同理产生许多图片用不同的对比度,假设蘑菇对称的,你也可以水平翻转图片

TensorFlow 提供一些图片操作算子,例如 transposing(shifting),rotating,resizing, flipping(翻转),cropping(剪切),adjusting brightness(亮度调整),contrast(对比度),saturation(饱和度),hue(色调)
VGG16网络Topolopy结构
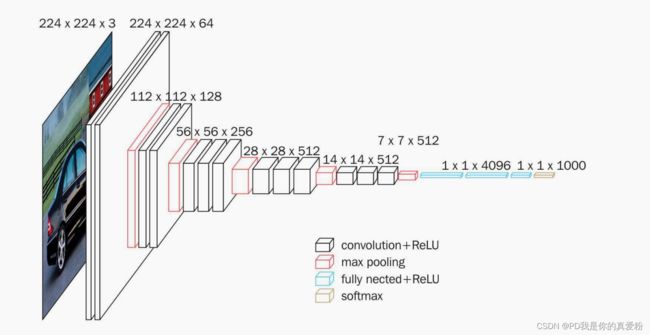
特点
- 深度很重要
- 连续使用小的卷积核能增加深度
VGG16及其变形

Inception-V1
Inception是一部电影,叫做盗梦空间,而我们这里说的Inception是指google家的用于图像分类的网络模型,有V1-V4版本,因为这些网络模型中,出现了网络套网络的情况,因此而得名

Inception的NIN
NIN是network in network的缩写,我们很容易地发现,在前面部分都是很正常的链式网络结构,但是到了中部,就循环出现以下结构,这个可以理解为NIN中后面的那个Network,这里暂且称之为中间结构

中间结构分为四个不同的通道向前传递,除去1*1的卷积层不看,从左到右,其实就是’直接传递’、‘3*3卷积’、‘5*5卷积’、‘池化’,表示的是用不同的方式审视原feature map
回顾1*1卷积核的作用
因为分为了四个不同的通道向前传递,如果每一层保持通道数不变的话,四个通道的输出叠加起来就是原feature map通道数的4倍,后面还有很多个中间结构,这样的话参数数量就指数级上升了
而1*1卷积核的一大作用就是降维与升维,在这里通过1*1卷积核不仅能起到降维的作用,使得最后四个通道的输出叠加起来与原feature map一样,还能选择降维的程度,起到不同视角看的东西就不相同的作用。
解决超深度网络的训练问题
我们知道,一旦网络深了之后,就难免出现梯度消失问题,远离输入层的地方参数更新幅度过小,前面的部分就形同虚设,而inception给我们提供了几种可供参考的解决方案
- alternative training: 在差不多深的地方接一层输出,进行训练;在整段网络中,从输入王输出的方向进行这个过程多次;
举例说明
从输入层到经过了三个中间结构后,接出了一个softmax0的输出,以这一段作为一个完整的网络训练一次…

那接下来就依葫芦画瓢了,保持上一次的训练结构不变,在恰当的位置接出去一个softmax1的输出,再从输入到softmax1作为一个完整的网络训练一遍;
(在inception-v1中)最终input到softmax2(最后的输出)再训练一遍,就完成,至此,靠近输入的已经训练三次了,能一定程度解决梯度消失的问题…
注意: 上面说的这三个过程,合在一起才算一遍完整的训练(虽然有三次正向传播,三次反向传播)
- total loss: 把上面的softmax0、1、2的损失加到一起,去训练整个网络
Inception-V2
Inception-V2的最大特点是加入了BN层,去掉了之前alternative training的多层输出,
BN层的特点就是在做非线性变换之前,保持输入的数据分布与输出的数据分布一致;
Inception-V3
Inception-V3的特点就是更加crazy,将原本的NIN变成了NININ,而且将连续使用小的卷积核这个特点发扬地更光大,在模型中多次使用1*3、3*1和1*7、7*1的卷积核,从而做到了NININ
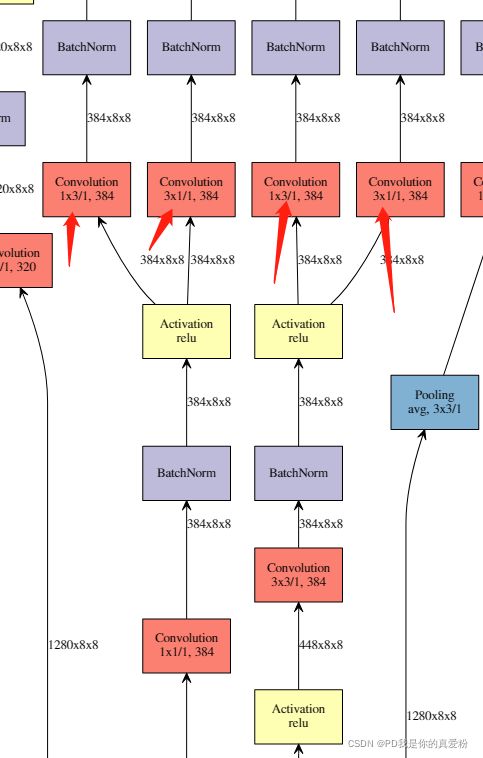
Inception-V3源码
通过keras.applications一路点进去,我们可以看到inception-v3中的除了之前在v1中见到的中间结构

也有NININ的拓宽了的中间结构

同时我们注意到,v3中将卷积层输出转成全连接的时候,不是通过flatten的形式,将张量展平的,而是用了一个GlobalAveragePooling的方式

GlobalAveragePooling
GlobalAveragePooling的作用方式如下,就是池化核为整张图片大小的平均池化
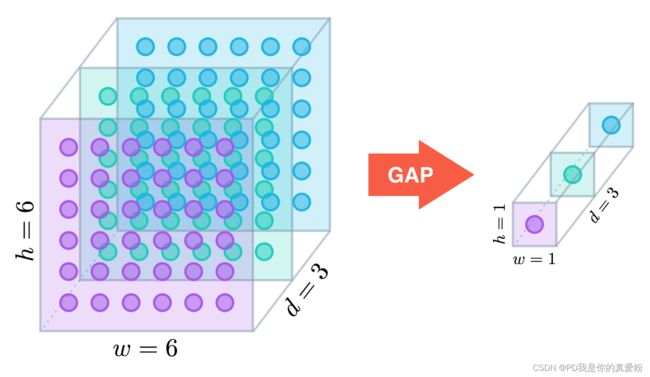
当然就不用做flatten,用GAP会损失比较多的信息,但是大多数网络都是用GAP的…
ResNet残差网络
残差网络之所以称之为残差网络,是因为其整个网络是由很多个残差单元组成的,下图是一个残差单元
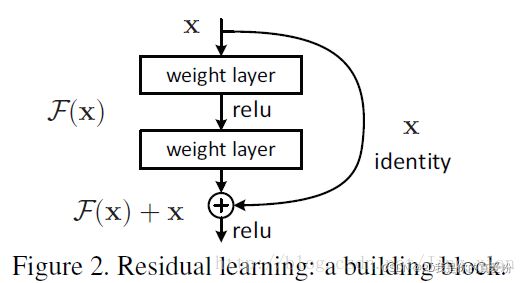
图中的X可以理解为输入或上一层的输出, F ( x ) F(x) F(x)表示残差, F ( x ) + x F(x)+x F(x)+x表示残差单元的输出,X除了进入残差单元进行卷积之外,还有一个通道直接到输出,与残差进行点加运算得到最终的输出…
残差单元的作用
从图中可以得知,残差单元的作用就是拟合残差,即拟合 F ( x ) F(x) F(x), 假设输入是一个预测结果 y ^ \hat{y} y^(可以理解为上一层的输出嘛),输出是一个正确答案 y y y,那么残差单元的工作就是,使得 y y y与 y ^ \hat{y} y^差别最小
F ( x ) = y − y ^ F(x) = y - \hat{y} F(x)=y−y^
回想我们前面说的GBDT在处理回归任务的时候也是这样,通过不停的加小树,后面加的小树只负责拟合残差,进而完成回归任务;区别就是,网络结构是提前设定好的,而GBDT则是动态添加的小树;
为什么ResNet能更深
虽然我们说inception使用BN层能减轻梯度下降问题,但是事实上他只是维持了输入与输出的方差不变,没有从根源上解决梯度消失问题
而这个残差单元的x跨过两个卷积层,与残差单元输出相加的操作,使得到最后输出结果处时,最前面一层残差单元的输出的梯度仍然是1(因为是relu,要么是1要么是0,0就没啥好说的), 因为第一层残差单元的输出是加到最终结果中的,和的导数等于导数的和嘛…
所以就解决了梯度消失的问题(当然ResNet中也有BN层)
ResNet残差单元优化
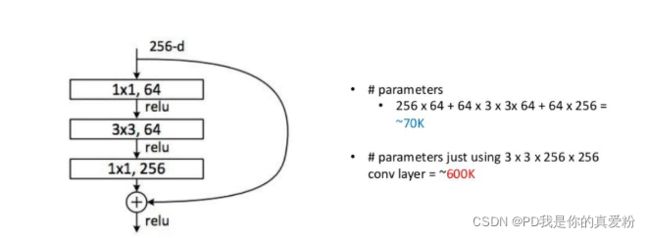
在实践中,采用先降维,再卷积,最后升维的方式能减少大量的参数,使得计算开销更小…
更多细节

在图中可能显示的不明显,有些短接其实还过了一层卷积,在源码中可以看出
- 源码五连




DenseNet
DenseNet借鉴了ResNet的短接操作,将短接操作变得更加魔怔,在一个dense单元中,往后短接5次…

DenseNet的网络结构则是将dense单元接卷积再接池化…

DenseNet中的block
block表示一个Dense单元中,有多少块(一块包括1*1的卷积,3*3的卷积,当然还会有BN与relu,这个块的结果与输入进行concat拼接),在上面的那个Dense单元中,block就是4
而在DenseNet121中总共有4个Dense单元,分别有 [ 6 , 12 , 24 , 16 ] [6,12,24,16] [6,12,24,16]块
DenseNet中的grow rate
grow rate表示经过一个block后,通道数增加了多少,去看源码!!!


那么针对DenseNet的第一个Dense中,输出就比输入通道数增加了6*32个
DenseNet中的transition
transition表示的就是在两个Dense单元中的卷积和池化,在这里会对之前增加的很多的通道数进行降维,在DenseNet121中就是使通道数变为原本的一半,源码如下


MobileNet
MobileNet V1将VGG中标准卷积层替换成深度可分离卷积,可以应用在手机端
MobileNet V1将VGG中标准卷积层替换成深度可分离卷积,目的:用更少的参数,更少的运算,达到精度差不多的结果

深度可分离卷积
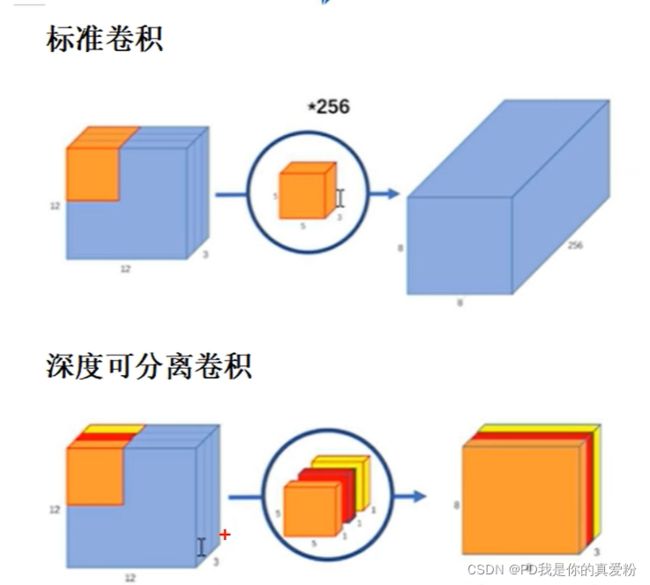
与一般的卷积不同,一般的卷积,在feature map的每一层都会融合原图所有通道的信息;而深度可分离卷积,在第一个卷积层处,会维持feature map的通道只来自于原图的一个特定通道;在最后的逐点卷积时,才会像普通卷积层一样,去融合多个通道的信息
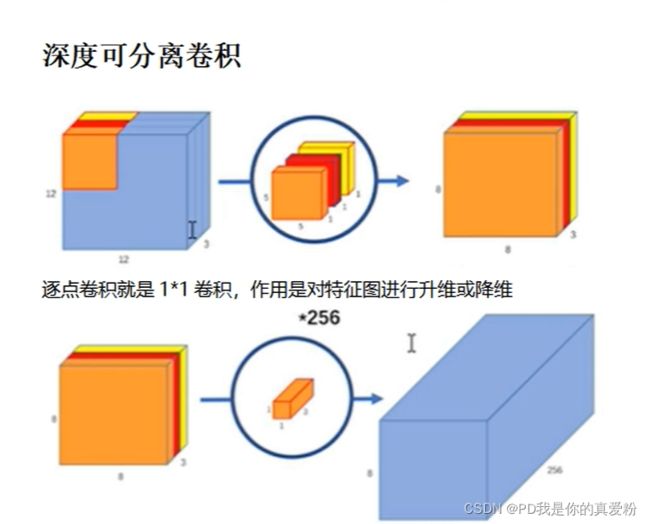
参数个数对比:
- 标准卷积 3*3*3*256 (假设卷积核大小是3*3)
- 深度可分离卷积 3*3*1*3 + 1*1*3*256
Relu6

使用Relu6的三种解释
- 第一种解释
卷积之后通常会接一个ReLU非线性激活,在Mobilev1里面使用ReLU6,ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失
- 第二种解释
普通relu, y=max(0,x), 相当于无限多个bernoulli分布,即无限多个骰子。relu6,y=min(max(0,x),6), 相当于有六个bernoulli分布,即6个硬币,同时抛出正面,这样鼓励网络学习到稀疏特征。网络里面每一个输出n,相当于n个bernoulli分布的叠加。通过实验发现,用6,效果比较好。所以选用了6
- 第三种解释
就是硬件层面的东西,大概意思就是手机的传输是8bits,然后前4位用于储存符号和整数部分,后四位表示浮点部分,那么,整数部分就只能表示0-7的数字;
V1的网络架构
它其实是一个VGG的变形

- 效果比较

V2的改进
V1的卷积单元: 3*3*1*3 + ReLU + 1*1*3*256 + ReLU(深度可分离卷积 + 点积(升维))
V2的卷积单元: 1*1*3*256 + ReLU + 3*3*256*256 + ReLU + 1*1*3*1 + Linear (点积(升维)+ 深度可分离卷积 + 点积(降维))
- ResNet是先做了压缩,再做扩张,MobileNet V2是相反的!
原因:(DW表示深度可分离卷积,PW表示点积)
V2在DW卷积之前新加了一个PW卷积。这么做的原因,是因为DW卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以上一层给的通道数本身就很少的话,DW也只能很委屈的在低维空间提特征,因此效果不够好。现在V2为了改善这个问题,给每个DW之前都配备了一个PW,专门用来升维,定义升维系数t=6,这样不管输入通道C是多还是少,经过第一个PW升维之后,DW都是在相对更高维进行工作的。
- 采用Linear作为激活函数
作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个PW的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用Relu6了。Relu6会对channel数较低的张量tensor造成较大的信息损耗。如下图所示,当原始输入维度数增加到15以后再加Relu,基本不会丢失太多的信息;但如果只把原始输入维度增加到2~5后再加Relu,则会出现较为严重的信息丢失。

- V2也借鉴了ResNet
既然借鉴了ResNet那必然有短接,没啥好说的…