深度学习之基于opencv和CNN实现人脸识别
这个项目在之前人工智能课设上做过,但是当时是划水用的别人的。最近自己实现了一下,基本功能可以实现,但是效果并不是很好。容易出现错误识别,或者更改了背景之后识别效果变差的现象。个人以为是数据选取的问题,希望路过的大佬批评指正。
所需要的库
tensorflow-gpu 2.0.0
Keras 2.3.1
opencv-python 4.5.1.48
numpy 1.20.2
1.数据集获取
这个数据集是通过自己电脑的摄像头获取的,也可以通过一段视频获取。这一过程是建立自己的人脸库。通过Opencv中的CascadeClassifier人脸识别分类器来实现。
部分代码:
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):
cv2.namedWindow(window_name)
# 视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx,cv2.CAP_DSHOW)
# 告诉OpenCV使用人脸识别分类器
classfier = cv2.CascadeClassifier('E:\ProgramData\Anaconda3\Lib\site-packages\cv2\data\haarcascade_frontalface_alt.xml')
# 识别出人脸后要画的边框的颜色,RGB格式
color = (0, 255, 0)
num = 0
while cap.isOpened():
ok, frame = cap.read() # 读取一帧数据
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将当前桢图像转换成灰度图像
# 人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 将当前帧保存为图片
img_name = '%s/%d.jpg' % (path_name, num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > (catch_pic_num): # 如果超过指定最大保存数量退出循环
break
# 画出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, 'num:%d' % (num), (x + 30, y + 30), font, 1, (255, 0, 255), 4)
# 超过指定最大保存数量结束程序
if num > (catch_pic_num): break
# 显示图像
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
效果如下所示:

本人的人脸库中一共有三个数据集:

2.数据集处理
数据集处理包括捕捉人脸+数据集灰度化,将源文件路径中的数据经过处理之后保存到目标文件中。
部分代码:
try:
#读取照片,第一个元素是文件名
resultArray = readALLImg(sourcePath,*suffix)
#对list中的图片逐一进行检查,找出其中的人脸然后写到目标文件夹中
count = 1
face_cascade = cv2.CascadeClassifier('E:\ProgramData\Anaconda3\Lib\site-packages\cv2\data\haarcascade_frontalface_alt.xml')
for i in resultArray:
if type(i) != str:
gray = cv2.cvtColor(i,cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray,1.3,5)
for (x,y,w,h) in faces:
listStr = [str(int(time.time())),str(count)] #以时间戳和读取的排序作为文件名称
fileName = ''.join(listStr)
f = cv2.resize(gray[y:(y+h),x:(x+w)],(200,200))
cv2.imwrite(objectPath+os.sep+'%s.jpg'%fileName,f)
count+=1
except IOError:
print('error')
else:
print('Already read ' + str(count-1) +' Faces to Destination '+objectPath)
经过处理之后的效果如下所示:

注:并不是所有的图片都会转化为灰度图片,因为捕捉器在识别的时候有可能出错,个别的图片无法识别。我的数据集采用了1500张图片。
3.划分训练集和测试集
训练集和测试集采用8:2的比例,所有的图片经过归一化处理,大小为128*128的灰度图片,随机打乱。
部分代码:
#将数据集打乱随机分组
X_train,X_test,y_train,y_test = train_test_split(imgs,labels,test_size=0.2,random_state=random.randint(0, 100))
#重新格式化和标准化
X_train = X_train.reshape(X_train.shape[0],1,self.img_size,self.img_size)/255.0
X_test = X_test.reshape(X_test.shape[0],1,self.img_size,self.img_size)/255.0
# 将labels转成 binary class matrices
y_train = np_utils.to_categorical(y_train, num_classes=counter)
y_test = np_utils.to_categorical(y_test, num_classes=counter)
4.模型搭建
CNN模型为三层卷积池化层+两层全连接层,抹平之后进行分类。中间加入Dropout层,防止过拟合。
部分代码:
def build_model(self):
self.model = keras.Sequential([
keras.layers.Conv2D(filters=32,kernel_size=(5,5),padding="same",activation="relu",input_shape=self.dataset.X_train.shape[1:]),
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
keras.layers.Conv2D(filters=64,kernel_size=(5,5),padding="same",activation="relu"),
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
keras.layers.Conv2D(filters=128,kernel_size=(5,5),padding="same",activation="relu"),
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
keras.layers.Dropout(0.5),
keras.layers.Flatten(),
keras.layers.Dense(512,activation="relu"),
keras.layers.Dense(self.dataset.num_classes,activation="softmax")
])
模型训练+测试
其中epochs和batch_size可以自己选择。
# 进行模型训练的函数,具体的optimizer、loss可以进行不同选择
def train_model(self):
self.model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics=['accuracy']
)
# epochs、batch_size为可调的参数,epochs为训练多少轮、batch_size为每次训练多少个样本
self.model.fit(self.dataset.X_train,self.dataset.Y_train,epochs=50,batch_size=90)
#用训练好的模型对测试集进行测试
def evaluate_model(self):
print('Testing---------------')
loss, accuracy = self.model.evaluate(self.dataset.X_test, self.dataset.Y_test)
print('test loss:',loss)
print('test accuracy:',accuracy)
训练结果如下所示:
(这准确率高的我自己都害怕
Epoch 50/50
90/2705 [..............................] - ETA: 1s - loss: 9.0821e-04 - accuracy: 1.0000
270/2705 [=>............................] - ETA: 1s - loss: 5.1787e-04 - accuracy: 1.0000
450/2705 [===>..........................] - ETA: 0s - loss: 0.0022 - accuracy: 0.9978
630/2705 [=====>........................] - ETA: 0s - loss: 0.0022 - accuracy: 0.9984
810/2705 [=======>......................] - ETA: 0s - loss: 0.0023 - accuracy: 0.9988
990/2705 [=========>....................] - ETA: 0s - loss: 0.0057 - accuracy: 0.9980
1170/2705 [===========>..................] - ETA: 0s - loss: 0.0055 - accuracy: 0.9983
1350/2705 [=============>................] - ETA: 0s - loss: 0.0049 - accuracy: 0.9985
1530/2705 [===============>..............] - ETA: 0s - loss: 0.0044 - accuracy: 0.9987
1710/2705 [=================>............] - ETA: 0s - loss: 0.0039 - accuracy: 0.9988
1890/2705 [===================>..........] - ETA: 0s - loss: 0.0036 - accuracy: 0.9989
2070/2705 [=====================>........] - ETA: 0s - loss: 0.0033 - accuracy: 0.9990
2250/2705 [=======================>......] - ETA: 0s - loss: 0.0031 - accuracy: 0.9991
2430/2705 [=========================>....] - ETA: 0s - loss: 0.0029 - accuracy: 0.9992
2610/2705 [===========================>..] - ETA: 0s - loss: 0.0027 - accuracy: 0.9992
2705/2705 [==============================] - 1s 443us/step - loss: 0.0026 - accuracy: 0.9993
测试集结果:
(摊手)
Testing---------------
32/677 [>.............................] - ETA: 4s
192/677 [=======>......................] - ETA: 0s
352/677 [==============>...............] - ETA: 0s
512/677 [=====================>........] - ETA: 0s
672/677 [============================>.] - ETA: 0s
677/677 [==============================] - 0s 668us/step
test loss: 0.00010534183920105803
test accuracy: 1.0
5.模型测试
对经过训练之后的模型进行测试,重新拍摄几张照片进行测试。
def test_onBatch(path):
model= Model()
model.load()
index = 0
img_list, label_lsit, counter = read_file(path)
for img in img_list:
picType,prob = model.predict(img)
if picType != -1:
index += 1
name_list = read_name_list('E:\\faceRecognition')
print(name_list[picType],prob)
else:
print(" Don't know this person")
return index
结果如下所示:
Model Loaded.
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
yqx_tst 1.0
6.调用摄像头识别
部分代码:
def build_camera(self):
# opencv文件中人脸级联文件的位置,用于帮助识别图像或者视频流中的人脸
face_cascade = cv2.CascadeClassifier('E:\ProgramData\Anaconda3\Lib\site-packages\cv2\data\haarcascade_frontalface_alt.xml')
#读取dataset数据集下的子文件夹名称
name_list = read_name_list("E:\\faceRecognition")
#打开摄像头并开始读取画面
cameraCapture = cv2.VideoCapture(0,cv2.CAP_DSHOW)
success,frame = cameraCapture.read()
while success and cv2.waitKey(1) == -1:
success,frame = cameraCapture.read()
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)#图像灰化
faces = face_cascade.detectMultiScale(gray,1.3,5)
for (x,y,w,h) in faces:
ROI = gray[x:x+w,y:y+h]
ROI = cv2.resize(ROI,(self.img_size,self.img_size),interpolation=cv2.INTER_LINEAR)
label,prob = self.model.predict(ROI)#利用模型对cv2识别出来的人脸进行对比
if prob > 0.9:
show_name = name_list[label]
else:
show_name = 'Stranger'
cv2.putText(frame,show_name,(x,y-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2)#显示名字
frame = cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)#在人脸区域画一个正方形出来
cv2.imshow("Camera",frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cameraCapture.release()
cv2.destroyAllWindows()
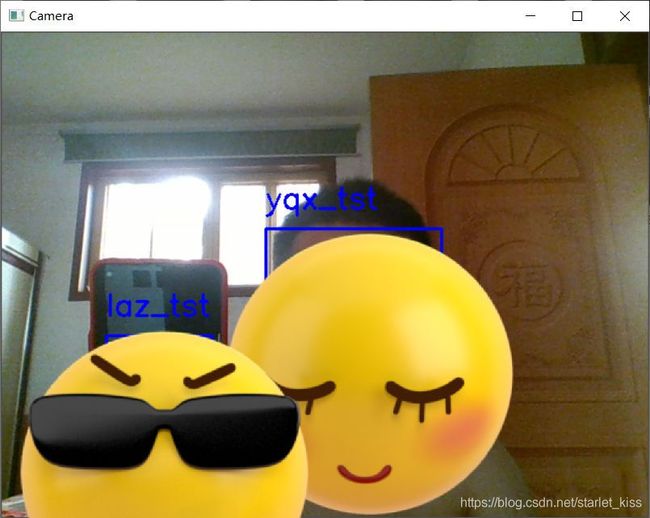
效果如下:


完整代码请私信我。有不对的地方希望路过的大佬批评指正。