基于MTCNN+FaceNet的人脸识别(附keras实现代码)
目录
-
- 前言
- 一、人脸识别技术相关概念
- 二、MTCNN算法
- 三、FaceNet
- 四、人脸识别试验
前言
最近想玩一玩人脸识别,于是就弄了弄呀,代码在最后一节。
一、人脸识别技术相关概念
1、人脸检测
检测出图像中人脸所在位置,输出就是框好人脸位置的图片

2、人脸配准
人脸配准算法的输入是“一张人脸图片”加“人脸坐标框”,输出五官关键点的坐标序列。五官关键点的数量是预先设定好的一个固定数值,可以根据不同的语义来定义(常见的有5点、68点、90点等等,通过关键点将五官轮廓框出)。

3、人脸对齐
由于原始图像中的人脸可能存在姿态、位置上的差异,为了之后的统一处理,我们要把人脸“摆正,常用双眼坐标进行旋正。

4、人脸属性识别
“人脸属性识别(Face Attribute)”是识别出人脸的性别、年龄、姿态、表情等属性值的一项技术。
输出是人脸相应的属性值。
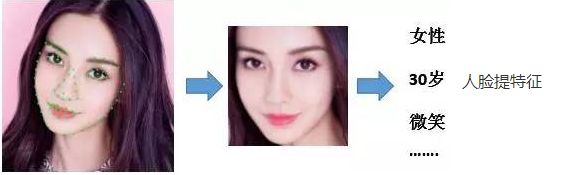
5、人脸特征提取
“人脸提特征(Face Feature Extraction)”是将一张人脸图像转化为一串固定长度的数值的过程。这个数值串被称为“人脸特征(Face Feature)”,具有表征这个人脸特点的能力,输出是人脸相应的一个数值串(特征),向量形式表示。
6、人脸比对(比对特征)
“人脸比对(Face Compare)”是衡量两个人脸之间相似度的算法,输出是两个特征之间的相似度。

7、人脸验证
“人脸验证(Face Verification)”是判定两个人脸图是否为同一人的算法。通过人脸比对获得两个人脸特征的相似度,通过与预设的阈值比较来验证这两个人脸特征是否属于同一人,相似度大于阈值就可判断为同一人。
8、人脸识别
人脸识别的输入一个人脸特征,通过和注册库中N个身份对应的特征进行逐个比对,找出“一个”与输入特征相似度最高的特征。将这个最高相似度值和预设的阈值相比较,如果大于阈值,则返回该特征对应的身份,否则返回“不在库中”。

9、人脸活体
“人脸活体(FaceLiveness)”是判断人脸图像是来自真人还是来自攻击假体(照片、视频等)的方法。
10、人脸跟踪
视频中跟踪人脸位置变化
二、MTCNN算法
MTCNN是一种基于深度学习的人脸检测和人脸对齐方法,它可以同时完成人脸检测和人脸对齐的任务,相比于传统的算法,它的性能更好,检测速度更快。
MTCNN算法包含三个子网络:Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net)
MTCNN检测分为四步:
1、构建图像金字塔
在进入三个子网络之前,首先将图像进行不同尺度的变换,构建图像金字塔,以适应不同大小的人脸的进行检测。构建方式是通过不同的缩放系数对图片进行缩放。
2、P-Net
P-Net的主要目的是为了生成一些候选框,通过一个全卷积网络进行初步特征提取与标定边框。

3、R-Net
P-Net的检测时比较粗略的,所以接下来使用R-Net进一步优化,即精修过程,在输入R-Net之前,都需要缩放到24×24×3。这一步的目的主要是为了去除大量效果较差的候选框。

4、O-Net
进一步将R-Net的所得到的区域缩放到48×48×3,因为O-Net需要(48, 48, 3)的shape,输入到最后的O-Net,O-Net的结构与P-Net类似,即进一步使候选框更准确,挑选出最准确的一个框显示,最终输出五个人脸面部的特征点。

注意:过程中Bounding-Box Regression和NMS也是过滤优化过程
总结:从P-Net到R-Net,再到最后的O-Net,网络输入的图像越来越大,卷积层的通道数越来越多,网络的深度也越来越深,因此识别人脸的准确率应该也是越来越高的。同时P-Net网络的运行速度越快,R-Net次之、O-Net运行速度最慢。之所以使用三个网络,是因为一开始如果直接对图像使用O-Net网络,速度会非常慢。实际上P-Net先做了一层过滤,将过滤后的结果再交给R-Net进行过滤,最后将过滤后的结果交给效果最好但是速度最慢的O-Net进行识别。这样在每一步都提前减少了需要判别的数量,有效地降低了计算的时间。
三、FaceNet
谷歌人脸识别算法,发表于 CVPR 2015,利用相同人脸在不同角度等姿态的照片下有高内聚性,不同人脸有低耦合性,在 LFW 数据集上准确度达到 99.63%,相当强大,也可见2015年人脸识别就已经走向成熟了,FaceNet使用的主干网络为Inception-ResNetV1,欲了解详见GoogLeNet v1-v4,FaceNet做的任务就是在检测到人脸位置并框出的基础上识别出是谁。
简单来讲,Facenet识别主要步骤如下:
1、输入一张人脸图片
2、通过深度学习网络提取特征
3、L2标准化
4、得到128维特征向量。
人脸识别实质上就是比较特征的相似度。这里就是在注册库中寻找是否有相似度大于阈值的图片,有就在识别中显示出名字,没有就写Unknown。
四、人脸识别试验
环境: Python3.6 + Anaconda + tensorflow1.14.0 + keras2.3.1
工具: PyCharm
链接:https://github.com/yx5411/face-recognition-keras
由于github只能上传25M以内文件,故facenet_keras.h5模型放在网盘中,链接如下:
链接:https://pan.baidu.com/s/12Yv3SL6ERJVBZOKwrA5LJw
提取码:qnay
1、将自己的照片并命名放入face_dataset文件夹,它相当于一个注册库,识别时在这个库里进行比对。
2、运行face_recognize.py,结果如下
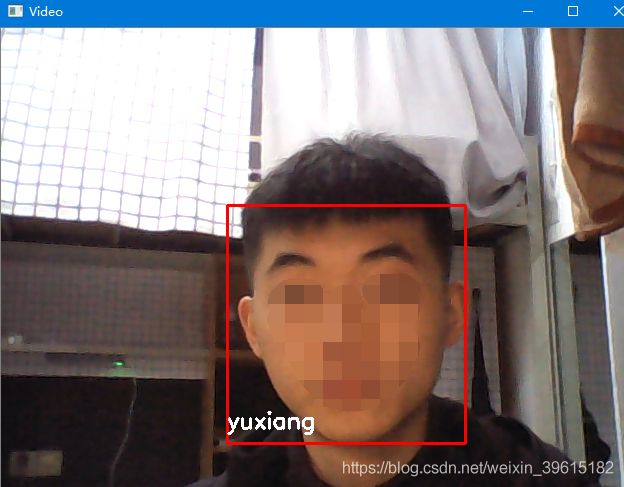
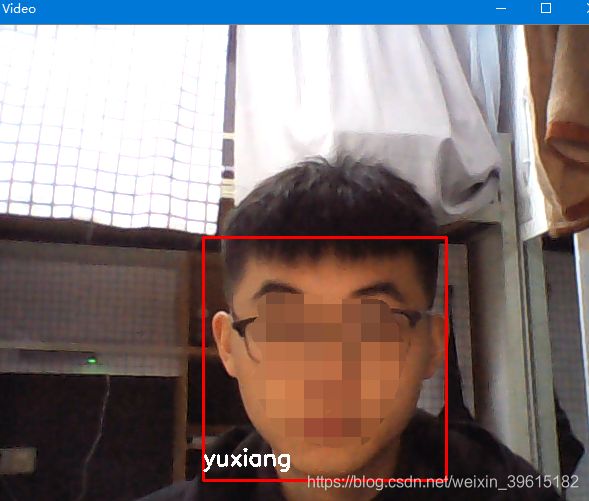
可见效果不错,戴眼镜与不带都能识别出来。
若运行时若报错遇到decode解码问题,解决办法如下:

参考文章:
https://blog.csdn.net/LIHUINIHAO/article/details/73866199?ops_request_misc=&request_id=&biz_id=102&utm_term=%25E4%25BA%25BA%25E8%2584%25B8%25E8%25AF%2586%25E5%2588%25AB&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-2-73866199.first_rank_v2_pc_rank_v29