Jedis访问Rides数据库(二 )(存储Set、存储SortedSet、存储Hash集合)
一:通过String 访问RedisSet集合:
我们知道set集合是无序的,无序且唯一,所以一个value只能存取一次哦,第二次存取的时候即为无效。
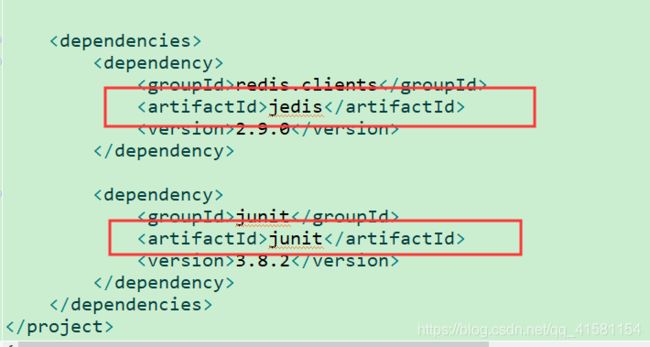
步骤一:添加依赖 在此处我们需要添加Jedis依赖,并且添加Junit测试依赖
在测试类中测试各种方法:
package com.bjsxt.test;
import java.util.Set;
import org.junit.Test;
import redis.clients.jedis.Jedis;
public class JedisSetTest {
@Test
public void jedisSetTest1() {
Jedis jedis=new Jedis("192.168.224.11", 6379);
//set集合添加数据
/*jedis.sadd("jset", "s1","s2","s3","s4");*/
/*jedis.sadd("jset1", "ss1","ss2","ss3","ss4");*/
//获取set集合的个数
/*Long size = jedis.scard("jset");
System.out.println(size);*/
//获取差集,差集与 sdiff 元素位置的顺序有关,该方法是获取jset与jset1的差值
/*Set jsetdiff = jedis.sdiff("jset","jset1");
System.out.println(jsetdiff);
上下两个方法获取的差值不相同
/*Set jsetdiff2 = jedis.sdiff("jset1","jset");
System.out.println(jsetdiff2);*/
//获取jset与jset1的差值,将其保存到jset2的set键中
/*jedis.sdiffstore("jset2", "jset","jset1");*/
//获取两个集合的交集,与顺序无关
/*Set jSet = jedis.sinter("jset","jset1");
System.out.println(jSet);*/
//判断键为jset中是否有s1,返回boolean
/*Boolean flag = jedis.sismember("jset", "s1");
System.out.println(flag);*/
//获取数据库中键为jset的set集合的全部成员
/*Set set = jedis.smembers("jset");
System.out.println(set);*/
//获取两个集合的并集
/*Set union = jedis.sunion("jset","jset1");
System.out.println(union);*/
//删除键为jset的集合元素为s1,s2,返回值是删除成功的个数
/*jedis.srem("jset", "s1","s2");*/
}
}
二:使用Jedis访问redis的sortedSet类型数据

一:在访问时我们也是先添加两个相同的依赖(Jedis依赖和Junit测试依赖)ps:忽略
二:测试Jedis访问Redis中SoredSet类型:
package com.bjsxt.test;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import org.junit.Test;
import redis.clients.jedis.Jedis;
public class JedisScoreTest {
@Test
public void scoreTest() {
Jedis jedis=new Jedis("192.168.224.11", 6379);
//对Redis数据库添加SortedSet集合 key->map
/*Mapmap=new HashMap<>();
map.put("赵四", 1.0);
map.put("刘能", 3.0);
jedis.zadd("score", map);*/
//获得当前Set集合的数据个数
/*Long zcard = jedis.zcard("score");
System.out.println(zcard);*/
//返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量
/*Long zcount = jedis.zcount("score", 2, 3);
System.out.println(zcount);*/
//指定数据库中的key值为(score),对其中的map中的key(赵四),在原有的基础上添加5
/*jedis.zincrby("score", 5, "赵四");*/
//选择数据库中 键为score索引为0-1中的map的键值,按照成员的score从小到大的顺序进行排列
/*Set zrange = jedis.zrange("score", 0, 1);
System.out.println(zrange);*/
//查找数据库中键为score的map对象为刘能的排列顺序,按照score从小到大的顺序进行排列
/*Long zrank = jedis.zrank("score", "刘能");
System.out.println(zrank);*/
//删除指定键为score的map中键为qq的数据
/*Long zrem = jedis.zrem("score", "qq");
System.out.println(zrem);*/
//返回键为score中map的key为刘能的score值
/*Double zscore = jedis.zscore("score", "刘能");
System.out.println(zscore);*/
}
}
三:Jedis访问Redis中的hash类型

一:添加依赖(Jedis依赖和Junit依赖)
二:测试:
package com.bjsxt.test.hash;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import org.junit.Test;
import redis.clients.jedis.Jedis;
public class JedisHashTest {
/***
* 测试hash类型数据的访问
*/
@Test
public void hashTest() {
Jedis jedis=new Jedis("192.168.25.100",6379);
/***
* 保存hash类型数据
*/
/*jedis.hset("has", "name", "小强");
jedis.hset("has", "age", "23");
jedis.hset("has", "sex", "未知");
*/
//创建Map集合
Map hash=new HashMap<>();
hash.put("bmw", "别摸我");
hash.put("price", "120000");
hash.put("address", "北京");
//一次保存整个Map集合
//jedis.hmset("has2", hash);
//获得redis数据库中map集合中指定field的值
/*String value = jedis.hget("has", "name");
System.out.println(value);*/
//获得redis数据库中map集合中指定多个field对应的值
/*List hmget = jedis.hmget("has2", "bmw","price","address");
System.out.println(hmget);
*/
//通过指定redis数据库的键,获得Map集合
/*Map maps = jedis.hgetAll("has");
for(Entry e:maps.entrySet()) {
System.out.println(e.getKey()+"\t"+e.getValue());
}*/
//删除hash集合中,指定field对应的值
//jedis.hdel("has", "name","age","address");
//判断hash集合中,是否保存指定的field对应的值
/*Boolean hexists = jedis.hexists("has2", "address");
System.out.println(hexists);*/
//获得hash集合中所有的key
/*Set hkeys = jedis.hkeys("has2");
System.out.println(hkeys);*/
//获得hash集合中所有的value
/*List hvals = jedis.hvals("has2");
System.out.println(hvals);*/
//获得hash集合的长度
Long hlen = jedis.hlen("has2");
System.out.println(hlen);
}
}