【书籍】《PyTorch深度学习》——深度学习之计算机视觉
文章目录
- 神经网络简介
- 从零开始构建CNN模型
-
- 卷积
- 池化
- 非线性激活ReLU
- 视图 (view)
- 训练模型
- 狗猫分类问题
- 利用迁移学习对狗猫分类
- 创建和探索VGG16模型
-
- 冻结层
- 微调
- 训练
- 计算预卷积特征
- 理解CNN模型如何学习
- CNN层的可视化权重
神经网络简介
构建图像分类器可分为以下步骤。
- 获取数据
- 创建验证数据集
- 从零开始构建CNN模型
- 训练和验证模型
torchvision变换可以将数据转换成PyTorch张量并进行归一化。
下面的代码负责下载数据、把数据封装成DataLoader以及数据的归一化处理:
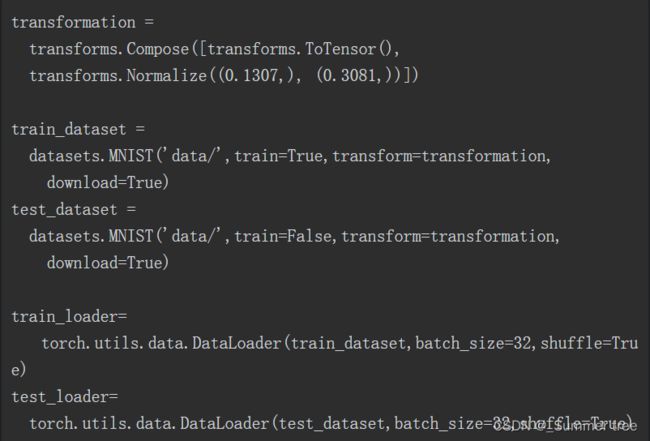
从零开始构建CNN模型
Pytorch实现:
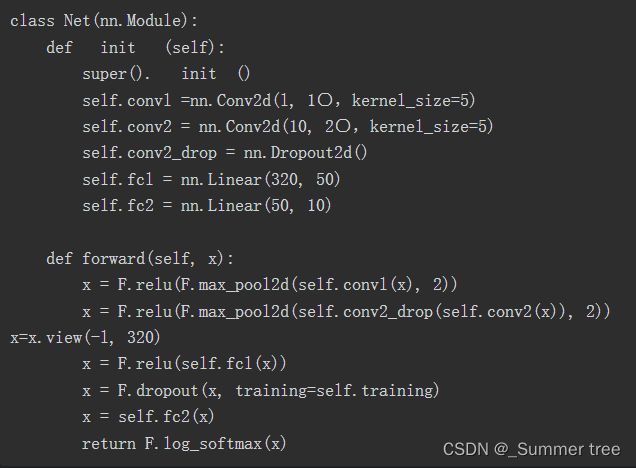
卷积
下图将大小为3的滤波器(或内核)Conv1d应用于长度为7的张量
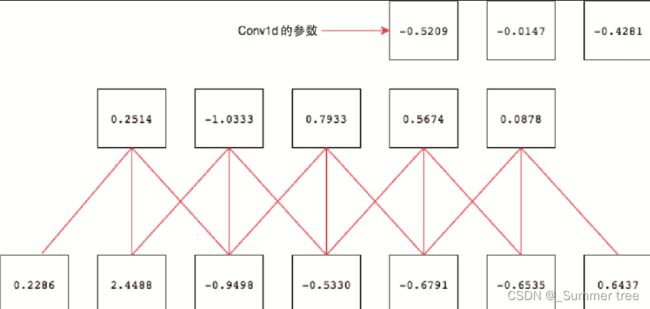
底部框表示7个值的输入张量,连接框表示应用3个卷积滤波器后的输出。在图像的右上角,3个框表示Conv1d层的权重和参数。
滤波器将每次移动2格。下面看看PyTorch的实现

还有另一个重要的参数,称为填充,它通常与卷积一起使用。如果仔细地观察前面的例子,大家可能会意识到,如果直到数据的最后才能应用滤波器,那么当数据没有足够的元素可以跨越时,它就会停止。填充则是通过在张量的两端添加0来防止这种情况。
池化
池化提供两种不同的功能:
- 一个是减小要处理的数据大小
- 另一个是强制算法不关注图像位置的微小变化
它也同样具有内核大小和步幅的概念。
它与卷积不同,因为它没有任何权重,只是对前一层中每个滤波器生成的数据起作用。
如果内核大小为2×2,则它会考虑图像中2×2的区域并选择该区域的最大值。

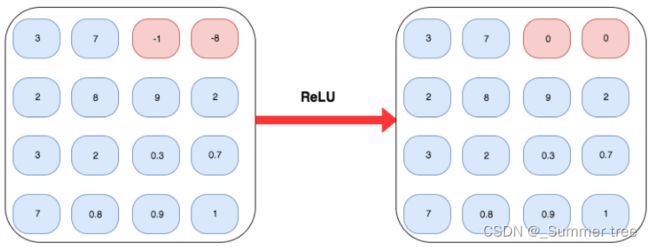
非线性激活ReLU
作用于特征平面的每个元素。
把ReLU应用到应用过最大池化和平均池化的相同特征平面上
视图 (view)
我们使用一个以数字矩阵作为输入并输出另一个数字矩阵的二维卷积。为了应用线性层,需要将矩阵扁平化,将二维张量转变为一维的向量。 (x.view(-1, 320)
view方法将使n维张量扁平化为一维张量, -1 指示着需要扁平化的维度。
在将数据从二维张量转换为一维张量之后,把数据传入非线性层,然后传入非线性的激活层。
训练模型
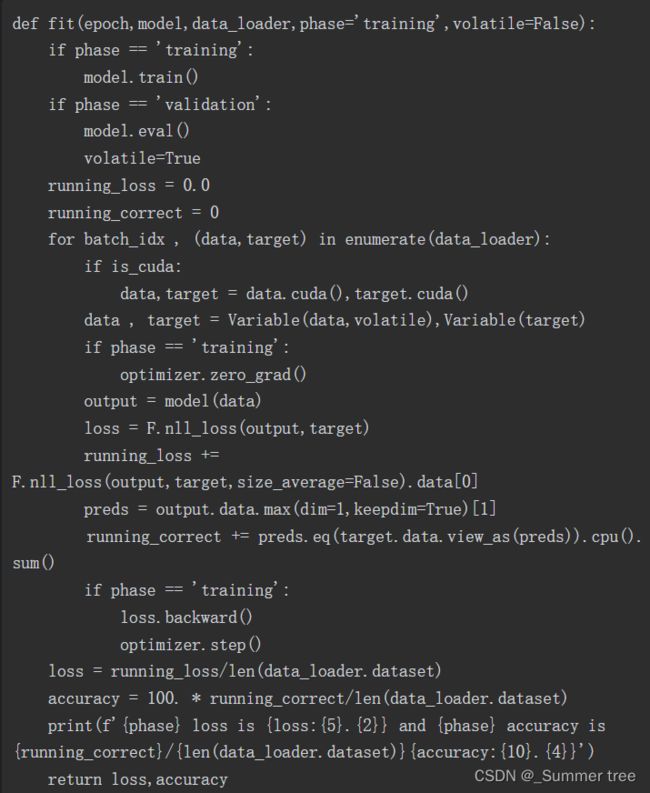
该方法针对training和validation具有不同的逻辑。使用不同模式主要有两个原因:
- 在training模式中,dropout会删除一定百分比的值,这在验证或测试阶段不应发生
- 对于training模式,计算梯度并改变模型的参数值,但是在测试或验证阶段不需要反向传播。
对于training模式,计算梯度并改变模型的参数值,但是在测试或验证阶段不需要反向传播。
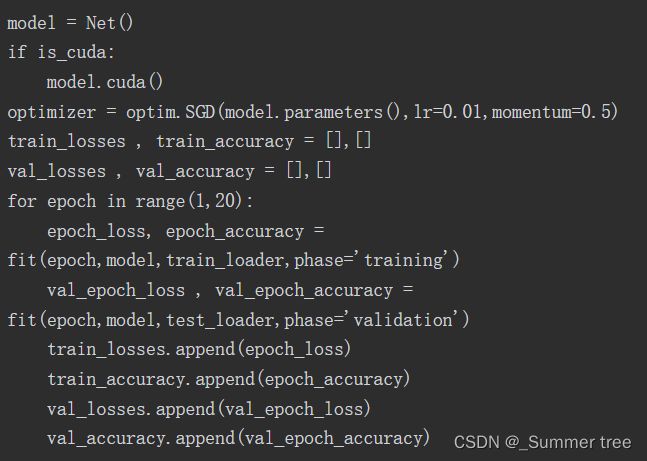
狗猫分类问题

利用迁移学习对狗猫分类
迁移学习是指在类似的数据集上使用训练好的算法,而无须从头开始训练。
大多数流行的算法都在流行的ImageNet数据集上进行了预训练,以识别1,000种不同的类别。这样的预训练模型具有可以识别多种模式的调整好的滤波器权重。
我们将研究一种名为VGG16的算法,它是在ImageNet竞赛中获得成功的最早的算法之一。虽然有更多的现代算法,但该算法仍然很受欢迎,因为它简单易懂并可用于迁移学习。
VGG16模型的架构:
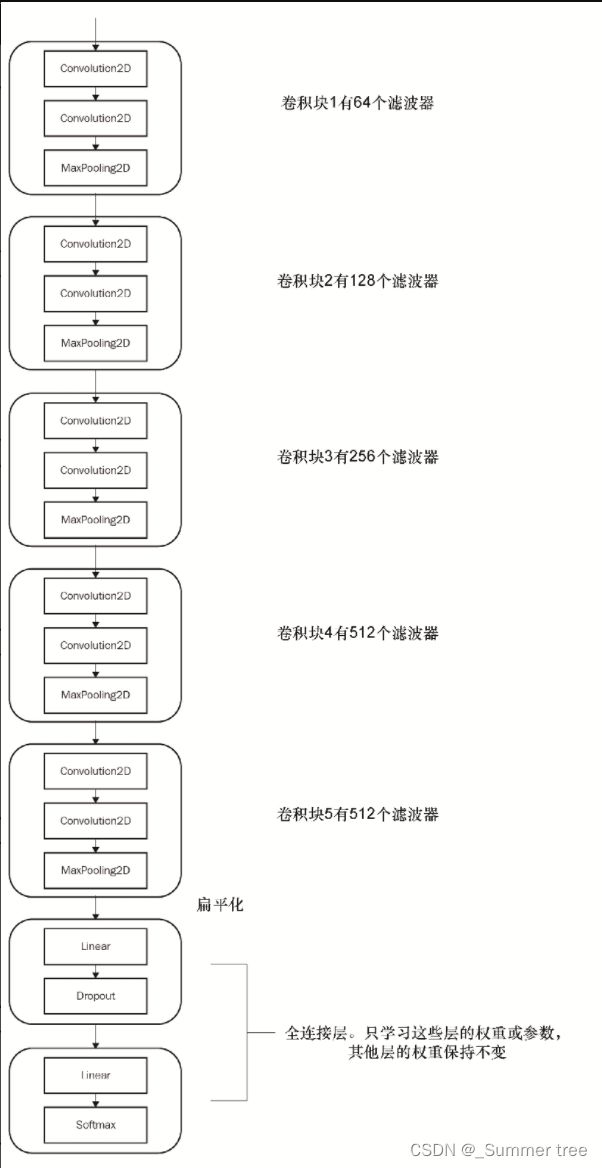
- VGG16架构包含5个VGG块。
- 每个VGG块是一组卷积层、一个非线性激活函数和一个最大池化函数。
- 所有算法参数都是调整好的,可以达到识别1,000个类别的最先进的结果。
- 该算法以批量的形式获取输入数据,这些数据通过ImageNet数据集的均值和标准差进行归一化。
- 在迁移学习中,我们尝试通过冻结架构的大部分层的学习参数来捕获算法的学习内容。
- 通用实践是仅微调网络的最后几层。
创建和探索VGG16模型
加载预训练好的模型:

冻结层
冻结层中的权重将阻止更新这些卷积块的权重。由于模型的权重被训练用来识别许多重要的特征,因而我们的算法从第一个迭代开时就具有了这样的能力。使用最初为不同用例训练的模型权重的能力,被称为迁移学习。
![]()
微调
VGG16模型被训练为针对1000个类别进行分类,但没有训练为针对狗和猫进行分类。因此,需要将最后一层的输出特征从1000改为2。
vgg.classifier可以访问序列模型中的所有层,第6个元素将包含最后一个层。当训练VGG16模型时,只需要训练分类器参数。因此,我们只将classifier.parameters传入优化器,如下所示:

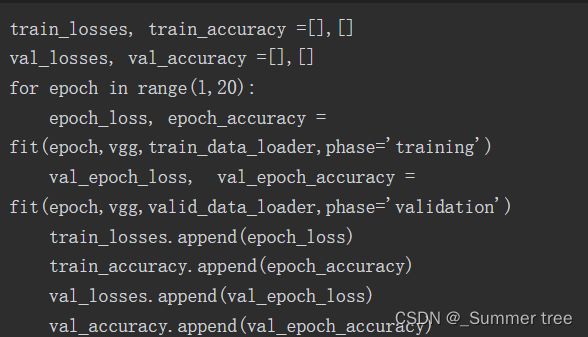
训练
当训练模型时,只有分类器内的参数会发生变化。下面的代码片段对模型进行了20轮的训练,在验证集上达到了98.45%的准确率:
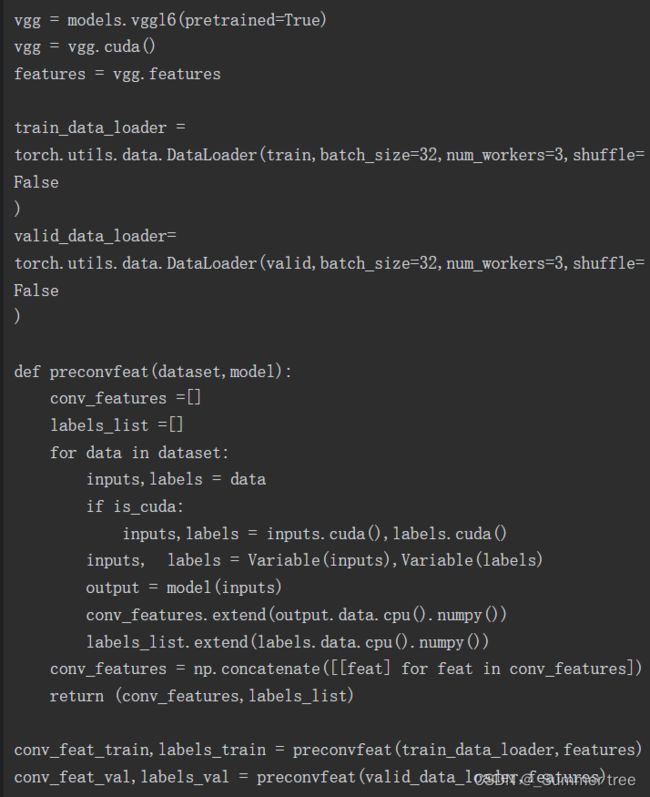
计算预卷积特征
我们将卷积块(在示例中为vgg.features块)视为具有了已学习好的权重且在训练期间不会更改的函数。因此,计算卷积特征并保存下来将有助于我们提高训练速度。训练模型的时间减少了,因为我们只计算一次这些特征而不是每轮都计算。

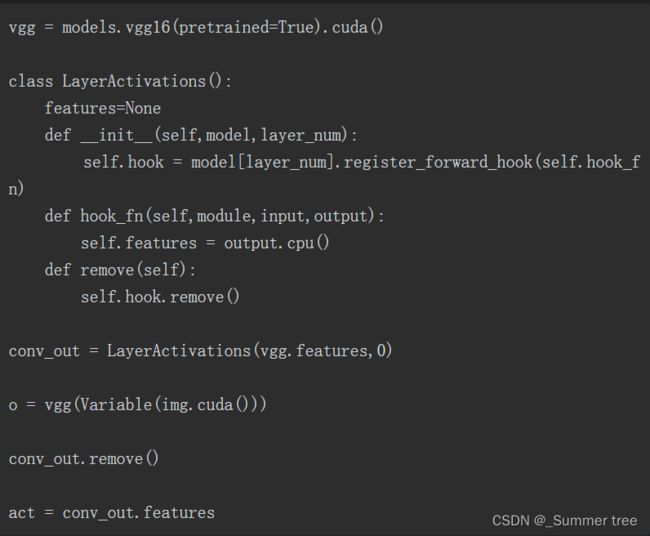
理解CNN模型如何学习
可视化中间层的输出将有助于我们理解输入图像如何在不同层之间进行转换。通常,每层的输出称为激活(activation)
PyTorch提供了一个名为register_forward_hook的方法,它允许传入一个可以提取特定层输出的函数。
CNN层的可视化权重
获取特定层的模型权重非常简单。可以通过state_dict函数访问所有模型权重。
