[paper reading] CornerNet
[paper reading] CornerNet
GitHub:Notes of Classic Detection Papers
本来想放到GitHub的,结果GitHub不支持公式。
没办法只能放到CSDN,但是格式也有些乱
强烈建议去GitHub上下载源文件,来阅读学习!!!这样阅读体验才是最好的
当然,如果有用,希望能给个star!
| topic | motivation | technique | key element | math | use yourself | relativity |
|---|---|---|---|---|---|---|
| CornerNet | Problem to Solve KeyPoints (Anchor-Free) |
CornerNet Stacked Hourglass Network Prediction Module Corner Pooling |
Why CornerNet Better? Why Corner Pooling Works Grouping Corners Getting Bounding Box Data Augmentation Ablation Experiments |
Loss Function Corner Pooling Math |
Network Design Interpretability Divide Task TTA |
Two-Stage One-Stage |
文章目录
- [paper reading] CornerNet
-
- Motivation
-
- Problem to Solve
- KeyPoints (Anchor-Free)
- Technique
-
- CornerNet
-
- Idea
- Architecture
- Components
- Stacked Hourglass Network
-
- Components
- Hourglass Module
- Advantage
- Improvement & Settings
- Details
- Prediction Module
- Corner Pooling
- Key Element
-
- Why CornerNet Better?
- Why Corner Pooling Works
- Grouping Corners
- Getting Bounding Box
- Data Augmentation
-
- Training
- Testing
- Ablation Experiments
-
- Corner Pooling
- Stability of Corner Pooling over Larger Area
- Reducing Penalty to Negative Locations
- Hourglass Network Works
- Quality of the Bounding Boxes
- Error Analysis
- Compared to SOTA
- Math
-
- Loss Function
-
- Detection Loss
- Offset Loss
- Pull Loss
- Push Loss
- Corner Pooling Math
- Use Yourself
-
- Network Design
- Intuition & Interpretability
-
- Interpretability For Delicate Motivation
- Anchor-Based or Anchor-Free
- Divide Task
- TTA
- Related Work
-
- Two-Stage
-
- R-CNN
- SPP & Fast-RCNN
- Faster RCNN
- R-FCN
- DeNet
- One-Stage
-
- YOLO
- SSD
- DSSD & RON
- RetinaNet
- RefineDet
- Point Linking Network(PLN)
- Blogs
Motivation
Problem to Solve
anchor的使用会带来一些弊端
-
需要大量的anchor
以确保ground-truth box的覆盖率
这会导致极端的正负样本不平衡,导致训练低效、网络退化
-
引入许多的hyperparameters和design choice
以确保模型对于各种scale和ratio的object都具有良好的基准
这在multi-scale的architecture中会更复杂(比如SSD和RetinaNet)
KeyPoints (Anchor-Free)
即:使用一对KeyPoints表示一个bounding box
Technique
CornerNet
Idea
使用一对KeyPoints表示一个bounding box
Architecture
![[paper reading] CornerNet_第1张图片](http://img.e-com-net.com/image/info8/da810ee687d4421b9f0b2086936c6488.jpg)
![[paper reading] CornerNet_第2张图片](http://img.e-com-net.com/image/info8/6a518914e92f4a9aab6c374a1bf01af4.jpg)
Components
- backbone
- 2 prediction module
Stacked Hourglass Network
Components
Stacked Hourglass Network = 2 Hourglass Module ==> ×4 downsampleing
Hourglass Module
![[paper reading] CornerNet_第3张图片](http://img.e-com-net.com/image/info8/450fa587e4314cb7a1a8b1fef1c41cd3.jpg)
![[paper reading] CornerNet_第4张图片](http://img.e-com-net.com/image/info8/aef9bd606f5747b5b767c210f94b3f9e.jpg)
hourglass module对输入的feature map进行5层下采样和上采样,通过skip connection恢复细节信息
Hourglass Module对于细节信息的恢复,和Feature Pyramid Network的思路是一样的
Advantage
Hourglass Network 可以作为 object detention 的理想选择
- 是一个single unified structure
- 可以同时获得 global 和 local 的feature
- 多个hourglass module的堆叠可以提取到higher-level的信息
Improvement & Settings
本文使用2个hourglass module构成hourglass network
改进如下:
-
弃用max pooling,使用stride=2的卷积层来降低feature的分辨率
在实验中,resolution降低5次,对应upsampling也是5次
-
intermediate supervision
类似GoogLeNet到的auxiliary classifier(gradient injection)
Details
-
upsample:
2个residual module,后面再跟nearest neighbor upsampling
-
skip connection:
每个skip connection也包括2个residual module
(注意2个residual module的位置)
-
hourglass module & residual module:
每个hourglass module都有4个通道数为512的residual module
-
pre down-sampling:
- 7 × 7 7×7 7×7 Conv,stride=2,channel=128
- residual block,stride=2,channel=256
-
connection between hourglass modules:
-
对第一个hourglass module的Input和output,都经过一个 1×1 Conv-BN
-
将第1步的结果,进行对应元素的相加,在经过1个256 channel的residual block
-
将第2步的结果,作为第二个hourglass module的输入
-
-
prediction:
仅使用最后一层feature map(不使用Feature Pyramid)
Prediction Module
![[paper reading] CornerNet_第5张图片](http://img.e-com-net.com/image/info8/a65a1942843e45048b0291acaf2e1b1c.jpg)
-
heatmap
对top-left corner和bottom-right corner分别预测一个heatmap ==> 本质是一个binary mask,表明每个location是不是该类的corner
其维度为 H × W × C H×W×C H×W×C KaTeX parse error: Expected '}', got '_' at position 13: (\text{batch_̲size}, 128, 128…,其中 H H H、 W W W 为输入image的size, C C C 为foreground的类别数
heatmap的通道数为foreground的类别数,是因为不需要对background寻找corner(当然分类时还是需要将background作为一类)
==> 用以表示corner的location
可能产生的错误类型:
一堆corner中任何一个的丢失,会导致这个object的丢失(这也是为什么只选择2个corner而不是4个corner来表示object)
-
embedding
对每个检测到的corner预测一个embedding vector
其维度为 H × W × 1 H×W×1 H×W×1 KaTeX parse error: Expected '}', got '_' at position 13: (\text{batch_̲size}, 128, 128…
==> 用以使得同一个object的corner的embedding distance尽可能小(嵌入到子空间的同一位置)
可能产生的错误类型:
错误的embedding,会导致false bounding box
-
offset
对每个corner预测一个offset
其维度为 H × W × 2 H×W×2 H×W×2 KaTeX parse error: Expected '}', got '_' at position 13: (\text{batch_̲size}, 128, 128…
==> 用以调整bounding box的coordinate
可能产生的错误类型:
不准确的offset,会导致松散的bounding box
Corner Pooling
Corner Pooling的输出并不是直接用于heatmap、embedding、offset的预测
-
Introduction:
一种pooling layer,获得corner信息的更好表示
-
Operation:
由于corner都是在object之外,所以无法通过local evidence寻找corner
![[paper reading] CornerNet_第6张图片](http://img.e-com-net.com/image/info8/c90b49bed29a480c91bc417fda459e95.jpg)
所以,采用以下的方式确定corner:
- top-left corner:向左看确定上边界、向上看确定左边界
- bottom-right corner:向右看确定下边界、向下看确定右边界
以top-left为例子,是分别选取2个feature map,分别在2个方向上进行max pooling
(bottom-right pooling仅仅是向量的坐标范围(pooling的方向)不同)
![[paper reading] CornerNet_第7张图片](http://img.e-com-net.com/image/info8/d2811e9f3aec42bfa09994db394a2ccb.jpg)
Overview of Corner Pooling Details of Corner Pooling (gary layer: 3×3 Conv-BN-ReLU) Example of Corner Pooling -
Math Formulation:
公式表述见 [Corner Pooling Math](#Corner Pooling Math)
Key Element
Why CornerNet Better?
-
corner仅仅依赖2个边来确定(而center需要4个边来确定)==> 丢失object的情况会减轻
-
corner pooling 可以encode一些corners的先验知识
-
corners对于box的表示效率高
O ( w h ) O(wh) O(wh) 的corners可以表示 O ( w 2 h 2 ) O(w^2h^2) O(w2h2) 的box
Why Corner Pooling Works
有2点有待于实验验证:
- Corner Pooling的2个输入feature map的区别
- Stacked Hourglass Network的输出feature map到底长啥样
需要注意:corner pooling只是model的一部分,其不负责从image中提取feature map,其**结果也不是直接用于prediction(后续还有处理),**我个人理解为“corner pooling只是获得了对corner的更好的representation”,仅此而已。
总结来说,我认为有3点:
-
Stacked Hourglass Network本质上是一个KeyPoint Estimation Network,进行的是per-pixel的dense prediction,已经能初步获得了corner location的estimation
-
Corner Pooling作为一种pooling操作,实现了pixel信息的空间位置的转移,将Hourglass Network估计的信息汇聚到corner的位置上,获得corner的更好的representation
-
使用2个独立的feature map,降低了2路信号的相关性,使得feature map更专注于单个direction的edge信息,
这是因为一个corner(top-left / bottom-right)必然有2路独立的信息来源
Corner Pooling本质上是对于feature map的一种pooling操作
要理解Corner Pooling的作用,首先要了解feature map的含义
CornerNet的backbone是Stacked Hourglass Network。 Corner Pooling的输入就是Stacked Hourglass Network的输出
Stacked Hourglass Network本质上是一个KeyPoint Estimation Network,进行的是per-pixel的dense prediction
具体来说,我认为Stacked Hourglass Network已经能初步获得了corner location的estimation
换句话说,其每个pixel(location)都具有相对完整的信息,这个单独的pixel理论上就可以拿去做后续的操作了(而不是像Classification一样需要整张图片才能表示完整的信息)
所以说,Corner Pooling是实现了pixel信息的空间位置的转移,获得corner的更好的representation(原文的描述是 “help better locate corners”)
关于Stacked Hourglass Network能在每个pixel上表示什么信息,我认为是可以表示edge(尤其是顶点)的信息的。因为Stacked Hourglass Network本身就是非常复杂且完备的KeyPoint Estimation Network,经过训练我觉得可以表示edge(尤其是顶点)的信息的
此外,corner pooling会使用2个独立的feature map,来分别预测top-most和left-most,类似于2个方向的边缘检测算子的输出。corner的确定必然有2个独立的信息来源!如果使用同一个feature map的话,其最大激活值的位置在corner pooling后依旧还会是最大值,其信息具有很强很强的相关性,corner pooling就失去了意义!
![[paper reading] CornerNet_第8张图片](http://img.e-com-net.com/image/info8/94b905cd1d4d4781a93dcd554be79eab.jpg)
关于“次极大值被抑制”的问题:
以multi-object image来看,如果在Max Pooling的较前位置出现了极大值,会导致较后位置的次极大值被抑制(如下图所示)
但实际中不会出现这样的问题,原因如下:
最终corner的location的确定,是对两个Max Pooling方向的支路的element-wise的相加。换句话说,corner的位置由两个支路的信息确定
当一个支路的corner信息被抑制,另一个支路依旧会独立检测出corner信息,从而共同确定corner的location
为了画图方便,我们对Corner Pooling的两个支路输入相同的feature map(作图有很多不恰当的地方,仅为了说明思路)
![[paper reading] CornerNet_第9张图片](http://img.e-com-net.com/image/info8/d9d5a947713f4b2d995bd971e67c0a0a.jpg)
可以看到水平方向的支路中,左侧object的corner信息被抑制了,而垂直方向的支路正常
将二者相加后:
![[paper reading] CornerNet_第10张图片](http://img.e-com-net.com/image/info8/a9d3107a0b064f7db679fa00e6a72b35.jpg)
可以看到,当水平支路的corner信息被抑制,垂直支路依旧会独立检测出corner信息,从而共同确定corner的location
当然,2个支路的corner极值都被抑制的时候,自然是无法检测到这个corner。
不过鉴于corner所占的位置很小,所以这种事情发生的概率也很小(所以corner pooling 在 small & large area 都是 effective & stable)
Grouping Corners
根据corners的embedding distance对corners进行分组
同一组的corner的embedding distance应该小
Getting Bounding Box
NMS ==> top-100 ==> offset ==> grouping ==> reject ==> score
测试时,根据heatmap、embedding、offset生成bounding box
-
对corner heatmap进行NMS(3×3 max pooling)
-
从corner heatmap中选取top-100的corner
-
根据offset微调corner location
-
计算corners的embedding的L1 distance
-
拒绝两类corner pair:
- distance > 0.5
- corners来自不同的category
-
计算detection score:
对top-left corner和bottom-right corner的score取平均
Data Augmentation
Training
-
horizontal filpping
-
scaling
-
croping
-
color jittering
- brightness(亮度)
- saturation(饱和度)
- constrast(对比度)
Testing
- 保留原始分辨率,补零到511×511(输出维度为128×128)
- original & filpped:
- 汇聚二者的的detection
- soft-nms抑制冗余的detection
- 取top-100的detection
Ablation Experiments
Corner Pooling
corner pooling对于中目标和小目标的提升大

Stability of Corner Pooling over Larger Area
corner pooling 在 small & large area 都是 effective & stable
area范围的由来:
- corner pooling仅作用于 1 4 \frac14 41 圆周(四个象限之一)
- 根据 ( i , j ) (i,j) (i,j) 的不同,area的范围也不同
![[paper reading] CornerNet_第11张图片](http://img.e-com-net.com/image/info8/73bca6e2662f41c68cd117904b05e66a.jpg)
Reducing Penalty to Negative Locations
penalty reduction有效(尤其是对于中目标和大目标)
原因:中目标和大目标对于corner location的要求更低

Hourglass Network Works
有两个结论:
- backbone的选择很重要
- hourglass对CornerNet的性能很重要

Quality of the Bounding Boxes
CornerNet可以产生质量更高的bounding box
衡量标准:bounding box与object的IoU
![[paper reading] CornerNet_第12张图片](http://img.e-com-net.com/image/info8/1f59d36d7c034246a4a4f5896984ca51.jpg)
Error Analysis
结论:
- CornerNet的主要瓶颈是 detecting corners
- detecting corners 和 grouping corners 均有提升空间

Compared to SOTA
![[paper reading] CornerNet_第13张图片](http://img.e-com-net.com/image/info8/a32c5ebcd4094fb6a7c70ab59375f988.jpg)
Math
Loss Function
L = L d e t + α L p u l l + β L p u s h + γ L o f f L = L_{det} + \alpha L_{pull} + \beta L_{push} + \gamma L_{off} L=Ldet+αLpull+βLpush+γLoff
Detection Loss
每个corner只对应一个location的positive,其他location均为negative
由于positive附近的点依旧能产生良好的bounding box,故对positive一定radius内的negative降低惩罚
-
radius的确定
对于不同size的object,要求radius内的一对点,与ground-truth box的IoU要大于阈值(实验中阈值设定为0.3)
-
惩罚的减少量
由unnormalized 2D Gaussian确定
e − x 2 + y 2 2 σ 2 e^{-\frac{x^2+y^2}{2\sigma^2}} e−2σ2x2+y2- 中心为positive location
- σ \sigma σ 为radius的 1 3 \frac13 31
Detection Loss 为 Focal Loss 的变种:
L d e t = − 1 N ∑ c = 1 C ∑ i = 1 H ∑ j = 1 W { ( 1 − p c i j ) α log ( p c i j ) if y c i j = 1 ( 1 − y c i j ) β ( p c i j ) α log ( 1 − p c i j ) otherwise L_{d e t}=\frac{-1}{N} \sum_{c=1}^{C} \sum_{i=1}^{H} \sum_{j=1}^{W}\left\{\begin{array}{cc} \left(1-p_{c i j}\right)^{\alpha} \log \left(p_{c i j}\right) & \text { if } y_{c i j}=1 \\ \left(1-y_{c i j}\right)^{\beta}\left(p_{c i j}\right)^{\alpha} \log \left(1-p_{c i j}\right) & \text { otherwise } \end{array}\right. Ldet=N−1c=1∑Ci=1∑Hj=1∑W{(1−pcij)αlog(pcij)(1−ycij)β(pcij)αlog(1−pcij) if ycij=1 otherwise
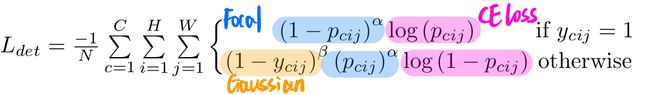
-
y c i j y_{cij} ycij :unnormalized Gaussian 增强的 ground-truth heatmap
( 1 − y c i j ) (1-y_{cij}) (1−ycij) 起到降低惩罚的作用
-
p c i j p_{cij} pcij :heatmap上类别为 c c c 的 ( i , j ) (i,j) (i,j) 位置的score
-
N N N :image中的object的数目
-
α , β \alpha, \beta α,β :两个起调节作用的超参数
Offset Loss
由于降采样,image中 ( x , y ) (x,y) (x,y) 会map到heatmap的 ( ⌊ x n ⌋ , ⌊ y n ⌋ ) (\lfloor \frac x n \rfloor,\lfloor \frac y n \rfloor) (⌊nx⌋,⌊ny⌋) 上
从heatmap去remap到image时会损失一些精确的信息,这会严重影响small bounding box的IoU
所以要通过offset对corner location进行微调
令offset o k \boldsymbol{o}_{k} ok 为:
o k = ( x k n − ⌊ x k n ⌋ , y k n − ⌊ y k n ⌋ ) \boldsymbol{o}_{k}=\left(\frac{x_{k}}{n}-\left\lfloor\frac{x_{k}}{n}\right\rfloor, \frac{y_{k}}{n}-\left\lfloor\frac{y_{k}}{n}\right\rfloor\right) ok=(nxk−⌊nxk⌋,nyk−⌊nyk⌋)
Offset Loss 定义为 o k \boldsymbol{o}_{k} ok 的 smooth L1 Loss
L o f f = 1 N ∑ k = 1 N SmoothL1Loss ( o k , o ^ k ) L_{off} = \frac 1 N \sum_{k=1}^N \text{SmoothL1Loss} (\boldsymbol{o}_{k}, \hat{\boldsymbol{o}}_{k} ) Loff=N1k=1∑NSmoothL1Loss(ok,o^k)
Pull Loss
使得同一组的corner的embedding distance尽可能小(embedding相同),即使得 e t k = e b k = e k e_{t_{k}}=e_{b_k}=e_{k} etk=ebk=ek
L p u l l = 1 N ∑ k = 1 N [ ( e t k − e k ) 2 + ( e b k − e k ) 2 ] L_{p u l l}=\frac{1}{N} \sum_{k=1}^{N}\left[\left(e_{t_{k}}-e_{k}\right)^{2}+\left(e_{b_{k}}-e_{k}\right)^{2}\right] Lpull=N1k=1∑N[(etk−ek)2+(ebk−ek)2]
- e t k e_{t_{k}} etk :top-left corner的embedding
- e b k e_{b_k} ebk :bottom-right corner的embedding
- e k e_{k} ek : e t k e_{t_{k}} etk 和 e b k e_{b_k} ebk 的均值
Push Loss
使得不同组corners的embedding distance尽可能大
![[paper reading] CornerNet_第14张图片](http://img.e-com-net.com/image/info8/fb00ffdc6e0b4d97962c8224a6e3b273.jpg)
- Δ \Delta Δ :实验中设定为1
Pull Loss 和 Push Loss从embedding的角度来看,是使得类内距离小,类间距离大
Corner Pooling Math
t i j = { max ( f t i j , t ( i + 1 ) j ) if i < H f t H j otherwise t_{ij}= \left\{\begin{array}{cc} \text{max} (f_{t_{ij}}, t_{(i+1)j}) & \text { if }i
l i j = { max ( f l i j , t ( i + 1 ) j ) if j < W f t i W otherwise l_{ij}= \left\{\begin{array}{cc} \text{max} (f_{l_{ij}}, t_{(i+1)j}) & \text { if } j
- f t f_t ft 和 f l f_l fl :top-left Corner Pooling的输入feature map
- f t i j f_{t_{ij}} ftij 和 f l i j f_{l_{ij}} flij : f t f_t ft 和 f l f_l fl 在 ( i , j ) (i,j) (i,j) 处的vector
- t i j t_{ij} tij :在 f t f_t ft 的 ( i , j ) (i,j) (i,j) 和 ( i , H ) (i,H) (i,H) 进行max pooling的结果
- l i j l_{ij} lij :在 $f_l $ 的 ( i , j ) (i,j) (i,j) 和 ( W , j ) (W,j) (W,j) 进行max pooling的结果
上面两个式子都是一种递归调用, f t H j f_{t_{Hj}} ftHj 作为 t i j t_{ij} tij 的递归边界, f t i W f_{t_{iW}} ftiW 作为 l i j l_{ij} lij 的递归边界
表明从边界向点 ( i , j ) (i,j) (i,j) 计算max-pooling
Use Yourself
Network Design
网络的基本组件(卷积层、residual block,Inception module等)都可以服务于特定的设计目的,这种思路跟搭积木很像
举几个例子:
Faster-RCNN 的 RPN:
![[paper reading] CornerNet_第15张图片](http://img.e-com-net.com/image/info8/d2417dc5799540f69e16c7758b0cc262.jpg)
RetinaNet的FPN:
![[paper reading] CornerNet_第16张图片](http://img.e-com-net.com/image/info8/882b184bbc2b476bb2c7bd51b46adda0.jpg)
![[paper reading] CornerNet_第17张图片](http://img.e-com-net.com/image/info8/3a4a791698404e8bbbd4b5113d9c1e5e.jpg)
CornerNet 的 prediction module
![[paper reading] CornerNet_第18张图片](http://img.e-com-net.com/image/info8/1442c0362d8e4230ba411b148f6dd790.jpg)
从这3个例子可以看到,网络的设计思路在这里起到了很重要的作用
这是一种自顶向下的设计思路,是确定网络的功能,再通过具体的组件去实现所设计的功能
所以说,“直接套用之前论文中设计好的子网络”是一种错误的想法,真正的正确的思路应该是“从论文中学习设计思路”
甚至从更广义来说,backbone也不是让你拿过来就用的
-
一方面,需要对backbone进行修改,以适应后续的操作
-
另一方面,backbone中蕴含的设计思路,比backbone本身更有意义
Intuition & Interpretability
Interpretability For Delicate Motivation
回顾detection的发展,可以看出其对于网络结构和feature map的可解释性和理解深度的要求是逐渐加深的,只有这样才能设计出更巧妙更精致的方法
从对feature map的理解上看
-
Faster-RCNN:
Faster-RCNN作为two-stage方法,思路是proposal + classification
Faster-RCNN甚至不需要去关注image中的object会对应到feature map的什么位置,因为其在feature map上进行的是 dense & grid 的饱和式采样
这种思路其实是将feature map视作了黑箱
![[paper reading] CornerNet_第19张图片](http://img.e-com-net.com/image/info8/b4fe499f3f004960b1f3b837475c0314.jpg)
-
YOLO v1:
YOLO v1 作为首个one-stage方法,使用regression的方法进行detection
YOLO v1在classification上有segmentation的意味
这使得我们必须要知道,image中的object会对应到feature map的什么位置
这在image和feature map的location relationship上迈出了关键一步
![[paper reading] CornerNet_第20张图片](http://img.e-com-net.com/image/info8/0bef448eca7249ccb1fcc8128a001d89.jpg)
-
SSD:
SSD作为one-stage的方法,使用了multi-scale的feature maps
SDD主要回答了2个问题:
- 使用不同level的feature map进行detection有什么区别?
- 使用多个level的feature map是否会提高detection的性能?
具体来说
-
对于第一个问题:SSD证明了不同level的feature map具有不同的detailed/location information和semantic information,且二者为负相关的关系(即detailed/location information和semantic information难以兼顾)
-
对于第二个问题:SSD进行了feature map的multi-scale,证明了结合不同stage的feature map可以提高detection的性能
SSD其实提出了 Feature Pyramid Network 的雏形。但SSD为了保证feature map的strong semantic,将使用的所有feature map都限制在了low-resolution(即使用backbone的输出作为pyramid的第一层)
SSD真正去关注了feature map到底represent了什么信息,以及其representation能力随stage的变化情况
![[paper reading] CornerNet_第21张图片](http://img.e-com-net.com/image/info8/bb71b97ebfc0486e849cf8716a40f9c7.jpg)
-
RetinaNet:
RetinaNet使用了完整的FPN,不再将feature map限制在low-resolution上,实现了在high-resolution上也能获得strong semantic的feature map
Feature Pyramid Network(high-resolution & strong semantic的feature map的获得)将对于feature map所携带信息的理解更深入了一层
![[paper reading] CornerNet_第22张图片](http://img.e-com-net.com/image/info8/6458d1f07fb844be8898a4fba408b338.jpg)
-
CornerNet:
CornerNet通过在feature map上进行Corner Pooling来获得feature map中包含的Corner信息
CornerNet真正关注了feature map中每个pixel的含义,及其表示的representation,将对feature map的representation的理解深入细化到了pixel-level
其对于feature map的不同位置的信息流动(object位置的信息流动到corner位置),也是一次有意义的尝试
![[paper reading] CornerNet_第23张图片](http://img.e-com-net.com/image/info8/4226f1fef0af415880a8454b5b58551c.jpg)
Anchor-Based or Anchor-Free
-
从feature map的生成来看:
即如何获得high-resolution & strong semantic的feature map
从Faster-RCNN和YOLO的single-scale,到SSD的multi-scale,最后到RetinaNet使用的FPN,基本解决了这个问题
-
从feature map的使用来看:
-
Faster-RCNN、SSD、RetinaNet等方法均为anchor-based,其对于feature map的操作是饱和式检测,对feature map的内在信息的挖掘不足
其对feature map使用的精细度是在整个feature map的level上
-
在anchor-free的方法中:
-
YOLO的分类的思想类似于segmentation,对feature map的使用是patch-level(每个grid cell对应的feature map是最小单位)
-
CornerNet真正开启了在pixel-level上使用feature map的序幕,该方法对feature map中信息的挖掘和利用远远高于anchor-based方法和YOLO
之后的anchor-free方法都可以划分到此类
-
-
Divide Task
要在同一个feature map上实现多个功能,可以采用多个支路分别进行
是否还对信息进行聚合,取决于其使用位置
![[paper reading] CornerNet_第24张图片](http://img.e-com-net.com/image/info8/7d7f1efc7cdc4234a8e50e1b020bf394.jpg)
![[paper reading] CornerNet_第25张图片](http://img.e-com-net.com/image/info8/55517e8254e444b68a3ab42cb6bfc7b1.jpg)
![[paper reading] CornerNet_第26张图片](http://img.e-com-net.com/image/info8/3a171aaa5b724e949eba7a2403e63faa.jpg)
TTA
主要是color jitter 和 horizontal flip
要注意horizontal flip如何聚合检测结果:先聚合,再NMS
Related Work
Two-Stage
two-stage的常规思路是:
- stage-1 生成 sparse set of regions of RoI
- CNN对regions进行分类
R-CNN
使用 low-level vision algorithm 获得RoI,ConvNet进行分类
- 非端到端
- 计算冗余
SPP & Fast-RCNN
从feature map中获取RoI,ConvNet分类
- 依旧是分立的proposal算法,无法端到端训练
Faster RCNN
引入RPN,从anchor中获取proposals
- efficient
- end-to-end
R-FCN
将sub-detection network从fully connected变为fully convolutional
DeNet
不使用anchor的two-stage方法
steps:
- 确定一个location有多大的可能是4个corner之一
- 列出corner所有的组合方式,获得RoI
- CNN对RoI进行分类
difference compared to CornerNet:
- DeNet不判断corner是否属于一个object,而是通过sub-detection network拒绝poor Rois
- DeNet需要进行手动的feature selection
- CornerNet引入了corner pooling层
One-Stage
one-stage的常规思路是:
- 在image上 dense & regular 地放置anchor
- 通过 scoring anchor 来获取最后的 bounding box predictions
- 通过regression对coordinate微调
YOLO
直接在image上预测bounding box和coordinate(后续版本也用回了anchor)
SSD
在multi-scale的feature map上 dense & regular 放置anchor
DSSD & RON
通过skip connection结合low-level和high-level的features(类似Hourglass)
RetinaNet
Focal Loss
RefineDet
滤除一部分的negative box,对anchor进行粗调
Point Linking Network(PLN)
不使用anchor的one-stage方法
steps:
- 预测bounding box的4个corner和1个center的location
- 构造corner-center pair
- 对于corner,预测每个pixel有多大的可能是center
- 对于center,预测每个pixel有多大的可能是corner
- 根据corner-center pair生成bounding box
- 将4个bounding box去merge为1个bounding box
difference compared to CornerNet:
-
PLN通过预测pixel的location来group corner & center
(CornerNet通过embedding vector来group corner & center)
-
CornerNet使用corner pooling,以更好地定位corner
Blogs
-
CornerNet结构的代码:【Anchor free】CornerNet 网络结构深度解析(全网最详细!)
-
CornerNet的ground-truth处理、Loss Function的代码:【Anchor free】CornerNet损失函数深度解析(全网最详细!)
-
Corner Pooling的具体作用:CornerNet算法解读