- 学习完MySQL数据库的基本操作后,下面来学习如何用Python连接数据库,并进行数据的插入、查找、删除等操作。
6.9.1 用PyMySQL库操控数据库
- 上一节在phpMyAdmin 中创建了数据库“pachong”,并在其中创建了数据表"test",那么该如何在Python中连接该数据库,并调用其中的数据表呢?
- 首先安装用于操控MySQL的python第三方库PyMySQL,安装命令为"pip install pymysql"。
1.连接数据库
- 首先来学习如何连接之前创建的数据库“pachong”,代码如下:
import pymysql
db = pymysql.connect(host='localhost',port=3306,user='root',password='',database='pachong',charset='utf8')

2.插入数据
- 在Python中连接到数据库后,就可以通过执行SQL语句对数据进行增、删、改、查等操作了。但在执行SQL语句前还需要引入一个会话指针cursor,代码如下:
cur = db.cursor()
- 接着就可以编写SQL语句了,先回顾一下前面学习的插入数据的SQL语句:
INSERT INTO `test`(`company`, `title`, `href`, `date`, `source`) VALUES ('阿里巴巴','标题2','链接2','日期2','来源2')
- 在Python中编写SQL语句时,为了让代码更简洁,数据表名和字段前后都不再加重音符号“`”,代码如下:
sql = 'INSERT INTO test (company, title, href, date, source) VALUES (%s,%s,%s,%s,%s)'
- 和之前的SQL语句稍有不同,这里的“VALUES”后面没有跟着具体的值,而是一些“%s”,有几个字段就写几个“%s”,这里是为了便于之后批量插入多家公司的信息。“%s”成为占位符,代表一个字符串,之后可以传入相应的具体值。

- 写完SQL语句后,再通过如下代码便可将具体的值传到“%s”的位置并执行SQL语句。
cur.execute(sql,(company, title, href, date, source))
db.commit()
- 第1行代码中的cur.execute()函数用于执行SQL语句并传入相应的值(execute是“执行”的意思)。括号中的第1个参数就是刚才编写的SQL语句;第二个参数用来把具体的值传到各个“%s”的位置上,依此类推。
- cur.execute()函数会默认把传入的值都转换为字符串类型,因此,即使是数字型的值(如舆情评分),在SQL语句中也要用“%s”作为占位符。不过如果数据表中设置的字段数据类型是INT,传入的值还是会以数字格式存储在数据表中。
- 地
- 第2行代码中的db.commit()函数是更新数据表的固定写法(commit是提交的意思)。这里插入了一行数据,已经改变了数据表的结构,所有必须用db.commit()函数来提交这个修改。对于数据的插入、删除等修改了数据表的操作,都需要写这行代码来提交修改。
- 最后需要关闭之前引入的会话指针cur和数据库连接,代码如下:
cur.close()
db.close()
company = '阿里巴巴'
title = '测试标题'
href = '测试链接'
date = '测试日期'
source = '测试来源'
import pymysql
db = pymysql.connect(host='localhost',port=3306,user='root',password='',database='pachong',charset='utf8')
cur = db.cursor()
sql = 'INSERT INTO test (company, title, href, date, source) VALUES (%s,%s,%s,%s,%s)'
cur.execute(sql,(company, title, href, date, source))
db.commit()
cur.close()
db.close()
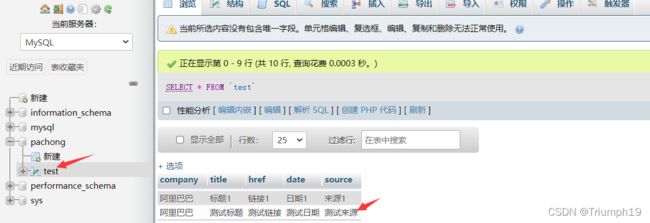
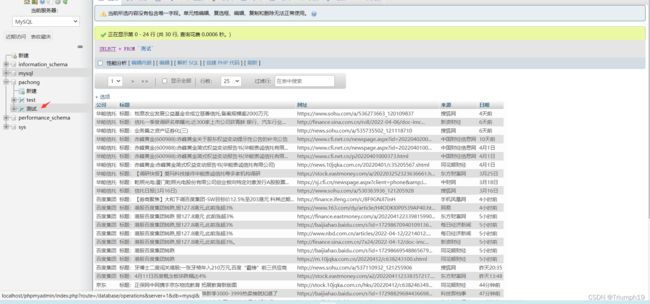
- 运行代码后,打开phpMyAdmin查看数据表“test”,可以看到其中新增的一条数据,如下图所示。
- 再往数据表中插入数据的实战中,往往需要修改的就是上述代码中的SQL语句,以及cur.execute()函数的参数,其余的代码大多都是固定写法。
- 此外,如果只是插入一条数据,也可以用如下写法:
sql = "INSERT INTO test (company, title, href, date, source) VALUES ('阿里巴巴','标题2','链接2','日期2','来源2')"
- 这里将SQL语句前后的单引号换成了双引号,这样就不会和公司名称等字符串中的单引号产生冲突(也可以在外层用单引号,里面用双引号)。不过这汇总写法不适合用于插入或读取数据,因此简单了解即可。
3.查找数据
- 查找数据的思路与插入数据的思路类似,同样是通过执行SQL语句来完成。先回顾一下在phpMyAdmin中查找数据的SQL语句,其中LIKE也可以换成“=”号:
sql = "INSERT INTO test (company, title, href, date, source) VALUES ('阿里巴巴','标题2','链接2','日期2','来源2')"
- 那么要用Python查找company(公司名称)为“阿里巴巴”的数据,可以使用如下代码:
import pymysql
db = pymysql.connect(host='localhost',port=3306,user='root',password='',database='pachong',charset='utf8')
company = '阿里巴巴'
cur = db.cursor()
sql = 'SELECT * FROM test WHERE company = %s'
cur.execute(sql,company)
data = cur.fetchall()
print(data)
db.commit()
cur.close()
db.close()
- 上述代码与插入数据的代码在思路上类似,都是先连接数据库,然后利用cursor获取会话指针,进而通过cur.execute()函数执行SQL语句。因为只有一个占位符(company=%s),所以cur.execute()函数的第2个参数就只有company。
- 执行的SELECT*语句知识查找数据,并没有把数提取出来,所以还要用data = cur.fetchall()来提取所有数据,并赋给变量data,这也是提取数据的固定写法。其余代码的含义参见注释。
- 代码运行效果如下:

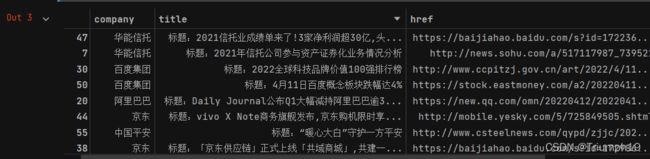
- 可以看到所有公司名称为“阿里巴巴”的数据都被筛选出来了。从包围内容的一层层括号可以看出,提取出的数据是嵌套结构的元组。元组和列表非常类似,区别只是包围的符号不同,并且元组中的元素不可修改,所以可以借用列表的知识来进一步处理元组。例如,要提取每条新闻的标题,可以在上面的代码之后写如下代码:
for i in range(len(data)):
print(data[i][1])
- 与提取元素的方法一样,通过该data[i]提取大元组的小元组,data[0]就是第1个小元组(‘阿里巴巴’, ‘标题1’, ‘链接1’, ‘日期1’, ‘来源1’)。要提取这个小元组里的标题(第二个元素),可以用data[0][1]实现。结合for循环语句就可以提取每一条新闻的标题了。
- 如果筛选条件不止一个,可以用“AND”来连接。例如,要通过company(公司名称)和title(标题)两个筛选条件来查找数据,代码如下:
sql = 'SELECT * FROM test WHERE company = %s AND title = %s'
cur.execute(sql,(company,title))
- 第1行代码的SQL语句用“AND”连接了两个筛选条件,第2行代码用cur.execute()函数执行SQL语句时就要传入两个参数,这两个参数需要用括号包围起来,写成(company,title)。如果还有更多的筛选条件,可以模仿上述形式添加。
4.删除数据
- 相对于插入和查找数据,删除数据的使用频率要低得多。先回顾一下在phpMyAdmin中删除数据的SQL语句:
DELETE FROM `test` WHERE `company` = '百度'
- 在Python中执行这个SQL语句的方法和之前类似,其核心代码如下:
cur = db.cursor()
sql = 'DELETE FROM test WHERE company = %s'
cur.execute(sql,company)
import pymysql
db = pymysql.connect(host='localhost',port=3306,user='root',password='asdfg12345',database='pachong',charset='utf8')
company = '百度'
cur = db.cursor()
sql = 'DELETE FROM test WHERE company = %s'
cur.execute(sql,company)
data = cur.fetchall()
db.commit()
cur.close()
db.close()
- 运行代码后,数据表“test”中所有company(公司名称)为“阿里巴巴”的数据记录就都被删除了。
6.9.2 案例实战:百度新闻数据爬取与存储
- 本案例将从百度新闻爬取的数据写入MySQL数据库,并进行数据的去重处理。
1.基本的数据爬取与存储
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=4&tn=news&wd=' + company
res = requests.get(url,headers=headers).text
import re
p_date = '(.*?)'
p_source = '(.*?)'
date = re.findall(p_date,res)
source = re.findall(p_source,res)
p_href = '
baidu('阿里巴巴')
import pymysql
companies = ['阿里巴巴','华能信托']
for i in range(len(companies)):
company = companies[i]
db = pymysql.connect(host='localhost', port=3306, user='root', password='', database='pachong',
charset='utf8')
cur = db.cursor()
sql = 'DELETE FROM test WHERE company = %s'
cur.execute(sql,company)
data = cur.fetchall()
db.commit()
cur.close()
db.close()
- 要批量爬取多家公司的数据并写入数据库,可用for循环语句来实现,代码如下:
companies = ['华能信托','阿里巴巴','百度集团','腾讯','京东']
for company in companies:
try:
baidu(company)
print('爬取并写入数据库成功')
except:
print('爬取并写入数据库失败')
2.写入数据时进行去重处理
- 数据库不能自动识别重复信息,所以同样的数据很有可能被重复写入数据库,这样不仅会浪费存储空间,而且会给数据提取造成很多麻烦。因此,在写入数据库前最好进行去重处理,其思路为:爬取到每一条新闻的数据后,先在数据库中进行查找,如果发现该新闻的标题已经存在,就不把该新闻写入数据库。
- 首先进行数据的查找,代码如下:
sql_1 = 'SELECT * FROM test WHERE company = %s'
cur.execute(sql_1,company)
data_all = cur.fetchall()
title_all = []
for j in range(len(data_all)):
title_all.append(data_all[j][1])
- 上述代码和之前在数据库中查找数据的代码基本一致,唯一的变化在于这里创建了一个空列表title_all,并用append()函数将每条新闻的标题存入该列表。根据前面的讲解,cur.fetchall()返回的data_all是一个嵌套结构的元组,所以用data_all[j][1] 的方式提取每条新闻的标题。此外,之前在for i in range(len(title))中已经用了i作为循环变量,所以这里用j作为循环变量。
- 这里的for循环语句还可以写成for j in data_all,这样的j就不再是一个数字,而是data_all这个大元组中的一个小元组,而j[1]就是小元组中的新闻标题,改写后的代码如下:
for j in data_all:
title_all.append(j[1])
- 获取数据库中存储的每条新闻的标题后,就可以对新爬取的新闻进行筛选了。只需判断新爬取到的新闻标题是否在列表title_all里,如果不在,说明它确实是一条新的新闻,可以写入数据库,代码如下:
if title[i] not in title_all:
sql_2 = 'INSERT INTO test (company, title, href, date, source) VALUES (%s,%s,%s,%s,%s)'
cur.execute(sql_2,(company, title[i], href[i], date[i], source[i]))
db.commit()
- 这里使用的是not in 逻辑判断,就是“不在”的意思,即如果新爬取到的新闻标题不在列表title_all里,那么就执行下面的将数据写入数据库的操作。
- 把查询数据、筛选数据和插入数据的操作汇总在一起,代码如下:
for i in range(len(title)):
db = pymysql.connect(host='localhost',port=3306,user='root',password='asdfg12345',database='pachong',charset='utf8')
cur = db.cursor()
sql_1 = 'SELECT * FROM test WHERE company = %s'
cur.execute(sql_1,company)
data_all = cur.fetchall()
title_all = []
for j in range(len(data_all)):
title_all.append(data_all[j][1])
if title[i] not in title_all:
sql_2 = 'INSERT INTO test (company, title, href, date, source) VALUES (%s,%s,%s,%s,%s)'
cur.execute(sql_2,(company, title[i], href[i], date[i], source[i]))
db.commit()
cur.close()
db.close()
去重处理实战的源代码
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=4&tn=news&wd=' + company
res = requests.get(url,headers=headers).text
import re
p_date = '(.*?)'
p_source = '(.*?)'
date = re.findall(p_date,res)
source = re.findall(p_source,res)
p_href = '
href = re.findall(p_href,res)
p_title = '
title=re.findall(p_title,res,re.S)
for i in range(len(title)):
title[i] = re.sub('<.*?>','',title[i])
print(str(i+1) + '.' + title[i] + '(' + source[i] + ' '+ date[i] + ')')
print(href[i])
import pymysql
for i in range(len(title)):
db = pymysql.connect(host='localhost',port=3306,user='root',password='asdfg12345',database='pachong',charset='utf8')
cur = db.cursor()
sql_1 = 'SELECT * FROM test WHERE company = %s'
cur.execute(sql_1,company)
data_all = cur.fetchall()
title_all = []
for j in range(len(data_all)):
title_all.append(data_all[j][1])
if title[i] not in title_all:
sql_2 = 'INSERT INTO test (company, title, href, date, source) VALUES (%s,%s,%s,%s,%s)'
cur.execute(sql_2,(company, title[i], href[i], date[i], source[i]))
db.commit()
cur.close()
db.close()
companies = ['华能信托','阿里巴巴','百度集团','腾讯','京东','中国平安']
for company in companies:
try:
baidu(company)
print('爬取并写入数据库成功')
except:
print('爬取并写入数据库失败')
6.9.3 用pandas库操控数据库
- 前面讲解的是用Python操控数据库的常规方法,本节则要讲解如何直接使用pandas库读写数据库。这种方式需要实现安装最为辅助工具的SQLAlchemy库,安装命令为“ pip install sqlalchemy”。
1.连接数据库
- 使用SQLAlchemy库中的create_engine()函数来初始化数据库连接,代码如下:
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:@localhost:3306/pachong')
- 第1行代码导入SQLAlchemy库中的create_engine()函数。第2行代码用create_engine()函数创建数据库连接并赋值给变量engine,参数字符串各部分的含义如下:
数据库类型+数据库驱动程序://数据库用户名:密码@数据库服务器IP地址:端口/数据库名
- 因此,第2行代码的参数字符串含义为连接到MySQL数据库,使用PyMySQL库作为驱动程序,用户名为root,密码为空,数据库服务器IP地址为本机,端口为3306,要连接的数据库名为“pachong”。
- 用SQLAlchemy库连接数据库后,就可以用pandas库的read_sql_query()函数从数据库中读取数据,用to_sql()函数将数据写入数据库。
2.读取数据
- 用pandas 库的read_sql_query()函数可以快速读取数据库中的数据,演示代码如下:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:asdfg12345@localhost:3306/pachong')
sql = "SELECT * FROM test"
df = pd.read_sql_query(sql,engine)
3.写入数据
- 用pandas库中的to_sql()函数可以快速将数据写入数据库,演示代码如下:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:asdfg12345@localhost:3306/pachong')
df = pd.read_excel('百度新闻-多家.xlsx')
df.to_sql('test',engine,index=False,if_exists='append')

- 如果数据库“pahchong”中不存在数据表“test”,会自动创建该数据表。如果将参数’test’改成“测试”,则运行代码后会自动在数据库“pahchong”里新建一个名为“测试”的数据表,并将数据写入该数据集。其文本数据的默认格式为TEXT长文本格式,与之前使用的VARCHAR常规文本格式区别不大。
- 将上面最后一行代码写成:
df.to_sql('测试',engine,index=False,if_exists='append')
4.实战技巧
- 下面讲解本书作者总结的一些用pandas库操控数据表的小技巧,可以帮助大家解决实战中遇到的一些问题。
(1)数据格式设置
- 有时用pandas库直接将数据写入数据库,会出现报错提示“‘numpy.float64’ object has no attribute ‘translate’”。这个报错是数据格式的问题导致的,解决办法是利用astype()函数价格DataFrame中的数据格式转换为字符串格式。演示代码如下:
df = df.astype('str')
(2)在SQL语句中传入动态参数(未能运行成功)
- 有时SQL语句中的参数是动态变化的,例如,要在数据表“test”中提取今天的数据,而今天的日期是动态变化的,此时就要以传入动态参数的方式编写SQL语句。演示代码如下:
today = time.strftime('%Y-%m-%d')
sql = 'SELECT * FROM test WHERE 日期 = %(date)s'
df_old = pd.read_sql_query(sql,engine,params={'date':today})
- 第1行代码中today为今天的日期(字符串格式),注意需提前导入time库。
- 第2行代码编写SQL语句,用于在数据表“test”中提取今天的数据,其中的date就是一个动态参数(可以换成其他变量名,只要与第3行代码中的变量名一致即可),%()s表示以字符串格式传入。
- 第3行代码中,read_sql_query()函数括号中的参数增加了一个参数params,代表要为SQL语句传入的动态参数,其值为包含一个键值对的字典,其中的键’date’就是第2行代码中定义的动态参数,而键对应的值today则是第1行代码中定义的日期变量。如果需要,可以传入多个动态参数,例如,传入两个动态参数的写法params={‘date’:today,‘score’:today_score}。
(3)数据去重的另一种思路
- 用pandas库可以将数据快速去重并写入数据库。假设df为刚爬取的新闻数据,df_old为数据库里存储的新闻数据,df和df_old有重复的内容,现在要把在df中而不在df_old中的数据(也就是用数据库已有数据不重复的新闻数据)写入数据库,那么可以通过如下代码进行去重(这里认为新闻标题重复就是重复内容):
df_new = df[~df['标题'].isin(df_old['标题'])]
- 这里有两个新知识点:一个是isin()函数,另一个是“~”符号的应用。首先讲解isin()函数:该函数接收一个列表或数组(如上面的df_old[‘标题’])作为参数,判断目标列(如上面的df[‘标题’])中的元素是否在列表中,如果在则返回Ture,否则返回False。因此,如下代码的含义就是筛选同时出现在df[‘标题’]列和df_old[‘标题’]列中的内容。
df_new = df[df['标题'].isin(df_old['标题'])]
- 理解了isin()函数,再来讲解“~”符号,它的作用是取反,也就是去选中数据之外的数据,因此,
df_new = df[~df['标题'].isin(df_old['标题'])]就表示选择df[‘标题’]列中独有的内容(也就是没有出现在df_old[‘标题’]列中的内容),这样便去除了df和df_old重复的内容。
- 下面再举一个例子,代码如下:
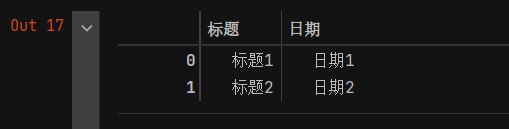
import pandas as pd
df = pd.DataFrame({'标题':['标题1','标题2'],'日期':['日期1','日期2']})
df_old = pd.DataFrame({'标题':['标题2','标题3'],'日期':['日期2','日期3']})
- 此时df和df_old的内容如下:
- 执行如下代码后:
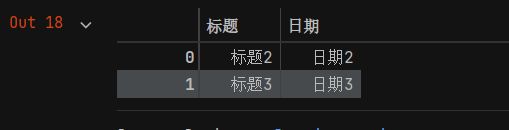
df_new = df[~df['标题'].isin(df_old['标题'])]
- 此时df_new的内容如下图所示,可以看到成功筛选出来df中独有的内容。感兴趣的读者可以把代码中的“~”符号去掉,看看结果如何。

- 成功去重后,就可以用to_sql()函数将处理好的df_new写入数据库了。
(4)取两个表格中的非重复值
- 前面讲解的数据去重是保留df中独有的内容,如果想同时保留df和df_old中的独有内容,也就是它们的非重复值,可以使用如下代码:
df_new = df.append(df_old)
df_new = df_new.drop_duplicates(keep=False)

(5)模糊筛选
- 要用pandas库对数据进行模糊筛选,可以使用contains()函数,其功能是筛选目标列中含有某一关键词的行。其基本语法格式如下:
df['列名'].str.contains(关键词)
- 其中先用str属性将内容转换为字符串,然后才能用contains()函数进行筛选(因为非字符串格式数据不能和字符串数据进行比较)。
- 举例来说,假设用如下代码创建了一个DataFrame:
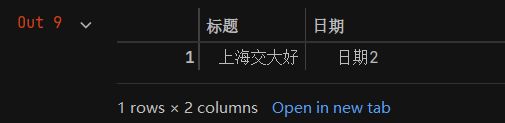
df = pd.DataFrame({'标题':['华能信托好','上海交大好'],'日期':['日期1','日期2']})
- 此时df的内容如下图所示。
- 接着在df中筛选“标题”列中含有关键词“上海交大”的行,代码如下:
df_new = df[df['标题'].str.contains('上海交大')]
- 此时df_new的内容如右图所示,成功筛选出了指定列含有特定关键词的行内容。