k近邻算法的原理、示例与分析
k近邻算法的原理、示例与分析
代码参考书籍
Python机器学习基础教程. Andreas C.muller, Sarah Guido著(张亮 译). 北京:人民邮电出版社,2018.1(2019.6重印)
实现环境
System:Ubuntu server 20.04 (Jupyter notebook)
GPU:GeForce GTX 1080Ti(2块)
Driver Version: 450.36.06
CUDA Version: 11.0
Python Version: 3 .8.5
TensorFlow Version:2.4.1
1. 算法概述
近邻算法是最简单的监督学习算法,它既可以用于处理分类问题,也可以用于解决回归问题;构建模型只需要保存训练数据集即可,模型容易理解,往往不需要过多调节就可以得到不错的性能;但对于训练样本大,特征向量维度大(几百)的数据集往往效果不好(计算复杂度高),对于大多数特征的取值为0的稀疏数据集,效果尤其不好。
应用时,k越小,模型的偏差越小,泛化能力越弱;当k很小时,可能造成过拟合。反之,k越大,模型的偏差越大,对噪声数据越不敏感,泛化能力越强;当k值很大时,可能造成欠拟合。
2.算法原理
2.1 分类问题
依据相似度确定未知对象的类别是人类对事物进行分类的最简单方法,正所谓“物以类聚人以群分”。k近邻算法(KNN算法)由Thomas等人在1967年提出[1]。它正是基于以上思想:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计出这些样本的类别并进行投票,票数最多的那个类就是分类的结果[2]。
预测算法(分类)的流程如下:
(1)在训练样本集中找出距离待测样本x_test最近的k个样本,并保存至集合N中;
(2)统计集合N中每一类样本的个数 C i , i = 1 , 2 , . . . c C_{i}, i=1,2,...c Ci,i=1,2,...c。
(3)最终的分类结果为 a r g m a x C i arg maxC_{i} argmaxCi(最大的对应的 C i C_i Ci那个类)。
在上述实现过程中,k的取值尤为重要。它可以根据问题和数据特点来确定。在具体实现时,可以考虑样本的权重,即每个样本有不同的投票权重,这种方法称为带权重的k近邻算法,它是一种变种的k近邻算法。
2.2 回归问题
假设离测试样本最近的k个训练样本的标签值为 y i y_i yi,则对样本的回归预测输出值为:
y ^ = ( ∑ i = 1 k y i ) / k (1) \hat{y}=(\sum_{i=1}^{k}y_i)/k \tag{1} y^=(i=1∑kyi)/k(1)
即为所有邻居的标签均值。
带样本权重的回归预测函数为: y ^ = ( ∑ i = 1 k w i y i ) / k (2) \hat{y}=(\sum_{i=1}^{k}w_iy_i)/k \tag{2} y^=(i=1∑kwiyi)/k(2)其中 w i w_i wi为第个 i i i样本的权重。
2.3 距离的定义
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。对于 R n R^n Rn空间中的两点 x \boldsymbol{x} x和 y \boldsymbol{y} y,它们之间的欧氏距离定义为:
d ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 (3) d(\boldsymbol{x},\boldsymbol{y})=\sqrt{\sum_{i=1}^{n}(x_i-y_i)^2} \tag{3} d(x,y)=i=1∑n(xi−yi)2(3)
需要特别注意的是,使用欧氏距离时,应将特征向量的每个分量归一化,以减少因为特征值的尺度范围不同所带来的干扰,否则数值小的特征分量会被数值大的特征分量淹没。
其它的距离计算方式还有Mahalanobis距离、Bhattacharyya距离等。
3 示例
3.1 几个常见的数据集
(1)forge数据集:来源于mglearn,一个模拟的二分类数据集示例。
#载入常用Python科学库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
# generate dataset
X, y = mglearn.datasets.make_forge()
# plot dataset
mglearn.discrete_scatter(X[:, 0], X[:, 1], y) #绘制散点图
plt.legend(["Class 0", "Class 1"], loc=4)
plt.xlabel("First feature") #X轴标识
plt.ylabel("Second feature") #Y轴标识
print("X.shape:", X.shape)
#数据集包含26个样本,每个样本有2个特征
X.shape: (26, 2)

(2)wave数据集:来源于mglearn,模拟数据集,用于线性回归算法
X, y = mglearn.datasets.make_wave(n_samples=40)
plt.plot(X, y, 'o') #数据点标签类型
plt.ylim(-3, 3) #设置y轴的显示范围为(-3,3)
plt.xlabel("Feature")
plt.ylabel("Target")
plt.show()
#40个样本,每个样本只有1个特征,是一个低维的数据集
#本书个更多的使用低维数据集,因为毕竟方便可视化,也比较好解释算法。

(3)乳腺癌数据集:来源于scikit-learn,真实数据集,有569个数据点,每个数据点30个特征。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("cancer.keys():\n", cancer.keys())
cancer.keys():
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
print("Shape of cancer data:", cancer.data.shape)
Shape of cancer data: (569, 30)
print("Sample counts per class:\n",
{n: v for n, v in zip(cancer.target_names, np.bincount(cancer.target))})
#格式:np.bincount(a)
#注意:返回一个数组,其长度等于a中元素最大值加1,每个元素值则是它当前索引值在a中出现的次数。
#python: for in zip() 并行遍历 。注意,在Python中,为了优化内存,ZIP()只能访问一次,第二次就空了
#参考:http://www.zzvips.com/article/146313.html
Sample counts per class:
{'malignant': 212, 'benign': 357}
print("Feature names:\n", cancer.feature_names) #特征名称
Feature names:
['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness' 'mean compactness' 'mean concavity'
'mean concave points' 'mean symmetry' 'mean fractal dimension'
'radius error' 'texture error' 'perimeter error' 'area error'
'smoothness error' 'compactness error' 'concavity error'
'concave points error' 'symmetry error' 'fractal dimension error'
'worst radius' 'worst texture' 'worst perimeter' 'worst area'
'worst smoothness' 'worst compactness' 'worst concavity'
'worst concave points' 'worst symmetry' 'worst fractal dimension']
(4)波士顿房价数据集:来源于scikit-learn,真实数据集,有506个数据点,每个数据点13个特征。
from sklearn.datasets import load_boston
boston = load_boston()
print("Data shape:", boston.data.shape)
Data shape: (506, 13)
进行特征工程后,每个数据点拥有104个特征。
X, y = mglearn.datasets.load_extended_boston()
print("X.shape:", X.shape)
X.shape: (506, 104)
3.2 k近邻分类
(1)基于mglearn的k近邻分类
k=1时,是最简单的k近邻分类。也即,要预测的数据点的类别与它最近的训练集数据点相同。例如,下图所示的3个星型测试点的预测。
import matplotlib.pyplot as plt
import mglearn
mglearn.plots.plot_knn_classification(n_neighbors=1)
plt.show()
# k = 1,只考虑一个近邻

mglearn.plots.plot_knn_classification(n_neighbors=3)
plt.show()

(2)基于scikit-learn的k近邻分类:
from sklearn.model_selection import train_test_split #加载数据分割函数:随机选取75%作为训练集,剩下的25%作为测试集。
X, y = mglearn.datasets.make_forge() #生产forge数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #数据分割
from sklearn.neighbors import KNeighborsClassifier #加载k近邻分类函数
clf = KNeighborsClassifier(n_neighbors=3) #实例化,获得分类实例clf
clf.fit(X_train, y_train) #分类拟合,模型训练
out[38]:KNeighborsClassifier(n_neighbors=3)
print("Test set predictions:", clf.predict(X_test)) #调用predict()方法来对测试输出进行预测。 模型测试
Test set predictions: [1 0 1 0 1 0 0]
print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test))) #用score方法进行模型评估。
Test set accuracy: 0.86
(3) 分析k近邻分类器
在XY平面上画出所有可能的测试点的预测结果,并根据类别进行着色,查看决策边界。
fig, axes = plt.subplots(1, 3, figsize=(10, 3)) #1行3列,类似于MATLAB的绘图命令
for n_neighbors, ax in zip([1, 3, 9], axes): #分别绘制k=1,3,9时的预测结果
# the fit method returns the object self, so we can instantiate
# and fit in one line
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y) #对所有的数据进行训练
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4) #绘制决策边界
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax) #绘制散点图,显示数据点的位置
ax.set_title("{} neighbor(s)".format(n_neighbors)) #标题
ax.set_xlabel("feature 0") # x轴标识
ax.set_ylabel("feature 1") # y轴标识
axes[0].legend(loc=3) #第一个图给出图例
# 调试技巧,可以通过屏蔽mglearn.plots.plot_2d_separator,运行结果和没有之前的进行对比,就知道分界线的效果了。
out[84]:
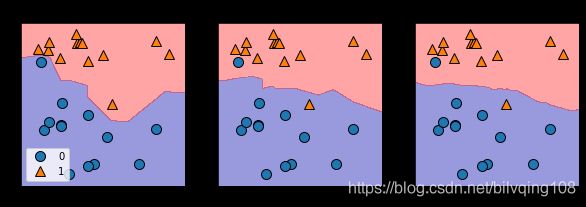
从上图可以看出,使用单一邻居绘制的决策边界紧跟着训练数据。随着邻居个数越来越多,决策边界也越来越平滑,更平滑的边界对应更简单的模型。 即更少的邻居对应更高的模型复杂度,更多的邻居对应更低的模型复杂度。
考虑极端情况,即邻居个数等于训练集中所有数据点的个数,那么每个测试点的邻居都完全相同(即所有训练点),所有预测结果也完全相同(即训练集中出现次数最多的类别)。
(4) 模型复杂度和泛化能力之间的关系
以乳腺癌数据集为例,用不同的k值对训练集和测试集的性能进行评估。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() # 加载乳癌数据集,并分割
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
# try n_neighbors from 1 to 10
neighbors_settings = range(1, 11) # k=(1,11)
for n_neighbors in neighbors_settings:
# build the model
clf = KNeighborsClassifier(n_neighbors=n_neighbors) # 实例化
clf.fit(X_train, y_train)
# record training set accuracy
training_accuracy.append(clf.score(X_train, y_train)) # 训练集评分
# record generalization accuracy
test_accuracy.append(clf.score(X_test, y_test)) # 测试集评分
plt.plot(neighbors_settings, training_accuracy, label="training accuracy") # 训练精度曲线显示
plt.plot(neighbors_settings, test_accuracy, label="test accuracy") # 测试精度曲线显示
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
plt.show()
out[44]:

从上图可看出,仅考虑一近邻时(k=1),训练集上的预测结果十分完美,模型较复杂,训练集精度远大于测试集精度,模型可能过拟合,泛化能力较弱。随着近邻数量的增多,模型变得简单,训练集精度也随之下降,而测试集精度上升,模型泛化能力也逐渐提高。而当近邻数较大时(k=10),模型的训练集精度和测试集精度相对较低,模型过于简单,性能变差,如再进一步增加近邻个数,可能会出现欠拟合。
3.3 k近邻回归
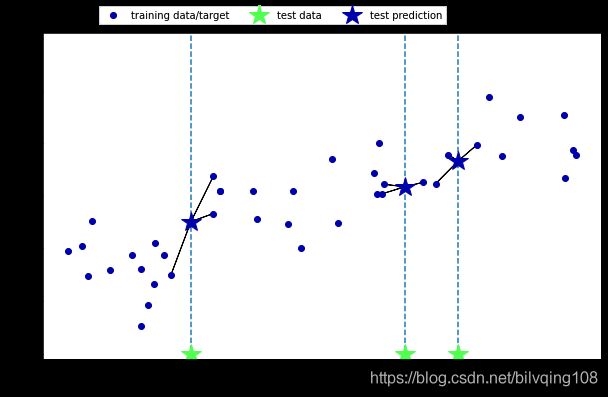
回归的预测目标是一个连续的值。k近邻算法亦可以用于回归。以单一近邻开始,使用wave数据集为示例。
(1) 使用mglearn实现k近邻回归算法
import matplotlib.pyplot as plt
import mglearn
mglearn.plots.plot_knn_regression(n_neighbors=1) # 使用wave数据集,k=1
plt.show()

mglearn.plots.plot_knn_regression(n_neighbors=3) # k=3,预测值等于3个近邻数据点的平均值
(2)使用scikit-learn中的kNeighborRegressor类实现k近邻回归算法
import matplotlib.pyplot as plt
import mglearn
from sklearn.neighbors import KNeighborsRegressor # 加载KNeighborsRegressor
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_wave(n_samples=40) # 产生数据集
# split the wave dataset into a training and a test set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) # 数据分割
# instantiate the model and set the number of neighbors to consider to 3
reg = KNeighborsRegressor(n_neighbors=3) # 实例化
# fit the model using the training data and training targets
reg.fit(X_train, y_train) # 模型训练
out[91]:KNeighborsRegressor(n_neighbors=3)
print("Test set predictions:\n", reg.predict(X_test)) # 模型测试
Test set predictions:
[-0.05396539 0.35686046 1.13671923 -1.89415682 -1.13881398 -1.63113382
0.35686046 0.91241374 -0.44680446 -1.13881398]
print("Test set predictions:\n", reg.predict(X_test)) # 模型测试
Test set R^2: 0.83
输出测试分数 R 2 R^{2} R2 叫做决定系数,是回归模型的优先度度量,它的取值范围是:0-1. [3]。
R _ s c o r e 2 = 1 − ∑ i ( y ^ i − y i ) 2 ∑ i ( y ˉ − y i ) 2 = 1 − ∑ i ( y ^ i − y i ) 2 / m ∑ i ( y ˉ − y i ) 2 / m = 1 − M S E ( y ^ , y ) V a r ( y ) R_{\_score}^2=1-\frac{\sum_{i}(\hat{y}_i-y_i)^2}{\sum_{i}(\bar{y}-y_i)^2}=1-\frac{\sum_{i}(\hat{y}_i-y_i)^2/m}{\sum_{i}(\bar{y}-y_i)^2/m}=1-\frac{MSE(\hat{y},y)}{Var(y)} R_score2=1−∑i(yˉ−yi)2∑i(y^i−yi)2=1−∑i(yˉ−yi)2/m∑i(y^i−yi)2/m=1−Var(y)MSE(y^,y)
决定系数反应了y的波动有多少百分比能被x的波动所描述,即表征依变数Y的变异中有多少百分比,可由控制的自变数X来解释。
拟合优先度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。
本模型的分数是0.83,表示拟合相对较好。
(3)分析k近邻回归
采用一维数据集,以便可以查看所有特征取值对应的预测结果。在以下示例中,创建一个在(-3,3)范围内,具有1000个数据点的测试数据集。它们的预测结果近似一条连续的曲线。
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# create 1,000 data points, evenly spaced between -3 and 3 创建1000个分布在(-3,3)的均匀数据点
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
for n_neighbors, ax in zip([1, 3, 9], axes): # k=1,3,9
# make predictions using 1, 3, or 9 neighbors
reg = KNeighborsRegressor(n_neighbors=n_neighbors) # 实例化
reg.fit(X_train, y_train) # 模型训练
ax.plot(line, reg.predict(line)) # 测试,1000个数据点,形成预测曲线
ax.plot(X_train, y_train, '^', c=mglearn.cm2(0), markersize=8)
ax.plot(X_test, y_test, 'v', c=mglearn.cm2(1), markersize=8)
ax.set_title(
"{} neighbor(s)\n train score: {:.2f} test score: {:.2f}".format(
n_neighbors, reg.score(X_train, y_train),
reg.score(X_test, y_test)))
ax.set_xlabel("Feature")
ax.set_ylabel("Target")
axes[0].legend(["Model predictions", "Training data/target",
"Test data/target"], loc="best")
out[54]:
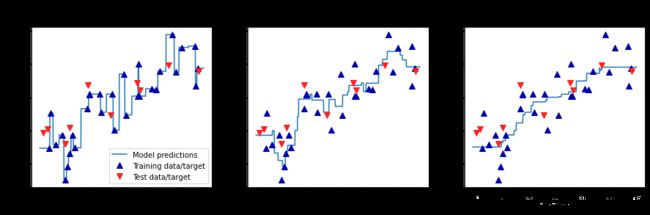
从上图可知,使用单一邻居时,训练集中的每个点都对预测结果由显著影响,预测结果的图像经过所有数据点,这导致预测结果十分不稳定。考虑更多的邻居之后,预测结果变得更加平滑,但对训练数据的拟合也不好。
(4)k近邻回归的优点、缺点和参数
参数:一般来说,KNeighbors分类器有两个重要参数——邻居个数和数据点之间距离的度量方法。实践中使用较小的邻居个数(比如3个或5个)往往可以取得比较好的结果,但也应该调节这个参数。默认使用欧式距离,在许多情况下效果都很好。
优点:模型很好理解,通常不需要过多调节就可以得到不错的性能,所以在考虑使用更高级的技术前,尝试此算法是一种很好的基准方法;构建最近邻模型的速度通常很快,但如果训练集很大(特征数很多或者样本数很大),预测速度可能会比较慢。
缺点:使用k-NN算法时,对数据进行预处理时很重要的,这一算法对于有很多特征(几百或更多)的数据集往往效果不好,对于大多数特征的大多数取值都为0的数据集(所谓的稀疏数据集)来说,效果尤其不好;虽然很容易理解,但由于预测速度慢且不能处理具有很多特征的数据集,所以实践中往往不会用到。
参考
- [1] Cover T, Hart P. Nearest neighbor pattern classification[J]. IEEE transactions on information theory, 1967, 13(1): 21-27.
- [2] 雷明; 机器学习与应用. 北京:清华大学出版社, 2019.
- [3] https://blog.csdn.net/snowdroptulip/article/details/79022532