我又一次跳进GPU并行的坑:Cuda编程的经验分享
最近在做一个点云Registration的项目,需要用到并行计算。之前做点云简化的时候尝试过Cuda编程,由于数据量较大时,从内存往显存做数据传输比较费时,后来就放弃了。现在做的这个项目没有那么大的数据量,并且算法本身非常适合做并行,所以打算重新把Cuda编程拾起来。不拾不知道,一拾吓一跳,调试过程中遇到各种错误,各种奇奇怪怪的问题。花了两三天的时间才勉强把程序调好。辛苦不能白费,我决定在这篇博客中记录下调试时遇到的一些问题,方便以后做Cuda编程时,能够避开一些坑,同时也作为一个经验分享,帮助那些想要做Cuda并行的同学,作为一个参考。
1. 环境配置
关于Cuda的环境配置,包括包含文件与库的链接,资料很多,这里我不再赘述了。需要注意的一点是,当你把配置链接都调整好了以后,.cu文件仍然是无法编译的。大概率,你没有引入生成依赖项,即将.cu文件如何编译做指定。具体的配置方法如下:
项目-》生成依赖项-》点选Cuda。这样,你就实现了对cu文件编译的指定。


检查下cu文件是否已经实现了编译指定:新建一个.cu文件,右击-》属性-》通用-》项目类型,如果显示的是CUDA C/C++, 说明已经完成了指定。
2. 显存分配
在之前的一篇博文中(CUDA编程之vector的存储分配与使用),我已经介绍过了如何使用Cuda实现显存分配并传入相应的数据。这里的数据传入是比较传统的,要按照输入的类型,非常严格的按照尺度开辟空间,按照顺序传入数据。作为一个Cuda编程新手来说,这里的显存分配与数据传入是一个即繁琐,又非常容易出错的步骤。只要一个位置的数据出现错误,那么整个的数据段会全错,造成数据读取错误。因此,对于Cuda的显存分配,要非常认真,避免出现错误。这里,我给出两个例子,展示如何将Vector的数据(当然,如果你使用的是动态数组,也可以参考这个方法)传入GPU现存:
一维的Vector:
vector pt_para;//原始的vector
float* pt_para_Cu;//存放显存地址的指针
//cudaMalloc,按照pt_para的类型,大小,分配一个显存空间
cudaMalloc((void**)&pt_para_Cu, sizeof(float) * pt_para.size());
//cudaMemcpy,将数据按照地址,从Host传到Device,可以理解为从内存传到显存
cudaMemcpy(pt_para_Cu, &pt_para[0], sizeof(float) * pt_para.size(), udaMemcpyHostToDevice); 二维的Vector:
vector> ps
float** ps_2d = new float* [ps.size()];
float** ps_2d_Cu;
for (int i = 0; i < ps.size(); i++) {
std::vector boxList_1_i = ps[i];
float* dev_1d;
cudaMalloc((void**)&dev_1d, sizeof(float) * boxList_1_i.size());
cudaMemcpy(dev_1d, &boxList_1_i[0], sizeof(float) * boxList_1_i.size(), cudaMemcpyHostToDevice);
ps_2d[i] = dev_1d;
}
cudaMalloc((void**)&ps_2d_Cu, sizeof(float*) * ps.size());
cudaMemcpy(ps_2d_Cu, ps_2d, sizeof(float*) * ps.size(), cudaMemcpyHostToDevice); 二维的Vector比一维的就麻烦多了,首先,需要按照一维Vector的传输方法,将二维的Vector分解为一组一维的Vector,按照一维的Vector显存开辟方法实现显存开辟与传输,并记录所有的显存地址。最后,再定义一个二维的指针数组,把所有之前记录的所有显存地址,再传输给二维的指针数组,这样就实现了二维Vector到显存的数据传输。
当你需要传输给显存各种不同的数据时,难免会出现错误,包括显存一出,类型匹配问题等。实践中,我都会在开辟显存空间的时候,加一段检查代码,以验证显存开辟是否成功,具体可以查看我的另外一篇博客:CUDA异常处理篇——invalid argument 的解决方法。
3. 数据回传
数据回传与显存分配正好是相匹配的。当我们做完GPU并行计算之后,我们需要将数据从显存传会内存。这里我们只要指定好显存的起始地址,以及读取的数据类型以及长度,就可以将数据传回。使用的函数也是cudaMemcpy,只是最后一个参数,是从Device传到了Host,代码如下:
float* loadResult = new float[pt_para.size()];
cudaMemcpy(loadResult, pt_para_Cu, sizeof(float) * pt_para.size(), udaMemcpyDeviceToHost);二维数据的回传会更容易一点,因为我们知道二维显存指针存在哪里,只要一个一个的取出来,然后按照一维数据回传的方式载入到内存就可以了。
4. Thread限制
通常,基于不同的GPU,对应的Thread是存在限制的。我简单查了一下,一般是1024。
cudaProgram<< > >();
cudaError_t error = cudaGetLastError();
printf("CUDA error: %s\n", cudaGetErrorString(error)); 这里,我设置threadNum为2048,会报错:
CUDA error: invalid configuration argument
block数在硬件上也是存在界限的,但是如果指定的block数超过界限,我的理解是Cuda会自动安排不同的执行次序,以解决block越界的问题。但是Thread的数量是有明确的约束的。
这里其实涉及到了更底层的并行计算问题。包括了在一个block内执行的Thread共享数据以及执行效率的问题。这已经超过了我粗浅的GPU编程经验了。有兴趣的同学可以看Cuda的官方示例代码,了解更深层次的Cuda并行编程技术。
还有一个问题是我实际遇到,但是又百思不得其解的谜之过程。即在我首先指定了blockNum和threadNum进行编译时,数据回传是错的。我甚至检查了__global__函数内部的代码,确定了代码没有问题。之后,我把blockNum和threadNum设置为两个较小的数字,如2和3,执行后,发觉数据回传没有问题了。然后,我再把blockNum和threadNum改回原来的数字,结果神奇的事情发生了,数据回传就没有问题了!这让我百思不得其解。一个猜测是,在程序初始执行显存数据回传的时候,可能因为一些异常情况,导致大规模的并行数据回传出现问题。Cuda一个比较蛋疼的地方就是,只要有一个小地方出问题,那么整个执行就会崩溃。改成使用少量的并行,数据回传的通路得到初始化,之前的异常情况被刷新,然后再恢复成原来的代码,就一切正常了。
如果你的代码已经再__global__得到验证,并且再回传之前没有任何错误,回传时出现错误,不妨用我说的方法试一试。
5. Bool类型异常
如果你将bool类型数据传入到__global__函数进行执行,有可能会出现问题。我不知道是不是因为bool类型在解析的时候,Cuda与C++有什么不统一的地方。至少在我的项目中,bool类型的数据会出现异常。因此,我建议使用int型来代替bool类型。
6. 调试
在GPU执行的代码,最麻烦的就是调试。首先,不能单步调试。和CPU不同,GPU执行的代码是没办法单步调试的。如果出现问题,你需要在程序实行完后,才能知道错误有没有发生以及可能发生在哪里。其次,需要考虑到并行。再做任何的调试输出你都要考虑到,在GPU执行的代码,都是要同时执行很多次的。如果你在输出的时候不做任何的限制,结果就是会输出一大堆的内容,导致你没法从输出信息中看到问题。最后,输出的结果是在执行完后,第一次数据回传完成的时候,才能看到。因此,当你每一次调试,希望看到__global__函数内部的执行情况,你都要等GPU并行执行完,才能看到结果。示例如下:
__global__ void cudaBlock(){
const int tid = threadIdx.x + blockDim.x * blockIdx.x;
if (tid == 1000) {
printf("tid:%d\n", tid);
}
...
}
extern "C" void cudaPipeline(){
...
voxelCudaBlock << > >();
cudaError_t error = cudaGetLastError();
printf("CUDA error: %s\n", cudaGetErrorString(error));
//load data from GPU mamory
printf("transfer data from device to host.\n");
float* loadResult = new float[sizeUnit];
cudaMemcpy(loadResult, resultMatching_Cu, sizeof(float) * sizeUnit,
cudaMemcpyDeviceToHost);
printf("loadResult loaded.\n");
} 执行结果为:
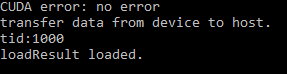
可以看到,tid:1000这条调试结果,是在回传到loadResult时,输出的。可以理解为,调试结果是当cudaMemcpy调用时,自动的打印出来的。如果你想看下代码在GPU的执行情况,你需要了解这个过程。
综合以上三点,想要做好GPU并行代码调试,真的比想象中的麻烦。因此,你需要在代码编写的时候,尽可能的在CPU中验证好,然后再写并行程序。