广告行业中那些趣事系列20:GPT、GPT-2到GPT-3,你想要的这里都有
导读:本文是“数据拾光者”专栏的第二十篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本文主要分享本篇主要介绍了GPT系列模型,主要包括GPT、GPT-2和GPT-3。对GPT系列模型感兴趣的小伙伴可以一起沟通交流。欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。知乎专栏:数据拾光者
公众号:数据拾光者

摘要:本文是广告系列第二十篇,主要介绍了GPT系列模型的发展流程。首先介绍了NLP中超强但不秀的GPT模型。GPT属于典型的预训练+微调的两阶段模型,将Transformer作为特征抽取器,使用单向语言模型,属于NLP中非常重要的工作,同时还介绍了GPT模型下游如何改造成不同的NLP任务;然后介绍了有点火的GPT-2。相比于GPT来说GPT-2使用了更多更好的训练数据,同时直接使用无监督的方式来完成下游任务;最后介绍了巨无霸GPT-3。相比于GPT-2,GPT-3直接把模型的规模做到极致,使用了45TB的训练数据,拥有175B的参数量,真正诠释了暴力出奇迹。GPT-3模型直接不需要微调了,不使用样本或者仅使用极少量的样本就可以完成下游NLP任务,尤其在很多数据集中模型的效果直接超越了最好效果的微调模型,真正帮助我们解决了下游任务需要标注语料的问题。对GPT系列模型感兴趣的小伙伴可以一起沟通交流。
下面主要按照如下思维导图进行学习分享:

01 NLP中超强但不秀的GPT模型
1.1 从Word2vec到GPT
GPT(“Generative Pre-Training”)也叫生成式预训练模型,之所以说它超强但不秀的原因是作为NLP中极有价值的工作,比BERT出现的早,但是名声却远远不如BERT那么响亮。这里顺便提一下NLP领域从Word2vec模型到GPT和BERT模型的推进流程帮小伙伴们更加深入的理解这个问题。下面是Word2vec、ELMO、GPT和BERT之间的关系图:
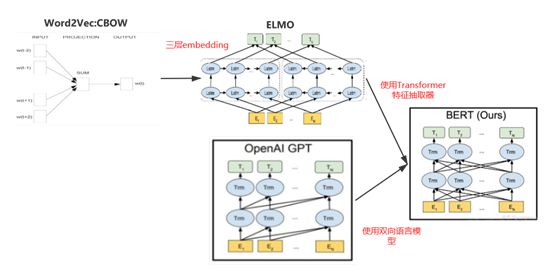
NLP领域首先要解决的是文本的表示问题。对于计算机来说它并不认识各种稀奇古怪的字符,它只认识0和1,通过One-hot编码我们可以将word转化成01串。但是One-hot编码存在高维稀疏的问题,所以我们将这些01串映射到低维向量空间中,这就是word embedding向量。而Word2vec就是将word映射到向量空间中的标志性模型。
Word2vec将word映射到向量空间中,并且可以根据两个向量的距离长短来表示语义的相似度。但是Word2vec模型存在一个问题,一个word在不同的语句中可能表达不同的语义,但是在Word2vec的向量空间中只有唯一的一个点,所以存在词的歧义性问题。针对这个问题,ELMO模型通过构建双向LSTM网络来获取词编码、句法编码和句义编码三层embedding来动态的表示词的语义,从而很好的解决了词的歧义性问题;接着我们本篇的主角GPT模型就出来了。GPT模型使用Transformer作为特征抽取器,同时使用单向语言模型在NLP各种任务中刷榜成功。相比于ELMO模型来说GPT使用效果更好的Transformer来替代LSTM作为特征抽取器。但是没高兴多久,BERT就出来了。BERT不仅使用Transformer作为特征抽取器,而且使用双向语言模型,刷新了NLP中各种任务的最好效果,很快抢了GPT的风头。可以说BERT和GPT模型最大的区别就是使用了双向语言模型,而BERT论文中的有效因子实验也证明正是使用了双向语言模型才带来的模型效果大量的提升。

1.2 深入理解GPT
虽说GPT的风头被BERT抢了,但是不得不承认GPT是非常重要的NLP工作。要深入理解GPT模型,我们从以下几个方面详细分析:
(1) GPT两阶段模型
GPT是典型的预训练+微调的两阶段模型。预训练阶段就是用海量的文本数据通过无监督学习的方式来获取语言学知识,而微调就是用下游任务的训练数据来获得特定任务的模型。之前举过一个例子来形容预训练和微调的关系,我们从幼儿园到高中就像预训练过程,不断学习知识,这些知识包罗万象包括语数英物化生等等,最重要的特征就是预训练模型具有很好的通用性;然后读大学的时候需要确定一个专业方向作为未来的职业,所以就会去重点学习专业知识,从而让我们成为更加适合某个专业方向的人才,最重要的特征就是具有极强的专业性。通过这个例子大家可以理解预训练模型和微调两阶段的差异和联系。
(2) GTP预训练模型结构
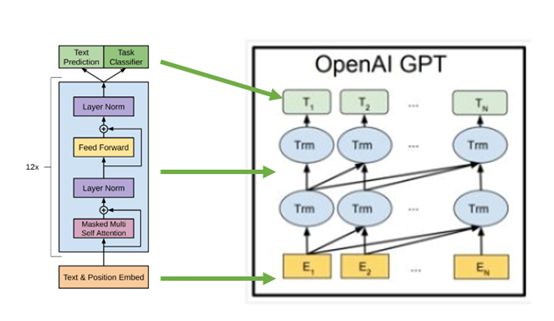
GPT预训练模型结构主要有两个重要的点:一个是使用Transformer作为特征抽取器,另一个是使用单向的语言模型。上面也说了GPT相比于ELMO模型效果更好的原因就是Transformer的特征抽取能力远远强于LSTM,这是非常明智的。后续NLP领域各种亮眼的模型基本上都是使用的Transformer架构,所以说率先将Transformer引入的GPT是非常重要的工作,这也是说它为啥强的原因。想了解更多关于Transformer的细节,小伙伴们可以看看我之前写过的一篇文章:
广告行业中那些趣事系列4:详解从配角到C位出道的Transformer
还有一点就是GPT使用单向语言模型。GPT在预训练的过程中仅仅使用语句中的上文。这里通过一个例子说明上下文的概念。我们现在有一句话:“GPT是预训<>和微调的两阶段模型”。现在我们语言模型的目的是预测“预训”后面跟着的词,那么<>之前的“GPT是预训”就代表上文,而<>之后的“和微调的两阶段模型”就代表下文。GPT使用单向语言模型和BERT使用双向语言模型是它俩最大的区别。这里小提一句,GPT后续系列依然坚持使用单向语言模型。下面是GPT预训练模型的网络结构图:
(3) GPT模型下游改造
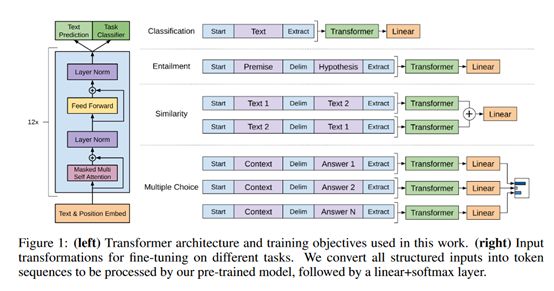
上面得到GPT预训练模型之后,就可以根据下游任务进行改造和微调了。对于文本分类任务基本不需要怎么变动,只需要添加一个开始符号Start和终止符号Extract就可以了;对于语句包含类任务,需要在前提premise和假设hypothesis中间添加一个连接符号Delim就可以了;对于语句相似关系类任务,需要将句子1和句子2分别调整位置然后添加连接符号Delim拼接就可以了;对于多路问答类任务分别将问题Context和多个答案Answer分别进行拼接作为输入。GPT下游改造如下图所示:
(4) GPT模型效果
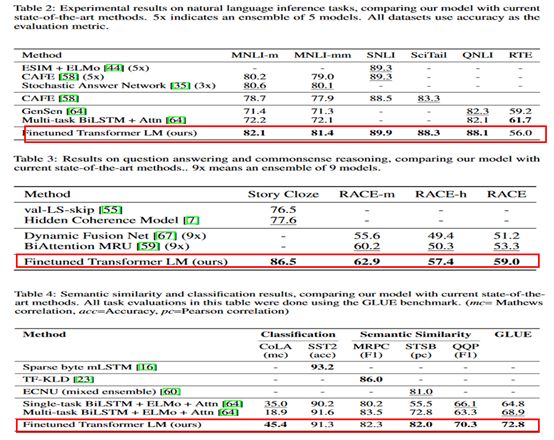
GPT模型效果还是非常出色的,12个任务数据集中9个达到了最好效果。下面是GPT论文中模型效果实验图:
02 有点火的GPT-2
2.1 GPT-2预训练模型的变化
相比于GPT来说,GPT-2模型的整体结构没有发生太大的变化。预训练过程使用了更多更好的数据进行训练,同时使用了更大更多参数的Transformer。首先是Transformer模型参数扩容。通常的Transformer Big包含24个Block,GPT-2直接使用了48个Block,从而可以保存更多的语言学知识;模型扩容之后就是使用更多更好的数据进行预训练。GPT使用大约5GB文本数据进行预训练,GTP-2直接使用40GB的文本数据进行预训练。GPT-2使用800W互联网网页数据WebText数据集进行预训练。这些数据因为覆盖主题广,所以训练出的模型具有更好的通用性。GPT-2不仅使用了更多的训练数据,而且对数据的质量也进行了筛选,过滤出更高质量的网页内容。
GPT-2还是坚持使用单向语言模型。虽然BERT模型已经证明了效果好的主要原因是使用了双向语言模型,但是GPT-2依然坚持自我使用单向语言模型。这里猜测可能是以下两个原因:其中一个原因是GPT是生成式模型,因为在生成式相关任务场景下一般只能看到上文,所以这种单向语言模型和实际应用场景是对应的。如果使用了下文,那么存在“提前偷看答案”的嫌疑;另一个原因是GPT和BERT模型最大的区别是使用单向语言模型,如果现在换成了双向语言模型,那么GPT模型是否还有存在和发展的必要?这是个人的一点猜测,仁者见仁智者见智。
2.2 GPT-2下游任务的变化
GPT-2没有采用GPT和BERT这种常规的预训练+微调的两阶段模型,而是直接通过无监督的方式去完成下游任务。GPT-2采用这种方式的原因很简单,它想证明预训练使用了更多更好的数据得到的模型可以直接用于下游任务了。现在的问题是GPT-2使用无监督样本做下游任务时如何识别不同的任务类型。GPT-2对于不同类型的任务输入会加入一些引导字符来告诉模型如何正确预测目标。举例来说,假如是文本摘要类任务,那么GPT-2在输入的时候加“TL:DR”作为引导字符告诉模型这是文本摘要类任务。而模型的输出和语言模型是一样的,就是每轮输出一个词。当我们需要模型输出的结果是一句话或者几句话的时候,只需要将每轮输出的词连接起来就是我们想要的结果。GPT-2将所有NLP任务的输出转换成了和语言模型一样的方式,每轮只输出一个词。
2.3 GPT-2的模型效果
GPT-2作为生成式模型来生成文本或者段落的能力是惊人的。通过下面的示例,我们先给出几句话,后面的内容让GPT-2来完成。可以看出,GPT-2生成的内容语法工整,语义一致,效果非常好。下面是GPT-2生成文本的例子:
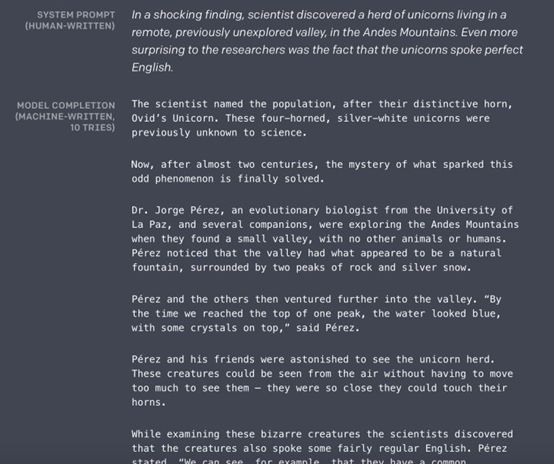
小结下,GPT-2相比于GPT来说模型整体的架构基本没有什么变化,还是使用Transformer作为特征抽取器,还是坚持单向语言模型,不同的是使用了更大的模型更多的参数从而能够存储更多的语言学知识,然后使用更多更好的数据去训练模型。对于下游任务直接使用无监督数据去完成任务,主要思想是因为我的预训练模型足够好,所以下游不需要有监督的数据去微调模型了。虽然相比于无监督模型效果好很多,但是相比于有监督模型效果还是差了点。GPT-2模型强有力的证明了使用更大的模型更多的数据是可以有效提升模型的效果。
03 巨无霸GPT-3
3.1 更大的模型,更多的训练数据
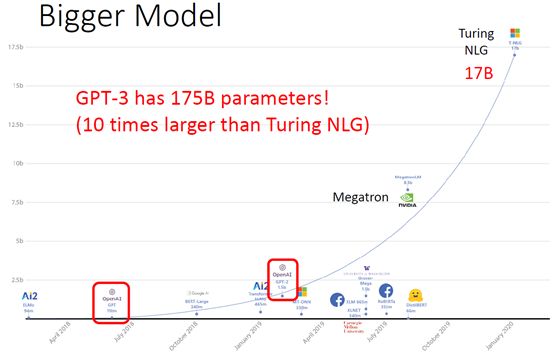
最近一段时间GPT-3强力出击,直接引爆NLP领域。如果说GPT-2模型已经足够大了,那么GPT-3已经可以说是爆炸了。先从参数角度看看GPT-3到底有多大。最早的ELMO模型有94M,然后2018年7月GPT出世,模型参数有110M,接着BERT-Large有340M;后来GPT-2出世已经把参数弄到1.5b了;再后来随着Turing NLG的出现直接将参数提升到17b,成为当时最大的模型;最后GPT-3出现了,直接将参数增加到175b,参数量基本上是第二名Turing NLG的十倍。通过这些现象咱们可以看出把模型做大似乎已经成为NLP领域的趋势。有时候费尽心思开发和优化模型,各种花里胡哨的骚操作下来结果发现最后的效果还不如最简单的用更大的模型更多的数据来的有效,这也是为啥那么多人不断去优化预训练模型的原因。下面是NLP领域各种模型参数量对比图:
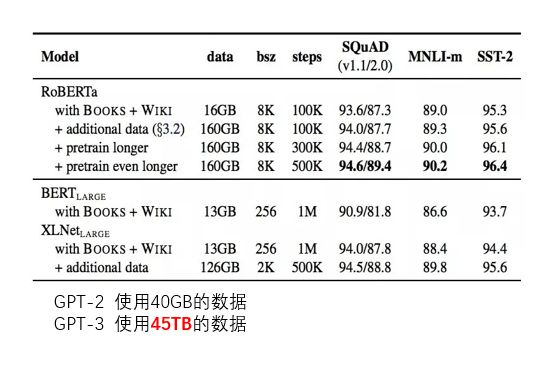
接下来咱们从使用训练数据的角度来看GPT-3到底有多大。BERT-Large使用了13G的数据,GPT-2使用了40G的数据,XLNet-Large使用了接近140G数据,之前说过RoBERTa模型能有很好的效果提升其中的一个重要原因是使用了将近176G的数据。这些在GPT-3面前就像小儿科一样,因为GPT-3直接使用了45TB的数据来预训练。下面是NLP领域各种模型使用数据量级对比图:
GPT-3使用如此多的训练数据,模型训练过程中的计算量也是惊人的。下面是BERT系列、T5系列和GPT-3系列模型的计算量对比图:
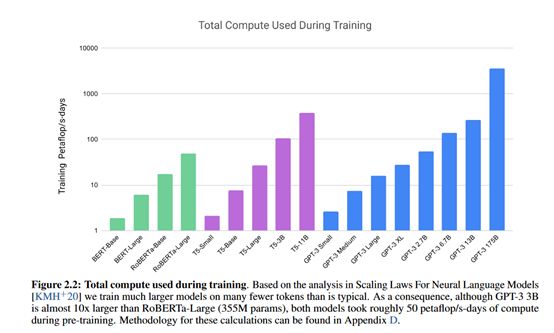
因为模型包含更多的参数使用更多的数据,所以模型需要的计算量也不断增大。可以说NLP后续是有钱有算力的天下,因为这样的计算量普通公司基本已经“跑”不动了。
3.2 告别微调的GPT-3
因为GPT-3使用了天量级的数据来进行预训练,所以学到的知识也更多更通用,以致于GPT-3打出的口号就是“告别微调的GPT-3”。相比于BERT这种预训练+微调的两阶段模型,GPT-3的目标是模型更加通用,从而解决BERT这种下游任务微调需要依赖领域标注数据的情况。拿我们实际业务举例,我主要做分本分类任务。对于使用BERT来完成文本分类任务来说,首先我需要使用海量的无标注文本数据进行预训练学习语言学知识。幸运的是这种预训练过程一般是一次性的,训练完成后可以把模型保存下来继续使用。很多大厂比如谷歌、Facebook等把得到的预训练模型开源了出来,所以咱们只需要导入预训练好的模型权重就可以直接使用了,相当于完成了模型的预训练过程;第二阶段就是微调了,对于文本分类等下游任务来说, 我们需要一批带标签的训练语料来微调模型。不同的下游任务会需要特定的训练语料。这时候面临的一个最大的问题是训练语料是需要人工标注的,而标注的成本是非常高的。除此之外不同的标注人员因为经验阅历等不同导致对同一条文本的理解也不同,所以容易出现标注不一致的问题。当标注数据量较少时还容易出现模型过拟合。归根结底就是微调是需要标注数据的,而获取标注数据的成本是很高的。为了解决这个问题,GPT-3可以让NLPer不用标注训练语料就能很好的完成下游任务,让GPT-3更通用更便利。GPT-3不需要进行微调的结构图如下所示:
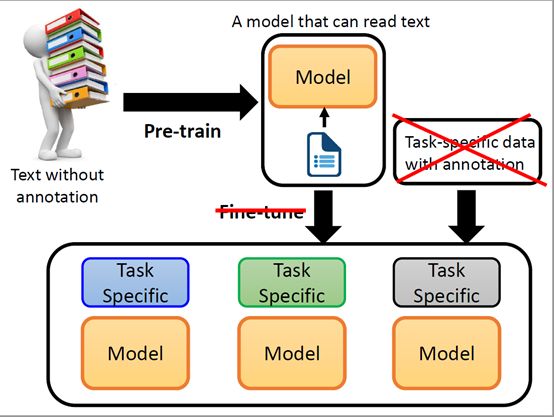
下面我们模拟人类来完成NLP下游任务。如果我们现在的任务是单向选择题,只需要提供任务说明和简单的任务举例,我们就可以理解任务,并且可以进行后面的答题预测了。同样如果我们的任务是阅读理解,我们也可以根据任务说明和任务举例快速的理解任务并且进行下面的答题和预测。人类完成NLP整个流程如下图所示:

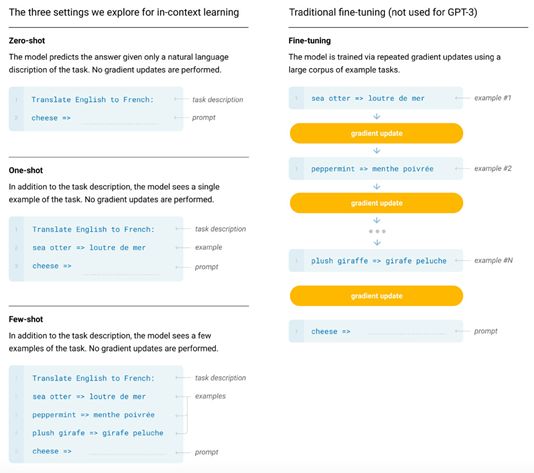
GPT-3可以像人类那样完成NLP任务。GPT-3的作者用训练好的模型去验证不同输入形式的推理效果,主要包括Zero-shot、One-shot和Few-shot。通常情况下BERT这类微调模型总是需要一些样例来更新模型的梯度参数从而让模型更加适应当前的任务。但是GPT-3可以通过不使用一条样例的Zero-shot、仅使用一条样例的One-shot和使用少量样例的Few-shot来完成推理任务。下面是对比微调模型和GPT-3三种不同的样本推理形式图:
3.3 不同版本的GPT-3
GPT-3总共有8个版本,下面是不同版本的参数详细说明:
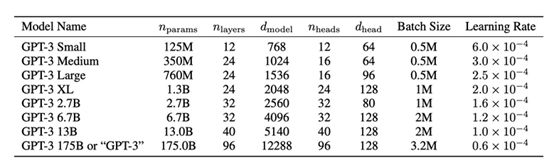
从上图可以看出最小的GPT-3 small的参数都比基础版本的BERT多,而最大的GPT-3 175B的参数直接达到了恐怖的175B。
3.4 GPT-3模型效果
GPT-3论文包含31个作者,整整72页论文,足可以说明工作量之大,全力演绎了“暴力出奇迹”,在一些NLP任务的数据集中使用少量样本的Few-shot方式甚至达到了最好效果,省去了模型微调,也省去了人工标注的成本。下图看看GPT-3论文庞大的作者阵容:
下面详细分析GPT-3模型的效果。下面是42个自然语言处理任务数据集中三种不同的样本数量方式随着模型参数增加模型分类效果图:
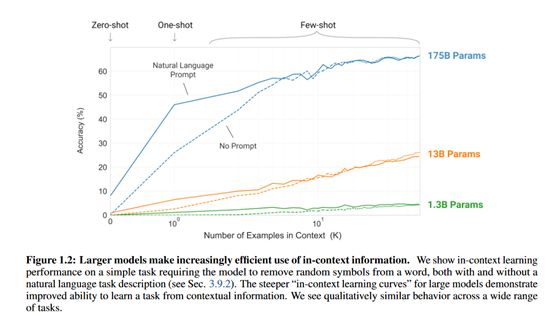
上图中横坐标是样本数量,没有使用样本代表Zero-shot,使用1条样本代表One-shot,使用少量样本则代表Few-shot。从图中可以看出,随着参数的增加模型的效果会有很大的提升,这也证明了模型参数更多并且使用更多的数据的确能有效提升模型效果。从上图中还可以看出GPT-3使用少量样本的Few-shot也能达到非常不错的效果。
下面是GPT-3模型在TriviaQA数据集上的实验结果图:
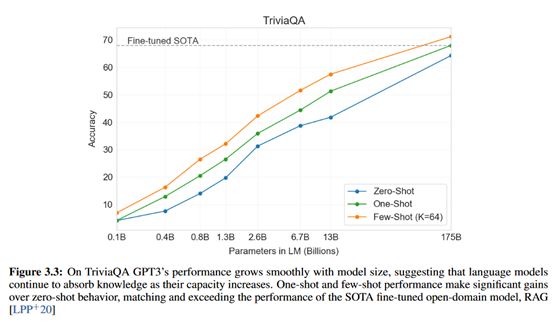
从上图中可以看出,在TriviaQA数据集上最大的GPT-3仅使用一条样本的One-shot就已经和最好效果的微调模型效果相当,使用64条样本的Few-shot的模型效果已经超越了最好效果的微调模型,这足以说明GPT-3模型的强大。不用标注样本或者仅使用少量样本就能轻松完成下游NLP任务,简直不要太爽。因为对于大多数NLPer来说,最难的莫过于如何获取又多又好的训练语料,但是现在GPT-3帮我们解决了这个问题,所以必须点赞。
下图是在PhysicalQA数据集中GPT-3模型不同输入样本形式的模型效果:
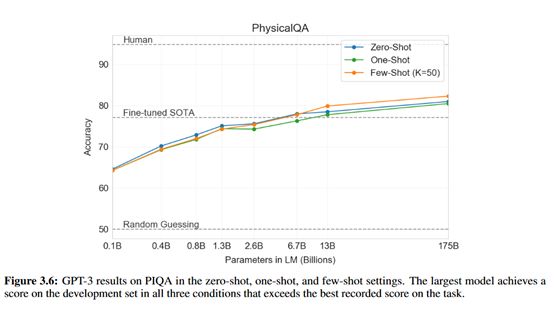
从上图中可以看出,尤其对于QA任务GPT-3即使不需要一条样本模型效果也能超越最好效果的微调模型。论文整整72页,里面还有很多NLP任务数据集的实验结果,小伙伴们有兴趣的可以看下论文。
小结下,GPT-3使用45TB的训练数据,拥有175B的参数量以巨大无比的姿态走进我们的视野。相比于目前NLP常见的预训练+微调两阶段模型,GPT-3直接干掉了微调阶段,让我们可以不使用或者仅仅使用极少的样本就可以很好的完成下游任务,帮助NLPer们解决了下游任务需要标注大量语料的烦恼。论文同时对比了Zero-shot、One-shot和Few-shot下GPT-3模型在不同数据集中的效果,尤其是在一些数据集中效果超越了最好效果的微调模型。GPT-3尤其擅长生成式任务,比如写故事之类的,网上甚至有言论说让GPT-3来完成红楼梦的后面部分,或者直接去写各种武侠玄幻小说,高产高效。对于我来说,后续我只需要列出我的思维导图,GPT-3是不是就可以直接帮我写文章啦,那样我的一百万字公众号小目标应该能尽早实现了。
总结
本篇主要介绍了GPT系列模型,主要包括GPT、GPT-2和GPT-3。首先介绍了NLP中超强但不秀的GPT模型。GPT属于典型的预训练+微调的两阶段模型,将Transformer作为特征抽取器,使用单向语言模型,属于NLP中非常重要的工作,同时还介绍了GPT模型下游如何改造成不同的NLP任务;然后介绍了有点火的GPT-2。相比于GPT来说GPT-2使用了更多更好的训练数据,同时直接使用无监督的方式来完成下游任务;最后介绍了巨无霸GPT-3。相比于GPT-2,GPT-3直接把模型的规模做到极致,使用了45TB的训练数据,拥有175B的参数量,真正诠释了暴力出奇迹。GPT-3模型直接不需要微调了,不使用样本或者仅使用极少量的样本就可以完成下游NLP任务,尤其在很多数据集中模型的效果直接超越了最好效果的微调模型,真正帮助我们解决了下游任务需要标注语料的问题。对GPT系列模型感兴趣的小伙伴可以一起沟通交流。
参考资料
[1] 《Language Models are few Shot Learners》
[2] The Illustrated Transformer
[3] AllenNLP Demo
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
