python学习----实验分析k-均值初始化的影响
Empirical evaluation of the impact of k-means initialization Evaluate
the ability of k-means initializations strategies to make the
algorithm convergence robust as measured by the relative standard
deviation of the inertia of the clustering (i.e. the sum of squared
distances to the nearest cluster center).The first plot shows the best inertia reached for each combination of
the model (KMeans or MiniBatchKMeans) and the init method
(init=“random” or init=“kmeans++”) for increasing values of the n_init
parameter that controls the number of initializations.The second plot demonstrate one single run of the MiniBatchKMeans
estimator using a init=“random” and n_init=1. This run leads to a bad
convergence (local optimum) with estimated centers stuck between
ground truth clusters.The dataset used for evaluation is a 2D grid of isotropic Gaussian
clusters widely spaced.
# Author: Olivier Grisel 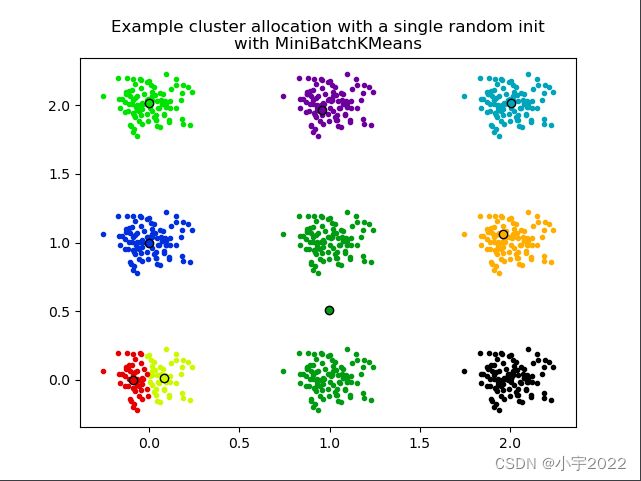

Empirical evaluation of the impact of k-means initialization