基于 Java 机器学习自学笔记 (第51-53天:kNN)
注意:本篇为50天后的Java自学笔记扩充,内容不再是基础数据结构内容而是机器学习中的各种经典算法。这部分博客更侧重与笔记以方便自己的理解,自我知识的输出明显减少,若有错误欢迎指正!
目录
一、关于数据集及其导入
· 导入这些文档库的一些基本Java操作整理
二、KNN的特性
三、代码实现细节
1. 变量准备
2. 文件读入与构造随机数组
3. 数据分割
4. (核心代码)寻找K个邻居与投票
5. 预测的代码外壳以及准确度计算
四、数据测试
五、一些可能的想法和优化(5.3补改)
1.维护大小为k的堆的优化思路
2.维护大小为N的堆的优化思路(5.3日补)
· 第52天内容(补)
1.增加 setNumNeighors() 方法
2.重新实现 computeNearests
3.增加 setDistanceMeasure() 方法
· 第53天内容(补)
1.增加 weightedVoting() 方法
2.实现 leave-one-out 测试
一、关于数据集及其导入
这里我们引入了一个名为iris的数据集用于接下来的学习,iris本身是一类花的名字【鸢尾(学名:Iris tectorum Maxim. )又名:蓝蝴蝶、紫蝴蝶、扁竹花等】示例数据下载地址:
javasampledata: The sample data for Java programming https://gitee.com/fansmale/javasampledata 数据细节(一共150个数据):
https://gitee.com/fansmale/javasampledata 数据细节(一共150个数据):
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
...
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
...
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginica
7.6,3.0,6.6,2.1,Iris-virginica简单说明,这个数据其实相当于用文本描述了一个数据库“@ATTRIBUTE”声明为属性列,关系表的前四列为实数,最后一类是作为三种案例的枚举,若取得他们的值的话,返回的是1.0、2.0、3.0这样的数据。
| sepallength | sepalwidth | petallength | petalwidth | class |
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 5.5 | 2.3 | 4.0 | 1.3 | Iris-versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | Iris-virginica |
| 7.6 | 3.0 | 6.6 | 2.1 | Iris-virginica |
至于数据的含义嘛...是花一些细节参数,比如花瓣长度等等。最后的class属性说明了这个花属于iris花的哪个子类,而我们今天就是通过学习这150的部分数据得到“经验”,然后通过经验去判断接下来的部分数据从而判断这些数据属于哪一类iris花的子类。
· 导入这些文档库的一些基本Java操作整理
1.使用weka库,这里有针对文本数据库的一些导入操作
import weka.core.*;2.存储数据库的类:Instances类。后面在我们的代码就创建名为dataset这样的对象来存储。
/**
* The whole dataset.
*/
Instances dataset;3.Instances类常用方法(后期有新的使用会在这里继续更新)
dataset.numAttributes() // 返回关系表当中属性的个数(可以理解为有多少列,本案例有5个)
dataset.setClassIndex(column)
// 指明以哪个枚举性质属性列作为我们数据的类别
dataset.numClasses() // 返回关系表中类别数据能承载的枚举个数(注意: 需要先指定)(本案例有3个)
dataset.numInstances(); // 返回表的行数(本案例为150行,即有150个数据)
dataset.instance(i).value(j);
// 返回第i行j列的数据
dataset.instance(i).classValue();
// 返回第i行的类别数据(注意: 需要先指定)
dataset = new Instances(fileReader);
// 以文件指针的方式构造类二、KNN的特性
机器学习的本质其实就是——猜。所以往往机器学习之应用与不确定问题,确定问题(比如9+2=?)往往不用机器学习去做。而如何去猜,机器学习就逐渐分为各种门派和类别,这些类别各有自己的针对性和适用性。
KNN(K-Nearest Neighbor)是最简单的机器学习算法之一,同时适用性强,可以用于分类和回归,是一种监督学习算法。它的思路是这样,如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。也就是说,该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
可以发现KNN似乎没有学习过程,即惰性学习(lazy learning),但是KNN效果很好,对于很多数据,少有算法能超过KNN。KNN的适用性与可扩展都是比较强的,比如我们若能对数据预处理得很好的话,基于这个数据的度量再次使用KNN效果会很好。当然KNN也有一个麻烦的话——KNN往往需要对于数据进行归一化。
今天的代码是实现分类的功能,先学习130个花朵样本,然后到余下的20个样本中去试着分类。当然如果他的邻居不是完全一致类别,那么就投票选举可能性最高的类别。
三、代码实现细节
1. 变量准备
/**
* Manhattan distance.
*/
public static final int MANHATTAN = 0;
/**
* Euclidean distance.
*/
public static final int EUCLIDEAN = 1;
/**
* The distance measure.
*/
public int distanceMeasure = EUCLIDEAN;设定了两个常量的全局定义,以增加可读性,分辨用0/1表示度量数据之间距离的两个常用距离:曼哈顿距离与欧氏距离。然后我们的距离采用欧式距离。
/**
* A random instance;
*/
public static final Random random = new Random();
/**
* The number of neighbors.
*/
int numNeighbors = 7;
/**
* The whole dataset.
*/
Instances dataset;
/**
* The training set. Represented by the indices of the data.
*/
int[] trainingSet;
/**
* The testing set. Represented by the indices of the data.
*/
int[] testingSet;
/**
* The predictions.
*/
int[] predictions;
依次地,先声明随机数的对象(后面要使用随机数),定义取周围的7个邻居(这就是kNN里面的k),声明数据库对象dataset,然后trainingSet表示训练集,这里存储的是我们随机选取的dataset数据行的下标,testingSet也是相同的存储,只不过个数不同。这里请注意,我们存储的是对应数据行的下标,因此表示处理的数据
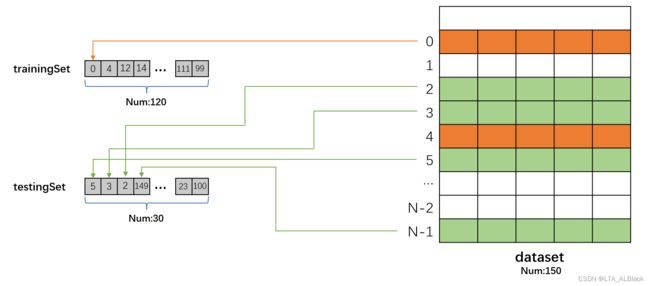
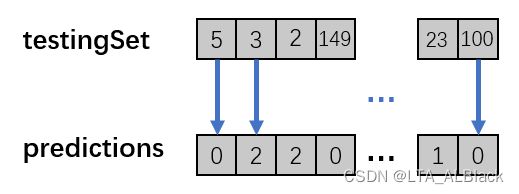
而预测数组就是对于每个测试集对应的数据行进行类别的预测,因为三类类别可简化存储为0、1、2,因此有如下预测映射:
2. 文件读入与构造随机数组
/**
*********************
* The first constructor.
*
* @param paraFilename
* The arff filename.
*********************
*/
public KnnClassification(String paraFilename) {
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
// The last attribute is the decision class.
dataset.setClassIndex(dataset.numAttributes() - 1);
fileReader.close();
} catch (Exception ee) {
System.out.println("Error occurred while trying to read \'" + paraFilename
+ "\' in KnnClassification constructor.\r\n" + ee);
System.exit(0);
} // Of try
}// Of the first constructor这个函数在外边调用的体现为:
KnnClassification tempClassifier = new KnnClassification("D:/Java DataSet/iris.arff");读入文件指针后,依次初始化了数据库对象,确定了类别属性所在的列,指针关闭。本方法可重用!
这里为什么要构造随机数组?后续分割dataset数据集的时候,测试集与训练集分得的dataset下标应该足够随机,因此需要采用随机数。但是为了避免测试与训练集分配的下标重复,故专门采用一个随机数组来实现。
/**
*********************
* Get a random indices for data randomization.
*
* @param paraLength
* The length of the sequence.
* @return An array of indices, e.g., {4, 3, 1, 5, 0, 2} with length 6.
*********************
*/
public static int[] getRandomIndices(int paraLength) {
int[] resultIndices = new int[paraLength];
// Step 1. Initialize.
for (int i = 0; i < paraLength; i++) {
resultIndices[i] = i;
} // Of for i
// Step 2. Randomly swap.
int tempFirst, tempSecond, tempValue;
for (int i = 0; i < paraLength; i++) {
// Generate two random indices.
tempFirst = random.nextInt(paraLength);
tempSecond = random.nextInt(paraLength);
// Swap.
tempValue = resultIndices[tempFirst];
resultIndices[tempFirst] = resultIndices[tempSecond];
resultIndices[tempSecond] = tempValue;
} // Of for i
return resultIndices;
}// Of getRandomIndices所谓的随机数组,就是对于\(N\)个元素的数组,分别随机存放0~\(N-1\)的全部数据。实际的代码实现就是先生成有序序列\(\{0,1,2,3,4,...,N-1\}\),然后任意挑选其中两个数据进行交换就好了。如果你说刚好随机的两个数相同,交换后等于没交换?那也无所谓,毕竟这样也是随机的情况。
3. 数据分割
/**
*********************
* Split the data into training and testing parts.
*
* @param paraTrainingFraction
* The fraction of the training set.
*********************
*/
public void splitTrainingTesting(double paraTrainingFraction) {
int tempSize = dataset.numInstances();
int[] tempIndices = getRandomIndices(tempSize);
int tempTrainingSize = (int) (tempSize * paraTrainingFraction);
trainingSet = new int[tempTrainingSize];
testingSet = new int[tempSize - tempTrainingSize];
for (int i = 0; i < tempTrainingSize; i++) {
trainingSet[i] = tempIndices[i];
} // Of for i
for (int i = 0; i < tempSize - tempTrainingSize; i++) {
testingSet[i] = tempIndices[tempTrainingSize + i];
} // Of for i
}// Of splitTrainingTesting函数参数paraTrainingFraction是一个比例,表示将总的数据tempSize(这里是150),的tempSize * paraTrainingFraction 的大小用于训练,而余下的大小用于测试。确定大小后,以这个大小将dataset一分为二,前半部分给训练集后半部分给测试集即可。
4. (核心代码)寻找K个邻居与投票
/**
************************************
* Compute the nearest k neighbors. Select one neighbor in each scan. In fact we
* can scan only once. You may implement it by yourself.
*
* @param paraCurrent
current instance. We are comparing it with all others.
* @return the indices of the nearest instances.
************************************
*/
public int[] computeNearests(int paraCurrent) {
int[] resultNearests = new int[numNeighbors];
boolean[] tempSelected = new boolean[trainingSet.length];
double tempDistance;
double tempMinimalDistance;
int tempMinimalIndex = 0;
// Select the nearest paraK indices.
for (int i = 0; i < numNeighbors; i++) {
tempMinimalDistance = Double.MAX_VALUE;
for (int j = 0; j < trainingSet.length; j++) {
if (tempSelected[j]) {
continue;
} // Of if
tempDistance = distance(paraCurrent, trainingSet[j]);
if (tempDistance < tempMinimalDistance) {
tempMinimalDistance = tempDistance;
tempMinimalIndex = j;
} // Of if
} // Of for j
resultNearests[i] = trainingSet[tempMinimalIndex];
tempSelected[tempMinimalIndex] = true;
} // Of for i
System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
}// Of computeNearests
这个距离计算是针对训集而言的,中心点的选择是基于测试集的。我们在测试集中依次确定一个中心节点,然后再于训练集中找到K个距离它最近的邻居,作为预测的标准。这里函数的paraCurrent参数已经是我们选定好的中心数据(物理含义为dataset的对应数据行的下标),然后设置tempSelected来标记已经选过的邻居,避免重复选择。可见computeNearests(5)的含义为判断dataset中第6行数据测试集中最近的前K个邻居的数据是哪些?请返回他们的下标数组。
computeNearests函数即确定下图的一束,paraCurrent就是上方选择的红点。
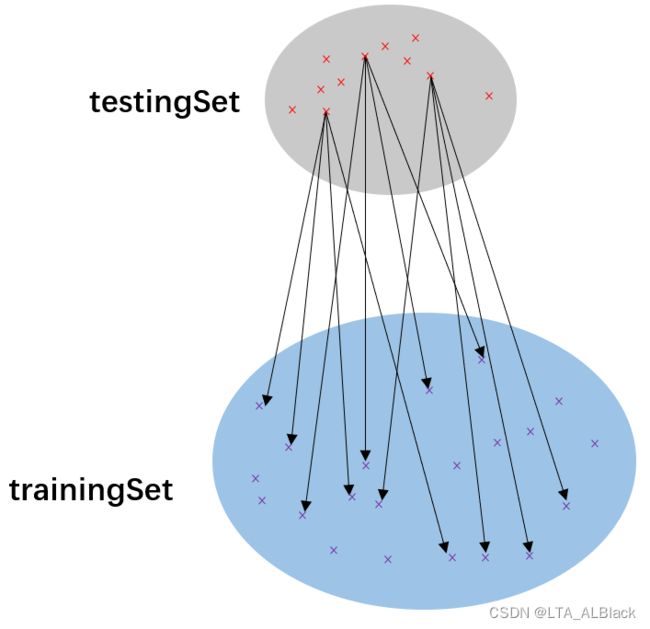
具体操作是通过一层for遍历趟数,每趟裁决一个最佳邻居,一共裁决\(k\)躺,每次裁决指标为判断\(N\)个数据当中的相互之间欧氏距离最短的点。上述操作可以非常容易得到复杂度为\(O(kN)\),这里\(k\)为邻居数而\(N\)为训练集长度。若我们的测试集有\(M\)个元素,那么总的复杂度为\(O(kNM)\)。
这里使用一个求欧式距离的函数tempDistance = distance(paraCurrent, trainingSet[j]);
具体实现如下:
public double distance(int paraI, int paraJ) {
double resultDistance = 0;
double tempDifference;
switch (distanceMeasure) {
case MANHATTAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
if (tempDifference < 0) {
resultDistance -= tempDifference;
} else {
resultDistance += tempDifference;
} // Of if
} // Of for i
break;
case EUCLIDEAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
resultDistance += tempDifference * tempDifference;
} // Of for i
break;
default:
System.out.println("Unsupported distance measure: " + distanceMeasure);
}// Of switch
return resultDistance;
}// Of distance这里分别给出了欧式距离与曼哈顿距离的求解方案,这几个距离方案倒是没什么说的,主要要注意的几点:
- 我们带入的参数是dataset的数据行下标,计算是要先通过下标依次取出当前行的每个元素,一共我们要取四个属性元素,所以这应当是四维向量的距离求解。
- 求欧式距离的时候没必要求开根号,因为我们没必要求得实值,只是用于彼此比较就好
求得邻居数组之后,我们要从邻居中选出一个认定指标,从而来决定我们对于测试集中的这个中心点所属分类的预测。
具体实现如下
/**
************************************
* Voting using the instances.
*
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
************************************
*/
public int simpleVoting(int[] paraNeighbors) {
int[] tempVotes = new int[dataset.numClasses()];
for (int i = 0; i < paraNeighbors.length; i++) {
tempVotes[(int) dataset.instance(paraNeighbors[i]).classValue()]++;
} // Of for i
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for (int i = 0; i < dataset.numClasses(); i++) {
if (tempVotes[i] > tempMaximalVoting) {
tempMaximalVoting = tempVotes[i];
tempMaximalVotingIndex = i;
} // Of if
} // Of for i
return tempMaximalVotingIndex;
}// Of simpleVoting
这个投票过程可以用下面这个图来表示:
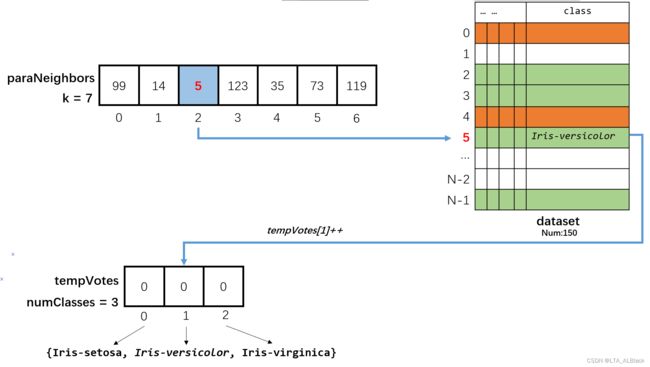
先得到我们选定的k个数据的邻居数组,然后依次取出邻居数组中的元素,这个元素代表了数据集中某个数据的下标。于是在数据集中找到这行数据,然后取出这行数据的类别项,这个数据项虽然我们在文本中和字面上表示是字符串,但是实际在存储器中的存储是浮点型{1.0, 2.0, 3.0},将其取出转换为整型后能唯一在长度为3(numClasses)的全0数组(tempVotes)中找到一个位置,使用桶排序的方法将其计数。
最终只要统计桶的项目数即可确定当前邻居告诉我们的最佳决策,假如最终:
- tempVotes[0] = 4
- tempVotes[1] = 1
- tempVotes[2] = 2
那么可以断定,这些邻居当中属于“Iris-setosa”类的最多,因此可以对于当前测试集中的中心数据进行预测:极有可能是属于“Iris-setosa”类。
5. 预测的代码外壳以及准确度计算
其实刚刚的内容已经说完了预测的核心操作了,下面就是通过一些基本操作将这些操作串联。单数据预测:
/**
*********************
* Predict for given instance.
*
* @return The prediction.
*********************
*/
public int predict(int paraIndex) {
int[] tempNeighbors = computeNearests(paraIndex);
int resultPrediction = simpleVoting(tempNeighbors);
return resultPrediction;
}// Of predict此预测函数存在单个参数,用于表示预测集的某个中心点,通过computeNearests函数计算出此中心点的邻居集合,之后通过simpleVoting函数在邻居中投票得到最佳的类别,并返回。这个单预测函数能以\(O(k*N)\)的复杂度预测出当前中心结点可能的类别,这就是一个比较完善的kNN的预测过程。
全测试集预测:
/**
*********************
* Predict for the whole testing set. The results are stored in predictions.
* #see predictions.
*********************
*/
public void predict() {
predictions = new int[testingSet.length];
for (int i = 0; i < predictions.length; i++) {
predictions[i] = predict(testingSet[i]);
} // Of for i
}// Of predict顾名思义,对于测试集的所有元素实施但数据预测。为了方便表示我们将其重载了。
下面是计算精确度的函数:
我们依次取出预测数组当中的所有预测类A,并且对应地找到每个测试集的元素在dataset中的位置,取出了原本自身已知的类B,若A类与B类一致,则预测合理。
/**
*********************
* Get the accuracy of the classifier.
*
* @return The accuracy.
*********************
*/
public double getAccuracy() {
// A double divides an int gets another double.
double tempCorrect = 0;
for (int i = 0; i < predictions.length; i++) {
if (predictions[i] == dataset.instance(testingSet[i]).classValue()) {
tempCorrect++;
} // Of if
} // Of for i
return tempCorrect / testingSet.length;
}// Of getAccuracy四、数据测试
主函数如下
/**
*********************
* The entrance of the program.
*
* @param args Not used now.
*********************
*/
public static void main(String args[]) {
KnnClassification tempClassifier = new KnnClassification("D:/Java DataSet/iris.arff");
tempClassifier.splitTrainingTesting(0.8);
tempClassifier.predict();
System.out.println("The accuracy of the classifier is: " + tempClassifier.getAccuracy());
}// Of main全过程非常清晰:
- 读数据
- 按照0.8分割dataset,80%用于训练,20%用于测试
- 基于80%的训练集,对20%的数据进行预测
- 输出预测结果
输出结果为

这里是一共30个测试时间的邻居数据演示,最终的准确率竟然高达100%。为了更准确,多次运行后还是有例如0.93、0.96等情况的出现,极少出现低于0.9的案例。
但是总的来看,预测效果出奇地准确!
五、一些可能的想法和优化(5.3补改)
其实纵观整个算法,有个非常强烈的感觉,我们大部分的计算都可以简化为三大循环体。首先,对于每个测试集进行遍历,分别确定一个中心点,对这个中心点进行预测。假设M为测试集长度,这个是复杂度显而易见是\(O(M)\)。然后对每个选择的中心点进行k次找邻居,这个复杂度是\(O(k)\)。每次找邻居有需要遍历全部的训练集,假设训练集长度为N,复杂度为\(O(N)\)。
所以复杂度是,\((O(kNM)\)。最开始我设想了堆优化。
1.维护大小为k的堆的优化思路
我们常常在找前\(k\)大的元素时会考虑堆优化,因此可以在对于一个中心点进行预测时,可以维护一个大小为\(k\)的堆。这样的话,每次遍历到一个训练集元素时,计算出训练集元素与中心点的权值,考虑这样的元素是否能入堆。这样可以改变代码结构,找邻居的时间消耗可以从\(O(kN)\)优化到\(O(Nlogk)\)。但是......\(k\)如果本来就很小,这种优化基本没什么意义啊,这种优化只在\(k\)值足够大时才有优化可能。
但kNN的\(k\)很大这件事情本身合理吗?我试着将\(k\)拔高之后再准确率测试。效果非常糟糕:
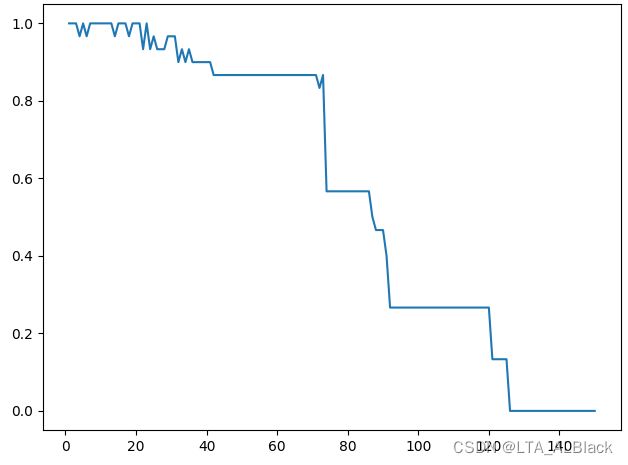
为了避免随机的干扰,我们再测试一遍:

可以发现随着k的增大,识别效果发生了非常明显的下降。为了查得原因,我查阅了一些文章(https://blog.csdn.net/qq_38330846/article/details/80207604),得到了如下结果:
对于KNN算法,\(k\)值越大,表示模型的学习能力越弱,因为\(k\)越大,它越倾向于从“面”上考虑做出判断,而不是具体地考虑一个样本,近身的情况来做出判断,所以,它的偏差会越来越大。
这样印证了这种堆优化是不可取的,因为本身\(k\)就不可能大,把\(O(k)\)变成\(O(logk)\)完全没有必要。
2.维护大小为N的堆的优化思路(5.3日补)
在同学(@颜妮儿)的点醒下,突然意识到建堆的建堆的复杂度其实是\(O(N)\),而不是\(O(NlogN)\)!虽然初始化每次入堆都是\(O(logN)\),但是这个\(N\)会随着堆高度的变化而变化,因此虽然单次入堆我们常常说是\(O(logN)\),但是套上\(N\)次循环后加权下来的\(O(NlogN)\)里面的两个\(N\)截然不同,通过证明建堆的复杂度是稳定在\(O(N)\)的。
证明可见此文章:建堆的时间复杂度分析_Black.Spider的博客
得亏我前几天才写了堆排序啊!!
这样的话,对单个测试集的中心结点测试的复杂度可以从\(O(kN)\)优化为\(O(klogN + N)\)。总复杂度为\(O(M(klogN + N))\)。
优化代码:(我还是自建了个Pair类,因为先版本Java删了这个库,我也懒得找了原本的库了。此外,针对优先队列的比较声明了个比较器)
// Create Comparator in order to make the priority queue knows which value as
// the comparing values
static Comparator> cmp = new Comparator>() {
public int compare(Pair e1, Pair e2) {
if (e1.getKey() > e2.getKey()) {
return 1;
} else if (e1.getKey() < e2.getKey()) {
return -1;
} else {
return 0;
} // Of if
}
};
/**
************************************
* Compute the nearest k neighbors. Select one neighbor in each scan. In fact we
* can scan only once. You may implement it by yourself.
*
* @param paraCurrent current instance. We are comparing it with all others.
* @return the indices of the nearest instances.
************************************
*/
public int[] computeNearestsForHeap(int paraCurrent) {
int[] resultNearests = new int[numNeighbors];
PriorityQueue> queue = new PriorityQueue<>(cmp);
double tempDistance;
// Create a Heap
for (int j = 0; j < trainingSet.length; j++) {
tempDistance = distance(paraCurrent, trainingSet[j]);
queue.add(new Pair<>(tempDistance, trainingSet[j]));
} // Of for j
// Select the nearest paraK indices.
for (int i = 0; i < numNeighbors; i++) {
int indexNeighbors = queue.poll().getValue();
resultNearests[i] = indexNeighbors;
} // Of for i
System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
}// Of computeNearests 优化效果明显吗?我感觉是还行的
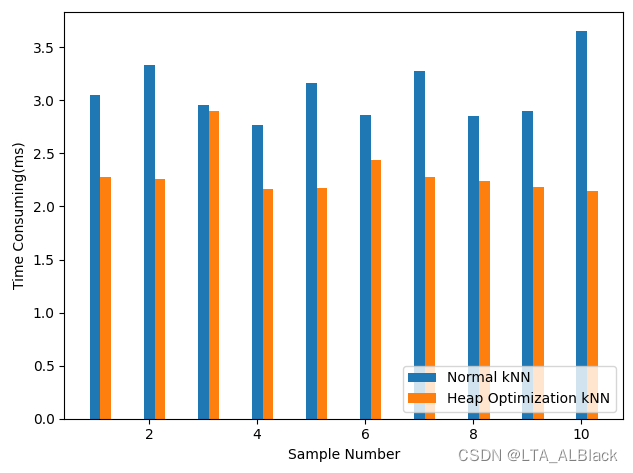
至少来说堆优化的时间确实有减少,某些案例的时间削减甚至超过了30%。另外也许是我的案例太少了,如果案例多了也许效果又会截然不同。
· 第52天内容(补)
1.增加 setNumNeighors() 方法
方便直接设置邻居个数
/**
************************************
* Set numNeighbors.
*
* @param setNumNeighors
The num of Neighbors.
************************************
*/
public void setNumNeighors(int paraNeighbors) {
numNeighbors = paraNeighbors;
return;
}// Of setNumNeighors2.重新实现 computeNearests
见上述第五部分的堆优化
3.增加 setDistanceMeasure() 方法
方便直接设置距离方法
/**
*********************
* Set the distance measure
*
* @param paraDistanceMeasure
* The class of distance measure
* 0 symbolize MANHATTAN
* 1 symbolize EUCLIDEAN
*********************
*/
public void setDistanceMeasure(int paraDistanceMeasure) {
distanceMeasure = paraDistanceMeasure;
return;
}// Of setDistanceMeasure· 第53天内容(补)
1.增加 weightedVoting() 方法
简单来说改变了投票的方案,从原来的选择邻居中最多的一类变为选择最近的一类。
/**
*********************
* Voting the closest neighbor.
*
* @param paraCurrent current instance. We are comparing it with all others.
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
*********************
*/
public int weightedVoting(int paraCurrent, int[] paraNeighbors) {
int tempMinIndex = -1;
double tempMinValue = Double.MAX_VALUE;
double tempDistance;
for (int i = 0; i < paraNeighbors.length; i++) {
tempDistance = distance(paraCurrent, paraNeighbors[i]);
if (tempDistance < tempMinValue) {
tempMinIndex = i;
tempMinValue = tempDistance;
} // Of if
} // Of for i
return (int) dataset.instance(paraNeighbors[tempMinIndex]).classValue();
}// Of weightedVoting2.实现 leave-one-out 测试
所谓的leave-one-out的含义,我在54天的M-distance里面再做笔记吧。今天先展示下kNN的leave-one-out实现代码:
这部分代码我删了一些随机数生成以及分割数据集的代码,把分割数据集的代码改成了给训练集赋值的代码(训练集的值就是数据集的全部)。同时删除了测试集数组,毕竟每次我们只需选择一个数据来面向全体训练集测试。
package machinelearning.knn;
import java.io.FileReader;
import java.util.Arrays;
import weka.core.*;
/**
* kNN classification for leave-one-out measure to test.
*
* @author Xingyi Zhang [email protected]
*/
public class knnClassificationForLeaveOneOut {
/**
* Manhattan distance.
*/
public static final int MANHATTAN = 0;
/**
* Euclidean distance.
*/
public static final int EUCLIDEAN = 1;
/**
* The distance measure.
*/
public int distanceMeasure = EUCLIDEAN;
/**
* The number of neighbors.
*/
int numNeighbors = 7;
/**
* The whole dataset.
*/
Instances dataset;
/**
* The training set. Represented by the indices of the data.
*/
int[] trainingSet;
/**
* The predictions.
*/
int[] predictions;
/**
*********************
* The first constructor.
*
* @param paraFilename The arff filename.
*********************
*/
public knnClassificationForLeaveOneOut(String paraFilename) {
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
// The last attribute is the decision class.
dataset.setClassIndex(dataset.numAttributes() - 1);
fileReader.close();
} catch (Exception ee) {
System.out.println("Error occurred while trying to read \'" + paraFilename
+ "\' in KnnClassification constructor.\r\n" + ee);
System.exit(0);
} // Of try
}// Of the first constructor
/**
*********************
* Obtain trainingSet from dataset.
*********************
*/
public void setTrainingSet() {
int tempSize = dataset.numInstances();
trainingSet = new int[tempSize];
for (int i = 0; i < tempSize; i++) {
trainingSet[i] = i;
} // Of for i
}// Of setTrainingSet
/**
*********************
* Predict for the whole testing set. The results are stored in predictions.
* #see predictions.
*********************
*/
public void predict() {
predictions = new int[dataset.numInstances()];
for (int i = 0; i < dataset.numInstances(); i++) {
System.out.print("Try to predict " + i + " row of data: ");
predictions[i] = predict(i);
System.out.println("Prediction class is " + predictions[i]);
} // Of for i
}// Of predict
/**
*********************
* Predict for given instance.
*
* @return The prediction.
*********************
*/
public int predict(int paraIndex) {
int[] tempNeighbors = computeNearests(paraIndex);
int resultPrediction = simpleVoting(tempNeighbors);
return resultPrediction;
}// Of predict
/**
*********************
* The distance between two instances.
*
* @param paraI The index of the first instance.
* @param paraJ The index of the second instance.
* @return The distance.
*********************
*/
public double distance(int paraI, int paraJ) {
double resultDistance = 0;
double tempDifference;
switch (distanceMeasure) {
case MANHATTAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
if (tempDifference < 0) {
resultDistance -= tempDifference;
} else {
resultDistance += tempDifference;
} // Of if
} // Of for i
break;
case EUCLIDEAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
resultDistance += tempDifference * tempDifference;
} // Of for i
break;
default:
System.out.println("Unsupported distance measure: " + distanceMeasure);
}// Of switch
return resultDistance;
}// Of distance
/**
*********************
* Get the accuracy of the classifier.
*
* @return The accuracy.
*********************
*/
public double getAccuracy() {
// A double divides an int gets another double.
double tempCorrect = 0;
for (int i = 0; i < predictions.length; i++) {
if (predictions[i] == dataset.instance(i).classValue()) {
tempCorrect++;
} // Of if
} // Of for i
return tempCorrect / predictions.length;
}// Of getAccuracy
/**
************************************
* Compute the nearest k neighbors. Select one neighbor in each scan. In fact we
* can scan only once. You may implement it by yourself.
*
* @param paraCurrent current instance. We are comparing it with all others.
* @return the indices of the nearest instances.
************************************
*/
public int[] computeNearests(int paraCurrent) {
int[] resultNearests = new int[numNeighbors];
boolean[] tempSelected = new boolean[trainingSet.length];
double tempMinimalDistance;
int tempMinimalIndex = 0;
tempSelected[paraCurrent] = true;
// Compute all distances to avoid redundant computation.
double[] tempDistances = new double[trainingSet.length];
for (int i = 0; i < trainingSet.length; i++) {
tempDistances[i] = distance(paraCurrent, trainingSet[i]);
} // Of for i
// Select the nearest paraK indices.
for (int i = 0; i < numNeighbors; i++) {
tempMinimalDistance = Double.MAX_VALUE;
for (int j = 0; j < trainingSet.length; j++) {
if (tempSelected[j]) {
continue;
} // Of if
if (tempDistances[j] < tempMinimalDistance) {
tempMinimalDistance = tempDistances[j];
tempMinimalIndex = j;
} // Of if
} // Of for j
resultNearests[i] = trainingSet[tempMinimalIndex];
tempSelected[tempMinimalIndex] = true;
} // Of for i
// System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
}// Of computeNearests
/**
************************************
* Voting using the instances.
*
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
************************************
*/
public int simpleVoting(int[] paraNeighbors) {
int[] tempVotes = new int[dataset.numClasses()];
for (int i = 0; i < paraNeighbors.length; i++) {
tempVotes[(int) dataset.instance(paraNeighbors[i]).classValue()]++;
} // Of for i
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for (int i = 0; i < dataset.numClasses(); i++) {
if (tempVotes[i] > tempMaximalVoting) {
tempMaximalVoting = tempVotes[i];
tempMaximalVotingIndex = i;
} // Of if
} // Of for i
return tempMaximalVotingIndex;
}// Of simpleVoting
/**
************************************
* Set numNeighbors.
*
* @param setNumNeighors The num of Neighbors.
************************************
*/
public void setNumNeighors(int paraNeighbors) {
numNeighbors = paraNeighbors;
return;
}// Of setNumNeighors
/**
*********************
* Set the distance measure
*
* @param paraDistanceMeasure The class of distance measure 0 symbolize
* MANHATTAN 1 symbolize EUCLIDEAN
*********************
*/
public void setDistanceMeasure(int paraDistanceMeasure) {
distanceMeasure = paraDistanceMeasure;
return;
}// Of setDistanceMeasure
/**
*********************
* Voting the closest neighbor.
*
* @param paraCurrent current instance. We are comparing it with all others.
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
*********************
*/
public int weightedVoting(int paraCurrent, int[] paraNeighbors) {
int tempMinIndex = -1;
double tempMinValue = Double.MAX_VALUE;
double tempDistance;
for (int i = 0; i < paraNeighbors.length; i++) {
tempDistance = distance(paraCurrent, paraNeighbors[i]);
if (tempDistance < tempMinValue) {
tempMinIndex = i;
tempMinValue = tempDistance;
} // Of if
} // Of for i
return (int) dataset.instance(paraNeighbors[tempMinIndex]).classValue();
}// Of weightedVoting
/**
*********************
* The entrance of the program.
*
* @param args Not used now.
*********************
*/
public static void main(String args[]) {
knnClassificationForLeaveOneOut tempClassifier = new knnClassificationForLeaveOneOut(
"D:/Java DataSet/iris.arff");
tempClassifier.setTrainingSet();
tempClassifier.predict();
System.out.println("The accuracy of the classifier is: " + tempClassifier.getAccuracy());
}// Of main
}// Of class KnnClassification
输出演示:
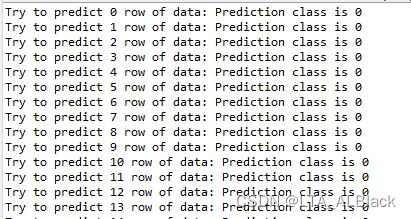
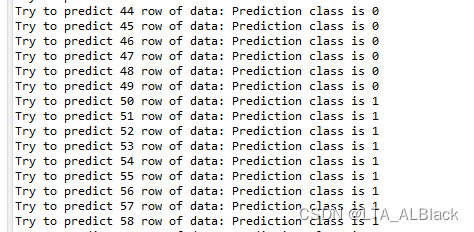

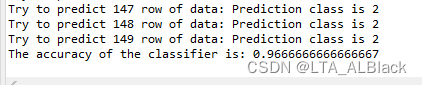
因为不再随机性的分割训练集与测试集,总的识别率稳定在 96.67%,上述的图中大部分的测试样例的类别是正确的(基本呈现0、1、2的递增,除开个别数据有些不老实地误判)
这个识别率相比原kNN的测试方案的部分案例要高,但是因为原kNN的测试样例是随机,存在某些时候,若数据选择适当后,识别率还是会高于leave-one-out的情况,但是显然,leave-one-out更公平。
此测试案例的复杂度显然为\(O(kN^2)\),当然依旧可以同理地堆优化,同时因为循环存在重叠,因此还可以采用哈希表来存储冗余数据避免计算,这里就不再给出代码了。