懒人必学常用的Shell脚本(运维之光)
目录
1 集群脚本自启动与关闭
2 查看集群jps的状态
3 shell+mysql的查询
4 单机安装软件脚本(重点!)
4.1.1 jdk的安装
4.1.2 jdk的移除
4.2.1 scala的安装
4.2.2 scala的移除
4.3.1 hadoop的安装
4.3.2 hadoop的卸载
4.4.1 nginx的安装
4.5.1 docker的shell一键安装脚本
4.6.1 zookeeper的一键安装脚本上场啦
5 运维相关的shell脚本
5.1 判断路径是否存在
5.2 网络+主机名+免密+虚拟机环境自动化安装脚本
1 集群脚本自启动与关闭
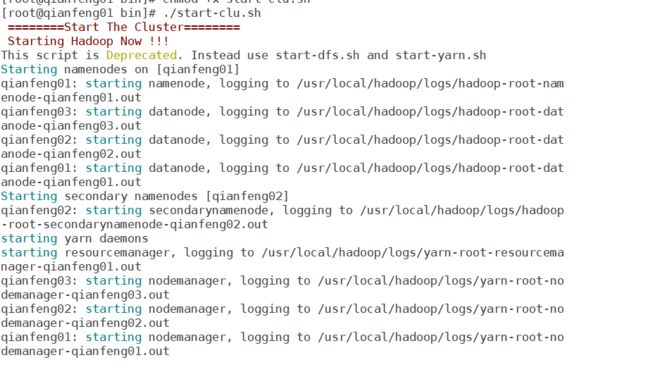
vi start-clu.sh
echo -e "\033[31m ========Start The Cluster======== \033[0m"
# start hadoop cluster
echo -e "\033[31m Starting Hadoop Now !!! \033[0m"
/usr/local/hadoop/sbin/start-all.sh
echo -e "\n"
sleep 2s
chmod +x start-clu.sh
./start-clu.sh
下面搞一个关闭的脚本
vi stop-clu.sh
# stop hadoop cluster
echo -e "\033[31m Stopping Hadoop Now !!! \033[0m"
/usr/local/hadoop/sbin/stop-all.sh
echo -e "\n"
sleep 5s
chmod +x stop-clu.sh
./stop-clu.sh

2 查看集群jps的状态
这个脚本一定要使用免密登录才可以
vi jps.sh
#!/bin/bash
echo "==============查询当前所有服务器的jps情况=============="
for i in qianfeng01 qianfeng02 qianfeng03
do
echo "**************$i当前jps情况***************"
ssh $i '/usr/local/jdk/bin/jps'
done
echo "=======================查询完毕========================"
chmod +x jps.sh
配置一下全局变量
vi /etc/profile
export PATH=$PATH:/bin
source /etc/profile
我先启动了hdfs,然后再看看一下状态

3 shell+mysql的查询
傻瓜式的shell脚本开发
在有mysql的服务器上创建脚本
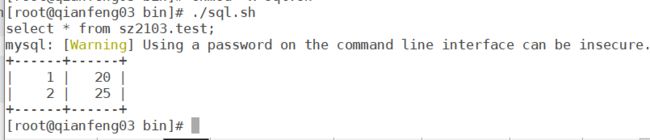
vi sql.sh
#!/bin/bash
sql="select * from sz2103.test;"
mysql="mysql -uroot -p@Mmforu45"
echo "${sql}"
${mysql} -N -e "${sql}"
chmod +x sql.sh
./sql.sh
4 单机安装软件脚本(重点!)
首先说一下,就是一般我们集群都不是一台服务器,就是我们可以先使用单机安装,然后再把/etc/profile以及安装的软件文件通过scp指令拷贝到其他服务器上也可以。现在就只需要学习单机环境安装就可以了。
4.1.1 jdk的安装
安装包:
链接:https://pan.baidu.com/s/1R5LaDIasYh4vpY_RUB_Qhw?pwd=tff2
提取码:tff2
--来自百度网盘超级会员V2的分享
先把jdk放到/opt/software里面
在root下面
mkdir -p bin
cd bin
vi install_jdk.sh
#!/bin/bash
# author : XXX
# vesion : 1.0
# date : 2022-04-24
# desc : 自动安装jdk
# 约定 > 配置 > 编码INSTALL_PREFIX=/opt/apps
JAVA_DIR=${INSTALL_PREFIX}/jdk1.8.0_45
JDK_TAR=/opt/software/jdk-8u45-linux-x64.tar.gz
ETC_PROFILE=/etc/profile# 提示使用方法的函数
usage() {
echo "请将jdk-8u45-linux-x64.tar.gz上传到/opt/software处然后再执行此脚本!!!"
}# 判断安装包是否已经存放到指定路径了,如果不存在就提示使用方法
if [ ! -e ${JDK_TAR} ]; then
usage
exit 0
fi# 已经安装过了
if [ -e ${JAVA_DIR} ]; then
echo "${JAVA_DIR}路径已经存在,JDK已经安装过了,无需再次安装!!!"
exit 0
fi# 如果安装前缀没有,就创建之
if [ ! -e ${INSTALL_PREFIX} ]; then
mkdir -p ${INSTALL_PREFIX}
echo "初始化目录:${INSTALL_PREFIX}"
fiif [ ! -e ${JAVA_DIR} ]; then
mkdir -p ${JAVA_DIR}
echo "初始化目录:${JAVA_DIR}"
fi## 解压JDK的tar包
tar -zxvf ${JDK_TAR} -C ${INSTALL_PREFIX}## 配置环境变量
cat << EOF >> ${ETC_PROFILE}
export JAVA_HOME=${JAVA_DIR}
export CLASS_PATH=.:${JAVA_DIR}/lib/dt.jar:${JAVA_DIR}/lib/tool.jar
export PATH=$PATH:${JAVA_DIR}/bin
EOFsource /etc/profile
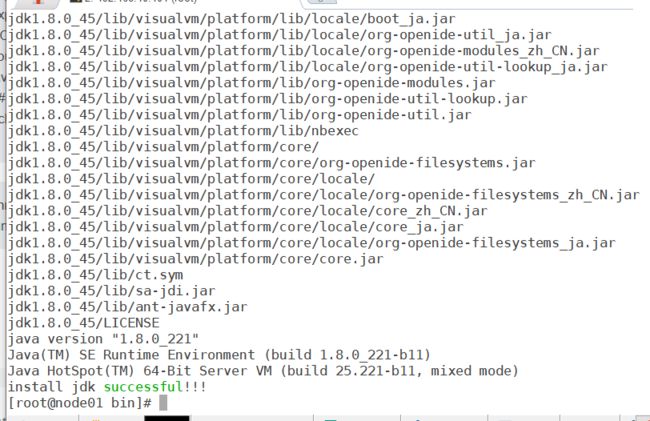
java -version
## 提示成功
echo "install jdk successful!!!"
chmod +x install_jdk.sh
./install_jdk.sh
4.1.2 jdk的移除
vi rm_jdk.sh
#!/bin/bash
dir=/opt/apps/jdk1.8.0_45
[ -d $dir ] && rm -rf $dir
chmod +x rm_jdk.sh
./rm_jdk.sh
4.2.1 scala的安装
安装包:
链接:https://pan.baidu.com/s/1oBbplZTIem1K0g4Wv_PD5Q?pwd=dzcb
提取码:dzcb
这次也是提前把scala的安装包放到/opt/software中
cd bin
vi install_scala.sh
#!/bin/bash
# author : XXX
# vesion : 1.0
# date : 2022-04-24
# desc : 自动安装scala
# 约定 > 配置 > 编码INSTALL_PREFIX=/opt/apps
SCALA_DIR=${INSTALL_PREFIX}/scala-2.11.8
SCALA_TAR=/opt/software/scala-2.11.8.tgz
ETC_PROFILE=/etc/profile# 提示使用方法的函数
usage() {
echo "请将scala-2.11.8.tgz上传到/opt/software处然后再执行此脚本!!!"
}# 判断安装包是否已经存放到指定路径了,如果不存在就提示使用方法
if [ ! -e ${SCALA_TAR} ]; then
usage
exit 0
fi# 已经安装过了
if [ -e ${SCALA_DIR} ]; then
echo "${SCALA_DIR}路径已经存在,JDK已经安装过了,无需再次安装!!!"
exit 0
fi# 如果安装前缀没有,就创建之
if [ ! -e ${INSTALL_PREFIX} ]; then
mkdir -p ${INSTALL_PREFIX}
echo "初始化目录:${INSTALL_PREFIX}"
fiif [ ! -e ${SCALA_DIR} ]; then
mkdir -p ${SCALA_DIR}
echo "初始化目录:${SCALA_DIR}"
fi## 解压JDK的tar包
tar -zxvf ${SCALA_TAR} -C ${INSTALL_PREFIX}## 配置环境变量
cat << EOF >> ${ETC_PROFILE}
export SCALA_HOME=${SCALA_DIR}
export PATH=$PATH:${SCALA_DIR}/bin
EOFsource /etc/profile
scala -version
## 提示成功
echo "install SCALA successful!!!"
chmod +x install_scala.sh
./install_scala.sh
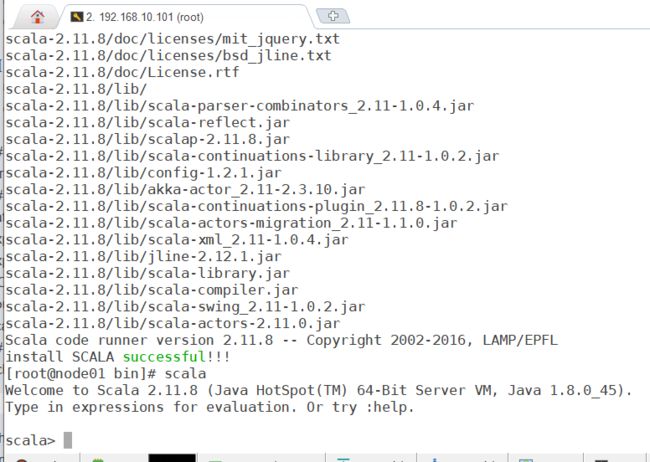
4.2.2 scala的移除
vi rm_scala.sh
#!/bin/bash
dir=/opt/apps/scala-2.11.8
[ -d $dir ] && rm -rf $dir
chmod +x rm_scala.sh
./rm_scala.sh
4.3.1 hadoop的安装
还是先把安装包上传到指定文件夹,然后就编写脚本
安装包:
链接:https://pan.baidu.com/s/1O-E4B1MUZjA90rsvEi1nwQ?pwd=q0ey
提取码:q0ey
--来自百度网盘超级会员V2的分享
vi install_hadoop.sh
##1. install_hadoop.sh
#!/bin/bash# author : XX
# vesion : 1.0
# date : 2022-04-24
# desc : 自动安装hadoop
# 约定 > 配置 > 编码INSTALL_PREFIX=/opt/apps
JAVA_DIR=${INSTALL_PREFIX}/jdk1.8.0_45
HADOOP_DIR=${INSTALL_PREFIX}/hadoop-2.8.1
HADOOP_TAR=/opt/software/hadoop-2.8.1.tar.gz
ETC_PROFILE=/etc/profile# 提示使用方法的函数
usage() {
echo "请将hadoop-2.8.1.tar.gz上传到/opt/software处然后再执行此脚本!!!"
}# 判断安装包是否已经存放到指定路径了,如果不存在就提示使用方法
if [ ! -e ${HADOOP_TAR} ]; then
usage
exit 0
fi# 已经安装过了
if [ -e ${HADOOP_DIR} ]; then
echo "${HADOOP_DIR}路径已经存在,Hadoop已经安装过了,无需再次安装!!!"
exit 0
fi# 如果安装前缀没有,就创建之
if [ ! -e ${INSTALL_PREFIX} ]; then
mkdir -p ${INSTALL_PREFIX}
echo "初始化目录:${INSTALL_PREFIX}"
fiif [ ! -e ${HADOOP_DIR} ]; then
mkdir -p ${HADOOP_DIR}
echo "初始化目录:${HADOOP_DIR}"
fi## 解压JDK的tar包
tar -zxvf ${HADOOP_TAR} -C ${INSTALL_PREFIX}## 配置Hadoop
## hadoop-env.sh
cat << EOF >> ${HADOOP_DIR}/etc/hadoop/hadoop-env.sh
JAVA_HOME=/opt/apps/jdk1.8.0_45
EOF## core-site.xml
cat << EOF > ${HADOOP_DIR}/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://192.168.10.101:9000
hadoop.tmp.dir
${HADOOP_DIR}/hdpdata
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
EOF## hdfs-site.xml
cat << EOF > ${HADOOP_DIR}/etc/hadoop/hdfs-site.xml
fs.replication
1
dfs.http.address
qianfeng01:50070
dfs.secondary.http.address
qianfeng01:50090
dfs.namenode.name.dir
${HADOOP_DIR}/hdpdata/dfs/name
dfs.datanode.data.dir
${HADOOP_DIR}/hdpdata/dfs/data
dfs.checkpoint.dir
${HADOOP_DIR}/hdpdata/dfs/checkpoint/cname
dfs.checkpoint.edits.dir
${HADOOP_DIR}/hdpdata/dfs/checkpoint/cname
dfs.permissions
false
EOF
## yarn-site.xml
cat << EOF > ${HADOOP_DIR}/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
qianfeng01
yarn.resourcemanager.address
qianfeng01:8032
yarn.resourcemanager.scheduler.address
qianfeng01:8030
EOF
## mapred-site.xml
mv ${HADOOP_DIR}/etc/hadoop/mapred-site.xml.template ${HADOOP_DIR}/etc/hadoop/mapred-site.xml
cat << EOF > ${HADOOP_DIR}/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
qianfeng01:10020
mapreduce.jobhistory.webapp.address
qianfeng01:19888
EOF## slaves
cat << EOF > ${HADOOP_DIR}/etc/hadoop/slaves
qianfeng01
EOF## 配置环境变量
cat << EOF >> ${ETC_PROFILE}
export HADOOP_HOME=${HADOOP_DIR}
export PATH=$PATH:${HADOOP_DIR}/bin:${HADOOP_DIR}/sbin
EOFsource /etc/profile
hadoop version
## 格式化
${HADOOP_DIR}/bin/hdfs namenode -format## 提示成功
echo "install hadoop successful!!!"
chmod +x install_hadoop.sh
./install_hadoop.sh
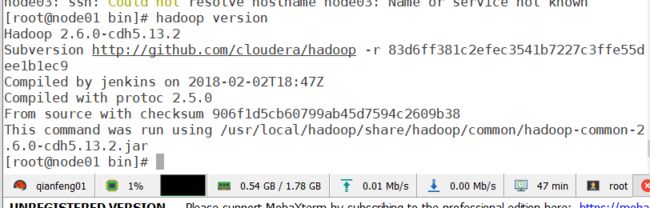
我是想启动集群的,但是忘记了现在这个集群是三台机器。
4.3.2 hadoop的卸载
其实我就是把hadoop的安装文件删除了而已
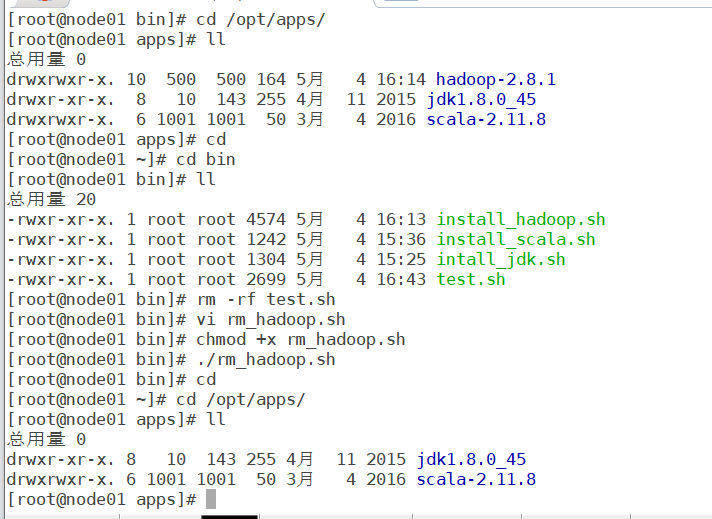
vi rm_hadoop.sh
#!/bin/bash
dir=/opt/apps/hadoop-2.8.1
[ -d $dir ] && rm -rf $dir
chmod +x rm_hadoop.sh
执行之后的结果
4.4.1 nginx的安装
vi install_nginx.sh
#!/bin/bash
# nginx安装包链接
nginx_url="http://nginx.org/download/nginx-1.18.0.tar.gz"
# 下载包存放路径
path="/tmp/"
# 安装路径int_path="/opt/apps/nginx"
# 首先检查网络
ping -c 1 114.114.114.114 > /dev/null 2>&1
if [ $? -eq 0 ];then
echo "检测网络正常!"# 配置阿里源
read -p "配置阿里源输入1,任意键跳过配置:" number
case "$number" in
1)
echo "正在配置阿里源..."
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup > /dev/null 2>&1
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo > /dev/null 2>&1
yum clean all > /dev/null 2>&1
yum makecache > /dev/null 2>&1
echo "阿里源配置已完成!"
;;
*)
echo "已跳过配置阿里源!"
esac# 安装依赖包
echo "正在安装依赖包..."
yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel wget > /dev/null 2>&1
if [ $? -eq 0 ];then
echo "依赖包安装已完成!"# 下载Nginx包
echo "正在下载安装包和解压安装操作..."
wget $nginx_url -P $path > /dev/null 2>&1
# 创建文件夹,解压安装
mkdir $int_path && cd $int_path
nginx_pack=`echo $nginx_url | awk -F '/' '{print $NF}'`
tar -xf $path/$nginx_pack -C ./
# 编译安装
nginx_path=`echo $nginx_pack |awk -F '.' '{print $1"."$2"."$3}'`
cd $nginx_path && ./configure > /dev/null 2>&1
make > /dev/null 2>&1
make install > /dev/null 2>&1
echo "Nginx 安装已完成!"
echo -e "#####################################\n启动Nginx: $int_path/sbin/nginx\n停止Nginx: $int_path/sbin/nginx -s stop\n重载Nginx: $int_path/sbin/nginx -s reload\n检查Nginx: $int_path/sbin/nginx -t\n#####################################"
else
echo "依赖包安装失败,请检查yum源或者网络问题!!!"
exit 1
fi
else
echo "检测网络连接异常,请检查网络再操作!"
exit 1
fi
chmod +x install_nginx.sh
./install_nginx.sh

其实我感觉是存在一些问题的
4.5.1 docker的shell一键安装脚本
touch install_docker.sh
chmod 777 install_docker.sh
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
echo -e " =========== 1.delete exist docker ================\n\n"echo -e "step 1: 安装必要的一些系统工具"
yum install -y yum-utils device-mapper-persistent-data lvm2echo -e "\n\nStep 2: 添加软件源信息,国内 Repository 更加稳定"
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repoversion= cat /etc/redhat-release|sed -r 's/.* ([0-9]+)\..*/\1/'
if $version=7; then
echo -e "\n\nStep 3: 更新 Centos version is : $version; run yum makecache fast"
yum makecache fast
elif $version=8; then
echo -e "\n\nStep 3: 更新Centos version is : $version; run yum makecache fast"
dnf makecache
fiecho -e "=========== 2.完成配置 docker Repository ================\n\n"
# 安装最新版本的 Docker Engine 和 Container
yum install docker-ce docker-ce-cli containerd.io
yum -y install docker-ce
echo -e "=========== 3.成功安装完 docker ================\n\n"systemctl enable docker
systemctl start dockerecho -e "=========== 4.自启动 docker ================\n\n"
# 1.创建一个目录
mkdir -p /etc/docker
# 2.编写配置文件
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://reg-mirror.qiniu.com",
"http://f1361db2.m.daocloud.io"
]
}
EOF
systemctl daemon-reload
systemctl restart dockerecho -e "=========== 5.配置国内镜像加速 ================\n\n"
docker ps -a
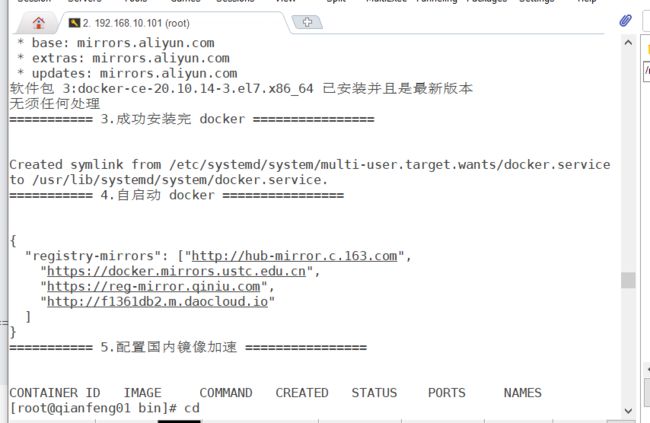
尝试了一下安装还ok。
4.6.1 zookeeper的一键安装脚本上场啦
安装包
链接:https://pan.baidu.com/s/1nUxAxX7coz_SoCNMgAPglQ
提取码:t4hy
--来自百度网盘超级会员V2的分享
vi install_zk.sh#!/bin/bash
INSTALL_PREFIX=/opt/apps
ZOOKEEPER_DIR=${INSTALL_PREFIX}/zookeeper-3.4.10
ZOOKEEPER_TAR=/opt/software/zookeeper-3.4.10.tar.gz
ETC_PROFILE=/etc/profile
# 提示使用方法的函数
usage() {
echo "请将zookeeper-3.4.10.tar.gz上传到/opt/software处然后再执行此脚本!!!"
}
# 判断安装包是否已经存放到指定路径了,如果不存在就提示使用方法
if [ ! -e ${ZOOKEEPER_TAR} ]; then
usage
exit 0
fi
# 已经安装过了
if [ -e ${ZOOKEEPER_DIR} ]; then
echo "${ZOOKEEPER_DIR}路径已经存在,ZOOKEEPER已经安装过了,无需再次安装!!!"
exit 0
fi
# 如果安装前缀没有,就创建之
if [ ! -e ${INSTALL_PREFIX} ]; then
mkdir -p ${INSTALL_PREFIX}
echo "初始化目录:${INSTALL_PREFIX}"
fi
if [ ! -e ${ZOOKEEPER_DIR} ]; then
mkdir -p ${ZOOKEEPER_DIR}
echo "初始化目录:${HADOOP_DIR}"
fi
#解压安装包
tar -zxvf ${ZOOKEEPER_TAR} -C ${INSTALL_PREFIX}
## 配置环境变量
cat << EOF >> ${ETC_PROFILE}
export ZOOKEEPER_HOME=${ZOOKEEPER_DIR}
export PATH=$PATH:${ZOOKEEPER_DIR}/bin
EOF
source /etc/profile
#配置
cp ${ZOOKEEPER_DIR}/conf/zoo_sample.cfg ${ZOOKEEPER_DIR}/conf/zoo.cfg
cat << EOF > ${ZOOKEEPER_DIR}/conf/zoo.cfg
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/software/zookeeper-3.4.10/zkData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=qianfeng01:2888:3888
EOF
#创建文件
mkdir -p ${ZOOKEEPER_DIR}/zkData
touch ${ZOOKEEPER_DIR}/zkData/myid
cat << EOF >> ${ZOOKEEPER_DIR}/zkData/myid
1
EOF
chmod +x install_zk.sh
./install_zk.sh个人尝试过啦,安装成功了。
但是吧,我这个环境变量配置得有点问题。(好乱,不影响全局变量)
下面就是使用脚本的,嘻嘻安装好了。
因为我参考了之前发的博客内容,把自己带偏了。我zookeeper启动命令都搞忘记了

5 运维相关的shell脚本
5.1 判断路径是否存在
vi exist.sh
#!/bin/bash
read -p "Input a path:" path
if [ -L $path -a -e $path ];then
echo "this is effective link"
elif [ -L $path -a ! -e $path ];then
echo "this is not effective link"
elif [ -d $path ];then
echo "this is a director"
elif [ -f $path ];then
echo "this is file"
elif [ -e $path ];then
echo "this is a other type file"
else
echo "the file is not exist"
fichmod +x exist.sh
./exist.sh
5.2 网络+主机名+免密+虚拟机环境自动化安装脚本
因为之前我做项目的时候,因为虚拟机原因老是重搭虚拟机,不完全统计是搭了二十多遍了。
我之前有个虚拟机的纯净版,但是别人的搭建的,自己不太敢使用,其实我也在想如何做一个纯净版的虚拟机环境。现在就编写了一个简陋的网络配置和主机配置脚本,不喜勿喷。个人在shell编程这边也不太熟悉哈。
注意一下:我的虚拟机使用的静态网的net8模式
就是在搞这个脚本之前要自己看一下虚拟机的网络配置,桥接网络我很久没用过了。其实步骤和我现在搞的差不多。至于动态网络的搭建,大学的知识回给老师了(无奈)。
vmware的编辑菜单-->虚拟网络编辑器-->更改设置-->选中VMnet8,修改子网IP段位为192.168.10.0
-->点击应用-->点击NAT设置,查看相关信息,比如
子网IP、子网掩码、网关
vi install_net.sh
#!/bin/bash
NET_CONF=/etc/sysconfig/network-scripts/ifcfg-ens33
HOSTS=/etc/hosts
#配置网关
cat << EOF > ${NET_CONF}
TYPE=Ethernet
BOOTPROTO=static
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.10.100
NETMASK=255.255.255.0
GATEWAY=192.168.10.2
DNS1=192.168.10.2
DNS2=8.8.8.8
DNS3=114.114.114.114
EOF
#重启网络服务项
systemctl restart network
#查看ip地址
ip addr
#有关防火墙和networkmanager两者都要关
systemctl stop firewalld
systemctl disabled firewalld
systemctl stop firewalld
systemctl disabled firewalld
#主机名的修改
hostnamectl set-hostname pure
#主机名的查看
hostname
#主机映射名的修改
cat << EOF >> ${HOSTS}
192.168.10.100 pure
192.168.10.101 qianfeng01
192.168.10.102 qianfeng02
192.168.10.103 qianfeng03
EOF
#虚拟机其他环境的安装比较重要
#安装其他软件环境
yum install -y curl.x86_64
yum install -y wget.x86_64
yum -y install net-tools.x86_64
yum -y install bzip2.x86_64
yum -y install unzip.x86_64
yum -y install perl
yum -y install zip.x86_64
yum -y install psmisc
yum -y install vim
yum -y install gcc gcc-c++
yum -y install ntpdate
#同步时间
ntpdate -u ntp1.aliyun.com
#免密登录,第一步是全部回车,第二个主机号就是对免密的主机号
ssh-keygen -t rsa
ssh-copy-id -i purechmod +x install_net.sh
./install_net.sh