人脸识别0-05:insightFace-损失函数arcface-史上最全
以下链接是个人关于insightFace所有见解,如有错误欢迎大家指出,我会第一时间纠正,如有兴趣可以加微信:17575010159 相互讨论技术。
人脸识别0-00:insightFace目录:https://blog.csdn.net/weixin_43013761/article/details/99646731:
这是本人项目的源码:https://github.com/944284742/1.FaceRecognition
其中script目录下的文件为本人编写,主要用于适应自己的项目,可以查看该目录下的redeme文件。
softmax到arcface
在讲解arcface loss之前,我们必须去看一下softmax家族发展的历史,这里就直接贴出链接了,大家去看即可:
softmax变种或增强1:Large-Margin Softmax Loss for Convolutional Neural Networks
softmax增强: A-SoftMax. SphereFace: Deep Hypersphere Embedding for Face Recognition
论文阅读之Arcface:https://blog.csdn.net/Wuzebiao2016/article/details/81839452
ArcFace算法笔记:https://blog.csdn.net/u014380165/article/details/80645489
人脸识别-arcface损失函数:看了前面的,再看这篇,通俗易解。
自我理解
大家看了上面的之后,应该思路也比较清晰了。在这里我也讲解一下自己的理解。如果我们要了解arcface,那么肯定需要了解一下该算法的发展,演变过程,
首先我们来看看
sofrmax loss
这是传统的的Softmax公式, W x T x i W_x^Tx_i WxTxi+ b j b_j bj代表的是全链接的输出,通过计算会得到每个类别的概率。而这种方式主要考虑是否能够正确的分类,缺乏类内和类间距的约束。在[A Discriminative Feature Learning Approach for Deep Face Recognition]这篇文章中,作者使用了一个比LeNet更深的网络结构,用Mnist做了一个小实验来证明Softmax学习到的特征与理想状态下的差距:
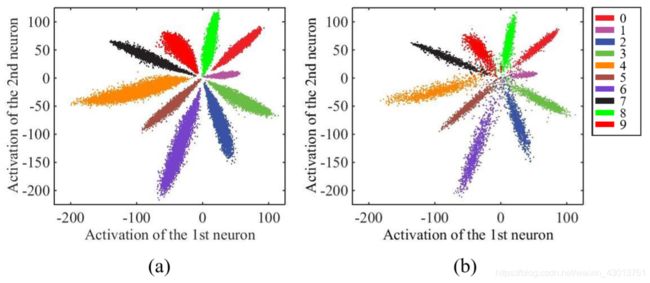
实验结果表明,传统的Softmax仍存在着很大的类内距离,也就是说,通过对损失函数增加类内距离的约束,能达到比更新现有网络结构更加事半功倍的效果。于是,[A Discriminative Feature Learning Approach for Deep Face Recognition]的作者提出了Center Loss,并从不同角度对结果的提升做了论证。
下面是直接的理解:

N是样本的数量,i代表第i个样本,j代表第j个类别,fyi代表着第i个样本所属的类别的分数
fyi是全连接层的输出,代表着每一个类别的分数,
![]()
每一个分数即为权重W和特征向量X的内积
![]()
每个样本的softmax值即为:
L-softmax loss
假设一个2分类问题,x属于类别1,那么原来的softmax肯定是希望:
W 1 T x > W 2 T x W^T_1x > W^T_2x W1Tx>W2Tx
也就是属于类别1的概率大于类别2的概率,这个式子和下式是等效的:
∣ ∣ W 1 ∣ ∣ ∣ ∣ x ∣ ∣ c o s ( θ 1 ) > ∣ ∣ W 2 ∣ ∣ ∣ ∣ x ∣ ∣ c o s ( θ 2 ) ||W1|| ||x||cos(θ _1) > ||W2|| ||x||cos(θ _2) ∣∣W1∣∣∣∣x∣∣cos(θ1)>∣∣W2∣∣∣∣x∣∣cos(θ2)
large margin softmax就是将上面不等式替换为:
∣ ∣ W 1 ∣ ∣ ∣ ∣ x ∣ ∣ c o s ( m θ 1 ) > ∣ ∣ W 2 ∣ ∣ ∣ ∣ x ∣ ∣ c o s ( θ 2 ) ( 0 < θ 1 < p i = 3.14 m ) ||W1|| ||x||cos(mθ _1) > ||W2|| ||x||cos(θ _2)(0<θ _1<\frac{pi=3.14}{m}) ∣∣W1∣∣∣∣x∣∣cos(mθ1)>∣∣W2∣∣∣∣x∣∣cos(θ2)(0<θ1<mpi=3.14)
m是正整数,cos函数在0到π范围又是单调递减的,所以cos(mx)要小于cos(x)。通过这种方式定义损失会逼得模型学到类间距离更大的,类内距离更小的特征。
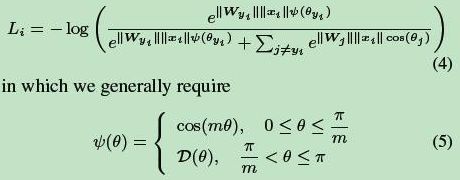
从几何的角度看两种损失的差别:

设置为cos(mx)后,使得学习到的W参数更加的扁平,可以加大样本的类间距离。
Large-Margin Softmax的实验效果:

Center Loss
Center Loss的整体思想是希望一个batch中每个样本的feature你feature的中心的距离的平方和要越小越好,也就是类内距离越小越好。作者提出,最终的损失函数包含softmax loss和center loss,用参数λ来控制二者的比重,如下面公式所示:
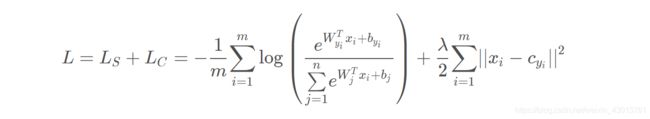
因而,加入了Softmax Loss对正确类别分类的考虑以及Center Loss对类内距离紧凑的考虑,总的损失函数在分类结果上有很好的表现力。以下是作者继上个实验后使用新的损失函数并调节不同的参数λ \lambdaλ得到的实验结果,可以看到,加入了Center Loss后增加了对类内距离的约束,使得同个类直接的样本的类内特征距离变得紧凑。

A-softmax loss
A-softmax loss简单讲就是在large margin softmax loss的基础上添加了两个限制条件||W||=1和b=0,使得预测仅取决于W和x之间的角度。
softmax的计算:
W i T x + b i W^T_ix + b_i WiTx+bi可以改写成 ∣ ∣ W 1 ∣ ∣ ∣ ∣ x ∣ ∣ c o s ( θ i ) + b i ||W1|| ||x||cos(θ _i)+b_i ∣∣W1∣∣∣∣x∣∣cos(θi)+bi
若引入两个限制条件,
∣ ∣ W 1 ∣ ∣ = ∣ ∣ W 2 ∣ ∣ = 1 ||W1|| = ||W2|| = 1 ∣∣W1∣∣=∣∣W2∣∣=1
以及
b 1 = b 2 = 0 b_1=b_2=0 b1=b2=0
decision boundary变为:
∣ ∣ x ∣ ∣ ( c o s θ 1 − c o s θ 2 ) = 0 ||x||(cosθ_1 - cosθ_2) = 0 ∣∣x∣∣(cosθ1−cosθ2)=0,只取决于角度了
则损失函数变为:
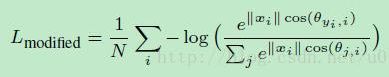
在这两个限制条件的基础上,作者又添加了和large margin softmax loss一样的角度参数,使得公式变为:
AM-softmax
在A-softmax的基础上,修改Cos(mθ)为一个新函数:
![]()
与ASoftmax中定的的类似,可以达到减小对应标签项的概率,增大损失的效果,因此对同一类的聚合更有帮助
然后根据Normface,对f进行归一化,乘上缩放系数s,最终的损失函数变为:

这样做的好处在于A-Softmax的倍角计算是要通过倍角公式,反向传播时不方便求导,而只减m反向传播时导数不用变化
Asoftmax是用m乘以θ,而AMSoftmax是用cosθ减去m,这是两者的最大不同之处:一个是角度距离,一个是余弦距离。
之所以选择cosθ-m而不是cos(θ-m),这是因为我们从网络中得到的是W和f的内积,如果要优化cos(θ-m)那么会涉及到arccos操作,计算量过大。
arcface

分类正确label的值为
![]() ,
,
cos函数在(0,1)内是单调递减少的,加上m,会使该值变得更小,从而loss会变得很大。这样修改的原因:角度距离比余弦距离在对角度的影响更加直接
源码分析
现在已经对softmax到arcface的发展史,有了大致的了解。下面看代码recognition/train.py(注意:fc7输出的就是角度θ):
def get_symbol(args):
# 获得一个特征向量
embedding = eval(config.net_name).get_symbol()
# 定义一个标签的占位符,用来存放标签
all_label = mx.symbol.Variable('softmax_label')
gt_label = all_label
is_softmax = True
# 如果损失函数为softmax
if config.loss_name == 'softmax':
# 定义一个全连接层的权重,使用全局池化代替全链接层
_weight = mx.symbol.Variable("fc7_weight", shape=(config.num_classes, config.emb_size),
lr_mult=config.fc7_lr_mult, wd_mult=config.fc7_wd_mult, init=mx.init.Normal(0.01))
# 如果不设置bias,使用全局池化代替全链接层,得到每个id的概率值
if config.fc7_no_bias:
fc7 = mx.sym.FullyConnected(data=embedding, weight=_weight, no_bias=True, num_hidden=config.num_classes,
name='fc7')
# 如果设置_bias,使用全局池化代替全链接层,得到每个id的cos_t
else:
_bias = mx.symbol.Variable('fc7_bias', lr_mult=2.0, wd_mult=0.0)
fc7 = mx.sym.FullyConnected(data=embedding, weight=_weight, bias=_bias, num_hidden=config.num_classes,
name='fc7')
# 如果损失函数为margin_softmax
elif config.loss_name == 'margin_softmax':
# 定义一个全连接层的权重,使用全局池化代替全链接层
_weight = mx.symbol.Variable("fc7_weight", shape=(config.num_classes, config.emb_size),
lr_mult=config.fc7_lr_mult, wd_mult=config.fc7_wd_mult, init=mx.init.Normal(0.01))
# 获得loss中m的缩放系数
s = config.loss_s
# 先进行L2正则化,然后进行全链接
_weight = mx.symbol.L2Normalization(_weight, mode='instance')
nembedding = mx.symbol.L2Normalization(embedding, mode='instance', name='fc1n') * s
#使用全局池化代替全链接层,得到每个id的角度*64
fc7 = mx.sym.FullyConnected(data=nembedding, weight=_weight, no_bias=True, num_hidden=config.num_classes,
name='fc7')
in_shape,out_shape,uax_shape = fc7.infer_shape(data = (2,3,112,112))
print('fc7',out_shape)
# 其存在m1,m2,m3是为了把算法整合在一起,
# arcface cosface combined
if config.loss_m1 != 1.0 or config.loss_m2 != 0.0 or config.loss_m3 != 0.0:
# cosface loss
if config.loss_m1 == 1.0 and config.loss_m2 == 0.0:
s_m = s * config.loss_m3
gt_one_hot = mx.sym.one_hot(gt_label, depth=config.num_classes, on_value=s_m, off_value=0.0)
fc7 = fc7 - gt_one_hot
# arcface combined
else:
# fc7每一行找出gt_label对应的值,即 角度*s
zy = mx.sym.pick(fc7, gt_label, axis=1)
in_shape,out_shape,uax_shape = zy.infer_shape(data = (2,3,112,112),softmax_label = (2,))
print('zy', out_shape)
# 进行复原,前面乘以了s,cos_t为-1到1之间
cos_t = zy / s
# t为0-3.14之间
# 该arccos是为了让后续的cos单调递增
t = mx.sym.arccos(cos_t)
# m1 sphereface
if config.loss_m1 != 1.0:
t = t * config.loss_m1
# arcface或者combined
if config.loss_m2 > 0.0:
t = t + config.loss_m2
# t为0-3.14之间,单调递增
body = mx.sym.cos(t)
# combined 或者 arcface
if config.loss_m3 > 0.0:
body = body - config.loss_m3
new_zy = body * s
# 得到差值
diff = new_zy - zy
# 扩展一个维度
diff = mx.sym.expand_dims(diff, 1)
# 把标签转化为one_hot编码
gt_one_hot = mx.sym.one_hot(gt_label, depth=config.num_classes, on_value=1.0, off_value=0.0)
# 进行更新
body = mx.sym.broadcast_mul(gt_one_hot, diff)
fc7 = fc7 + body
# 如果损失函数为triplet
elif config.loss_name.find('triplet') >= 0:
is_softmax = False
nembedding = mx.symbol.L2Normalization(embedding, mode='instance', name='fc1n')
anchor = mx.symbol.slice_axis(nembedding, axis=0, begin=0, end=args.per_batch_size // 3)
positive = mx.symbol.slice_axis(nembedding, axis=0, begin=args.per_batch_size // 3,
end=2 * args.per_batch_size // 3)
negative = mx.symbol.slice_axis(nembedding, axis=0, begin=2 * args.per_batch_size // 3, end=args.per_batch_size)
if config.loss_name == 'triplet':
ap = anchor - positive
an = anchor - negative
ap = ap * ap
an = an * an
ap = mx.symbol.sum(ap, axis=1, keepdims=1) # (T,1)
an = mx.symbol.sum(an, axis=1, keepdims=1) # (T,1)
triplet_loss = mx.symbol.Activation(data=(ap - an + config.triplet_alpha), act_type='relu')
triplet_loss = mx.symbol.mean(triplet_loss)
else:
ap = anchor * positive
an = anchor * negative
ap = mx.symbol.sum(ap, axis=1, keepdims=1) # (T,1)
an = mx.symbol.sum(an, axis=1, keepdims=1) # (T,1)
ap = mx.sym.arccos(ap)
an = mx.sym.arccos(an)
triplet_loss = mx.symbol.Activation(data=(ap - an + config.triplet_alpha), act_type='relu')
triplet_loss = mx.symbol.mean(triplet_loss)
triplet_loss = mx.symbol.MakeLoss(triplet_loss)
out_list = [mx.symbol.BlockGrad(embedding)]
# 如果使用了softmax
if is_softmax:
softmax = mx.symbol.SoftmaxOutput(data=fc7, label=gt_label, name='softmax', normalization='valid')
out_list.append(softmax)
if config.ce_loss:
# ce_loss = mx.symbol.softmax_cross_entropy(data=fc7, label = gt_label, name='ce_loss')/args.per_batch_size
body = mx.symbol.SoftmaxActivation(data=fc7)
body = mx.symbol.log(body)
_label = mx.sym.one_hot(gt_label, depth=config.num_classes, on_value=-1.0, off_value=0.0)
body = body * _label
ce_loss = mx.symbol.sum(body) / args.per_batch_size
out_list.append(mx.symbol.BlockGrad(ce_loss))
# 如果是triplet
else:
out_list.append(mx.sym.BlockGrad(gt_label))
out_list.append(triplet_loss)
# 聚集所有的符号
out = mx.symbol.Group(out_list)
return out
好了,这次就分析到此为止了