这里jira.csv是个大文件

1)
>>> import pandas
>>> jir=pandas.read_csv(r'C:\Temp\jira.csv')
>>> jir

2)查询前5行数据
>>>jir.head()

3)查看指定的列["column"],[:10]前10行,

4)获取指定类的前n位字符串

5)对某列求和,或者分组求和
![]()

6)查最后5行

7)读部分列

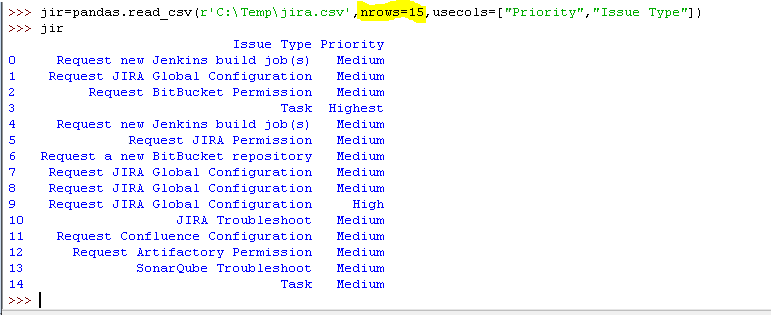
8)参数限定读某几行
9)分块读
read_csv()方法中还有一个参数,chunksize可以指定一个CHUNKSIZE分块大小来读取文件。与直接使用DF进行遍历不同的是,查看报道的它英文的一个TextFileReader类型的对象。

10)pandas实现数据透视表
我将另起一遍新博客来学习这个功能