Keras深度学习应用1——基于卷积神经网络(CNN)的人脸识别(下)
基于CNN的人脸识别(下)
- 代码下载
- 三、人脸识别数据集
-
- 3.1 数据集划分
- 3.2 数据增强
- 四、搭建CNN网络模型
-
- 4.1 搭建CNN模型
- 4.2 模型训练
- 4.3 加载需要识别的人脸
Keras深度学习应用1——基于卷积神经网络(CNN)的人脸识别(上),上一篇博客已经详细叙述了CNN的理论基础,该篇博客具体叙述使用Keras实现人脸识别的具体代码。
代码下载
Github源码下载地址:
https://github.com/Kyrie-leon/CNN-FaceRec-keras
三、人脸识别数据集
MegaFace人脸库是美国华盛顿大学发布维护的一个百万级别规模的人脸库,是目前世界上最为权威的人脸识别性能指标之一。该人脸库具有数据量大、图像具有随机性等特点。其中一些人脸数据集年龄跨度大,为识别增加了难度。使用该人脸库需要先提交申请,获得下载账号和密码之后才能下载数据集。本文选取MegaFace人脸库的部分人脸作为实验数据集。
MegaFace人脸数据集官网
链接:https://pan.baidu.com/s/1aCjxQnKrnGY6hG-Mifdm2g 提取码:w5wu
下载人脸训练集图片
链接:https://pan.baidu.com/s/1rQEUk0toOSDYoG-frK4wBg 提取码:73uy 下载人脸测试集图像
3.1 数据集划分
本实验选取MegaFace人脸库中40个人的6127张图像作为作为实验数据集,其中训练集4742张,验证集1185张,测试集200张。
Name_label = [] #姓名标签
path = './data/face/' #数据集文件路径
dir = os.listdir(path) #列出所有人
label = 0 #设置计数器
#数据写入
with open('./data/train.txt','w') as f:
for name in dir:
Name_label.append(name)
print(Name_label[label])
after_generate = os.listdir(path +'\\'+ name)
for image in after_generate:
if image.endswith(".png"):
f.write(image + ";" + str(label)+ "\n")
label += 1
通过上述代码将实验数据集写入train.txt文件中实现数据的迭代读取,减少内存占用率,提高训练速度。
# 打开数据集的txt
with open(r".\data\train.txt","r") as f:
lines = f.readlines()
#打乱数据集
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 80%用于训练,20%用于测试。
num_val = int(len(lines)*0.2) #
num_train = len(lines) - num_val #4715
通过上述代码实现数据集的划分,并设置随机种子使得同类数据不会过度集中影响实验准确率。
3.2 数据增强
通过对原训练集人脸图片进行模糊、旋转、添加噪声制造出多种复杂的“环境”,在原有的数据基础上更大的扩充数据量,进而提升识别准确率;通过模拟不良的成像环境以及干扰,更大的强化卷积神经网络对不同恶劣条件下进行人脸识别的适应性,代码如下:
def rand(a=0, b=1):
return np.random.rand()*(b-a) + a
def get_random_data(image, input_shape, random=True, jitter=.1, hue=.1, sat=1.2, val=1.2, proc_img=True):
h, w = input_shape
new_ar = w/h * rand(1-jitter,1+jitter)/rand(1-jitter,1+jitter)
scale = rand(.7, 1.3)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
# place image
dx = int(rand(0, w-nw))
dy = int(rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (0,0,0))
new_image.paste(image, (dx, dy))
image = new_image
# flip image or not
flip = rand()<.5
if flip:
image = image.transpose(Image.FLIP_LEFT_RIGHT)
# distort image
hue = rand(-hue, hue)
sat = rand(1, sat) if rand()<.5 else 1/rand(1, sat)
val = rand(1, val) if rand()<.5 else 1/rand(1, val)
x = rgb_to_hsv(np.array(image)/255.)
x[..., 0] += hue
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x>1] = 1
x[x<0] = 0
image_data = hsv_to_rgb(x)*255 # numpy array, 0 to 1
return image_data
效果图:

四、搭建CNN网络模型
4.1 搭建CNN模型
本文搭建的卷积神经网络模型如图所示,该模型一共10层,由1个输入层,3个卷积层、3个最大池化层、1个Flatten层、1个全连接层和1个Softmax层构成。
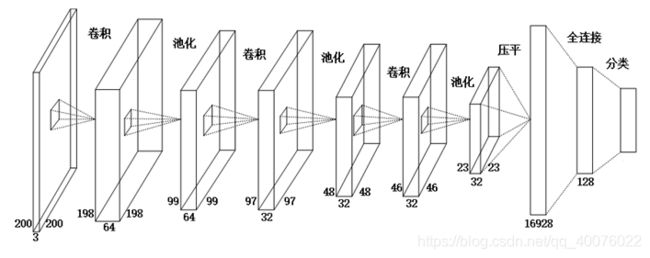
首先,输入层的输入数据为一个200×200×3的图片矩阵,第一个卷积层的卷积核为3×3的大小,默认的滑动步长为1个像素点。矩阵经过卷积核的卷积运算后,形成了一个198×198×64的矩阵数据,接下来经过2×2尺寸、默认滑动步长为2的最大池化层进行池化处理,特征缩小为99×99×64的矩阵数据。
然后,第一个最大池化层输出的99×99×64的矩阵数据作为第二个卷积层的输入数据,经过第二个3×3尺寸卷积核、滑动步长为1的卷积层进行卷积运算后,得到一个97×97×32的矩阵数据,再对该矩阵数据进行2×2尺寸、滑动步长为2的最大池化层进行池化处理,特征缩小为48×48×32的特征矩阵,将该特征矩阵传入Dropout层。Dropout层用于抑制模型的过度拟合,设置的概率为25%。
在最后一层的卷积层和最大池化层中,卷积和池化的过程与前两层类似,将48×48×32的特征矩阵与3×3尺寸卷积核进行卷积,得到一个46×46×32的矩阵数据,再传入2×2尺寸的最大池化层进行最大池化运算,特征最后缩小为23×23×3的特征矩阵,将该矩阵传入概率为25%的Dropout层来更新参数。
数据在经过上述的卷积池化过程后,输出的数据是一个二维向量,而模型需要对卷积运算结果进行分类,因此需要对该二维矩阵降维成一维矩阵,这里需要用到Faltten层,该层的把多维输入数据一维化,提供了从卷积层到全连接层的过渡作用。在这一步中,23×23×32的特征矩阵被“压平”成一组一维矩阵,共计包含16928个特征值,将这些特征值传入全连接层。
本文设计的全连接层含有128个神经元,将16928个特征值与128个神经元进行全连接,经过relu函数激活处理后生成128个特征数据,再传入概率为50%的Dropout层来做为Softmax层的输入数据。
最后,本文把全连接层的128个特征数据与分类标签的数量进行全连接,经过Softmax层进行人脸的分类识别。实现代码如下:
def MmNet(input_shape, output_shape):
model = Sequential() # 建立模型
# 第一层
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第二层
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 第三层
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 全连接层
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
# 全连接层
model.add(Dense(output_shape, activation='softmax'))
print("-----------模型摘要----------\n") # 查看模型摘要
model.summary()
return model
4.2 模型训练
在训练开始阶段,使用遍历的方法分别将各个子目录下的人脸图片归一化为200×200像素,并将图像转换成矩阵的形式读取到内存中,把数据集划分为训练集和测试集,然后分别对训练集和测试集添加人脸识别的分类标签。
接下来开始对搭建好的神经网络模型进行训练,本文选取Adam下降法作为优化器,学习率为0.01,利用GPU加速的方式进行训练。将处理好的数据按照集合标签传入神经网络中,进行迭代训练,在每次迭代过程中对每次训练结果进行评估并将训练好的网络模型保存到本地以使得迭代不中断。实现代码如下:
#3. 训练模型
def train(model, batch_size):
model = model #读取模型
#定义保存方式,每三代保存一次
checkpoint_period1 = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
period=3
)
#学习率下降方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='val_acc',
patience=3,
verbose=1
)
#val_loss一直不下降意味模型基本训练完毕,停止训练
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
#交叉熵
model.compile(loss = 'categorical_crossentropy',
optimizer =Adam(lr=1e-4),
metrics=['accuracy'])
#Tebsorboard可视化
tb_Tensorboard = TensorBoard(log_dir="./model", histogram_freq=1, write_grads=True)
#开始训练
history = model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size, True),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size, False),
validation_steps=max(1, num_val//batch_size),
verbose = 1,
epochs=10,
initial_epoch=0,
callbacks=[early_stopping, checkpoint_period1, reduce_lr, tb_Tensorboard])
return history, model
4.3 加载需要识别的人脸
该节代码实现过程为:加载训练好的神经网络模型、加载需要识别的人脸图像、识别、将识别结果打印出来并将该人脸照片显示在窗口中,窗口的标题为该图片路径名称,具体代码实现
import os
import glob
import h5py
import keras
import numpy as np
from tkinter import *
from tkinter import ttk
from PIL import Image,ImageTk
from keras.models import load_model
from keras.preprocessing.image import load_img, img_to_array
from keras.applications.imagenet_utils import preprocess_input
from keras.models import Model
from Name import *
img_rows = 300 # 高
img_cols = 300 # 宽
def letterbox_image(image, size):
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (0,0,0))
new_image.paste(image, ((w-nw)//2, (h-nh)//2))
return new_image
def test_accuracy(lines, model):
t = 0
n = len(lines)
i = 0 #计数器
# 遍历测试集数据
for i in range(n):
name = lines[i].split(';')[0] #人脸图像名字xxx_xxx.png
label_name = (lines[i].split(';')[1]).strip('\n') #人脸数字标签0-39
label_name = int(label_name)
file_name = str(Name.get(label_name)) #对应人名str
# 从文件中读取图像
img = Image.open(r".\data\test" +"\\"+ name)
img = np.array(letterbox_image(img,[img_rows,img_cols]),dtype = np.float64)
img = preprocess_input(np.array(img).reshape(-1,img_cols,img_rows,3))
pre_name = model.predict_classes(img) # 返回预测的标签值
print(int(pre_name),label_name)
if int(pre_name) == label_name:
t+=1
print(t/n)
def main():
#获取模型权重h5文件
model = load_model('./logs/easy1.h5')
with open('./data/test.txt','r') as f:
lines = f.readlines()
for img_location in glob.glob('./data/test/*.png'): # 限制测试图像路径以及图像格式
img = load_img(img_location)
img = img_to_array(img)
#图像处理
img = preprocess_input(np.array(img).reshape(-1,img_cols,img_rows,3))
img_name = (img_location.strip("face\\")).rstrip(".png")
pre_name = model.predict_classes(img) # 返回预测的标签值
print(pre_name)
pre = model.predict(img)
for i in pre_name:
for j in pre:
name = Name.get(i)
#print(name)
# if name != "Audrey_Landers":
acc = np.max(j) * 100
print("\nPicture name is [%s]\npPredicted as [%s] with [%f%c]\n" %(img_name, name, acc, '%'))
MainFrame = Tk()
MainFrame.title(img_name)
MainFrame.geometry('300x300')
img = Image.open(img_location)
img = ImageTk.PhotoImage(img)
label_img = ttk.Label(MainFrame, image = img)
label_img.pack()
MainFrame.mainloop()
if __name__ == '__main__':
main()