算法 6:集成学习与随机森林
欢迎来到机器学习的世界
博客主页:卿云阁欢迎关注点赞收藏⭐️留言
本文由卿云阁原创!
本阶段属于练气阶段,希望各位仙友顺利完成突破
首发时间:2021年5月8日
✉️希望可以和大家一起完成进阶之路!
作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
一、概述
二. 算法说明
三、随机森林
四、详细说明

一、集成学习
1.1个体与集体
概念:
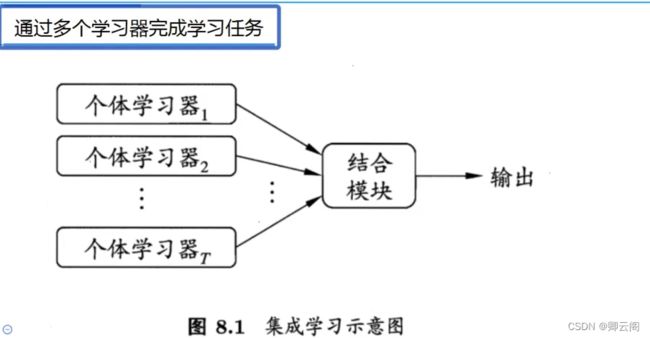
通过多个学习器完成学习任务
集成学习将多个学习器进行结合,通常可获得更优越的泛化性能。可简记为(好而不同)
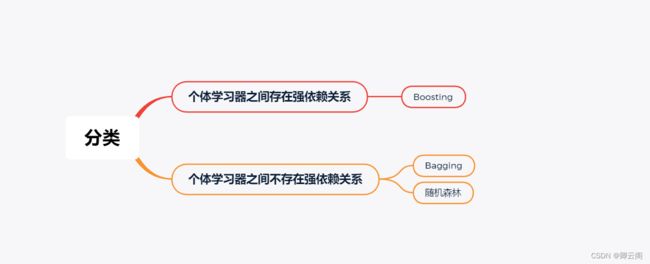
分类
集成学习的优点
1.2Boosting
Boosting算法最有名的代表是AdaBoost
通过每次降低个体学习器的分类误差,加大效果好的个体学习器的重要性,得到最终的集成学习器。
集成学习器的形式:
下面例子和方法翻译自知乎
手把手教你AdaBoost - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/27126737
例 给定如下表所示训练数据。假设个体学习器由x(输入)和y(输出)产生,其阈值v(判定正反例的分界线)使该分类器在训练数据集上分类误差率最低。(y=1为正例,y=-1为反例)
第一个个体学习器:
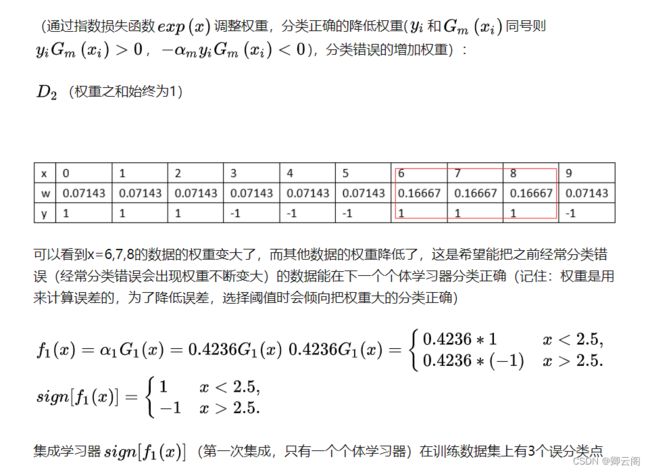
我们首先认为(i=1,2,…,10)的权重是一样的,即每一个数据同等重要。(权重是用来计算误差的)

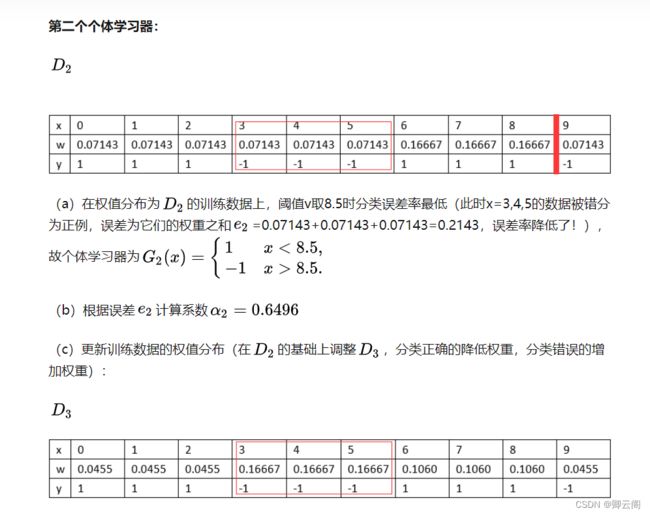


通过上面的例子,我们可以发现,其本质就是提高错误训练样本的权重。
adaboost算法的举例
sklearn类库中的Adaboost应用:
参数:
(1)base_estimator:即弱分类学习器理论上可以选择任何一个分类器,不过需要支持样本权重。我们常用的一般是CART决策树或者神经网络MLP。默认是决策树,即AdaBoostClassifier默认使用CART分类树DecisionTreeClassifier,而AdaBoostRegressor默认使用CART回归树DecisionTreeRegressor。
(2)algorithm:这个参数只有在AdaBoostClassifier中有。主要原因是scikit-learn实现了两种Adaboost分类算法,SAMME和SAMME.R。两者的主要区别是弱分类器权重的度量。SAMME使用了样本集分类效果作为弱分类器的权重,即误差率得到的权重;而SAMME.R使用了对样本集分类的预测概率大小作为权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值是SAMME.R。但是注意的是使用了SAMME.R后,弱分类器参数base_estimator必须限制使用支持概率预测的分类器。而SAMME算法则没有这个限制。
(3)n_estimators:两者都有,就是我们弱分类器的最大迭代次数,或者最大的弱学习器的个数。一般来说n_eatimators太小,容易欠拟合,太大又容易过拟合,默认是50.在实际调参过程中,我们常常将n_eatimators和learning_rate一起考虑。
(4)learning_rate:两者都有,即每个弱学习器的权重缩减系数。
主要方法:
(1)fit(x,y): 从训练集中创建一个提升分类器
(2)get_params():得到模型的参数
(3)predict(x):预测
(4)score(x,y):验证集上验证算法的精度
from sklearn.ensemble import AdaBoostClassifier from sklearn.datasets import load_iris from sklearn import model_selection from sklearn.tree import DecisionTreeClassifier #import matplotlib.pyplot as plt iris = load_iris() x_train,x_test,y_train,y_test = model_selection.train_test_split(iris.data, iris.target,test_size=0.2,random_state=0) abc = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,min_samples_split=20, min_samples_leaf=5), n_estimators=100) abc.fit(x_train,y_train) abc.score(x_test,y_test)0.9666666666666667GBDT(梯度提升树)
推导
梯度提升树(GBDT)原理小结 - 刘建平Pinard - 博客园 (cnblogs.com)
通过加法模型,以及不断减少训练过程产生的残差,对残差进行拟合。
训练过程
训练一个模型m1,产生错误e1,针对e1产生第二个模型,产生错误e2,针对e2产生第二个模型,产生错误e3,最终预测的结果是m1+m2+m3.
在sklearn中梯度提升回归树有四种可选择的损失函数
'ls:平方损失’
'ld:绝对损失’
'huber:huber损失’
'quantile:分位数损失’
在sklearn中梯度提升分类树有两种可选择的损失函数
'exponential:指数损失’
'deviance:对数损失’
举例
import numpy as np from sklearn.ensemble import GradientBoostingClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score ''' 调参: loss:损失函数。有deviance和exponential两种。deviance是采用对数似然,exponential是指数损失,后者相当于AdaBoost。 n_estimators:最大弱学习器个数,默认是100,调参时要注意过拟合或欠拟合,一般和learning_rate一起考虑。 learning_rate:步长,即每个弱学习器的权重缩减系数,默认为0.1,取值范围0-1,当取值为1时,相当于权重不缩减。较小的learning_rate相当于更多的迭代次数。 subsample:子采样,默认为1,取值范围(0,1],当取值为1时,相当于没有采样。小于1时,即进行采样,按比例采样得到的样本去构建弱学习器。这样做可以防止过拟合,但是值不能太低,会造成高方差。 init:初始化弱学习器。不使用的话就是第一轮迭代构建的弱学习器.如果没有先验的话就可以不用管 由于GBDT使用CART回归决策树。以下参数用于调优弱学习器,主要都是为了防止过拟合 max_feature:树分裂时考虑的最大特征数,默认为None,也就是考虑所有特征。可以取值有:log2,auto,sqrt max_depth:CART最大深度,默认为None min_sample_split:划分节点时需要保留的样本数。当某节点的样本数小于某个值时,就当做叶子节点,不允许再分裂。默认是2 min_sample_leaf:叶子节点最少样本数。如果某个叶子节点数量少于某个值,会同它的兄弟节点一起被剪枝。默认是1 min_weight_fraction_leaf:叶子节点最小的样本权重和。如果小于某个值,会同它的兄弟节点一起被剪枝。一般用于权重变化的样本。默认是0 min_leaf_nodes:最大叶子节点数 ''' gbdt = GradientBoostingClassifier(loss='deviance', learning_rate=1, n_estimators=5, subsample=1 , min_samples_split=2, min_samples_leaf=1, max_depth=2 , init=None, random_state=None, max_features=None , verbose=0, max_leaf_nodes=None, warm_start=False ) iris = load_iris() x_train,x_test,y_train,y_test = model_selection.train_test_split(iris.data, iris.target,test_size=0.2,random_state=0) gbdt.fit(x_train,y_train) y_pred= gbdt.predict(x_test) accuracy_score(y_pred, y_test) # 评估1.0一、概述
随机森林 ( random forest )是将多个模型综合起来创建更高性能模型的方法,既可用于回归, 也可用于分类。同样的算法有梯度提升(gradient boosting )等在机器学习竞赛中很受欢迎的算法。 通过学习随机森林,我们可以学到在其他算法中也适用的基础知识。随机森林的目标是利用多个决策树模型,获得比单个决策树更高的预测精度。单个决策树的性 能并不一定很高,但是多个决策树汇总起来,一定能创建出泛化能力更强的模型。 随机森林既可用于回归,也可用于分类,这里以分类问题为例进行说明。图 2-30 是随机森林分类算法的示意图。该算法从每个决策树收集输出,通过多数表决得到最终的分类结果。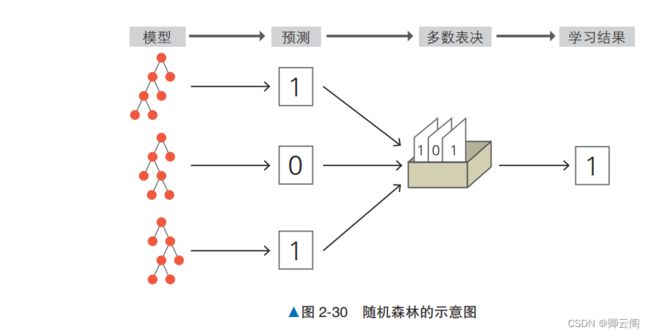
随机森林的多数表决就像找别人商量事情一样,不只听一个人的意见,而是在听取许多人的意 见之后综合判断。机器学习也一样,通过创建多个模型,采取多数表决的方式,可以期待获得更为 妥当的结果。
需要注意的是,如果使用同样的学习方法创建决策树,那么输出的就都是同样的东西,也就失去了采取多数表决的意义。在随机森林中,采用的决策树要具备多样性,这一点很重要。下面的 “算法说明”部分将介绍决策树的算法,以及随机森林如何使决策树具有多样性。
三、 随机森林算法说明
随机森林是综合决策树的结果的算法。本节先介绍决策树的基本内容,再介绍如何综合决策树 的结果。决策树决策树是通过将训练数据按条件分支进行划分来解决分类问题的方法,在分割时利用了表示数据杂乱程度(或者不均衡程度)的不纯度的数值。决策树为了使表示数据杂乱程度的不纯度变小, 对数据进行分割。当分割出来的组中存在很多相同的标签时,不纯度会变小;反之,当分割出来的 组中存在很多不同的标签时,不纯度会变大。表示不纯度的具体指标有很多种,本节利用基尼系数。基尼系数的计算式如下: 图 2-31 所示为使用几种不同的分割方法计算得出的加权平均基尼系数。左侧是分割前的状态,这时 的基尼系数为 0.5 。中间是分割后求出的基尼系数的平均值。使用分割出的每个部分的基尼系数乘以该部 分所含数据的数量所占的比例,得到加权平均值。右侧是使基尼系数的平均值最小的分割方法的例子。
图 2-31 所示为使用几种不同的分割方法计算得出的加权平均基尼系数。左侧是分割前的状态,这时 的基尼系数为 0.5 。中间是分割后求出的基尼系数的平均值。使用分割出的每个部分的基尼系数乘以该部 分所含数据的数量所占的比例,得到加权平均值。右侧是使基尼系数的平均值最小的分割方法的例子。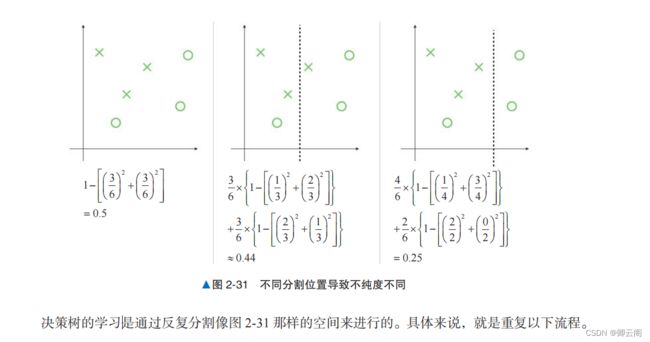
四、随机森林

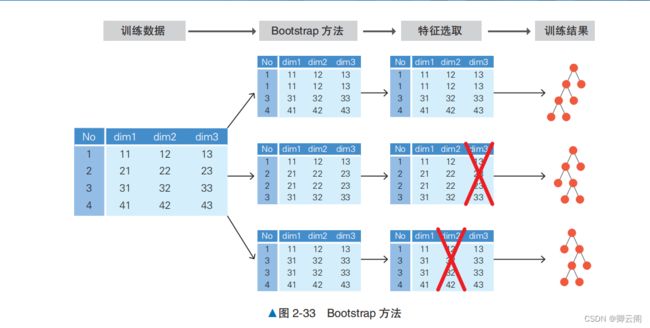 随机森林利用这种方式创建多棵数据集、训练多棵决策树、对预测结果进行多数表决,返回最 终的分类结果。
随机森林利用这种方式创建多棵数据集、训练多棵决策树、对预测结果进行多数表决,返回最 终的分类结果。
五、详细说明
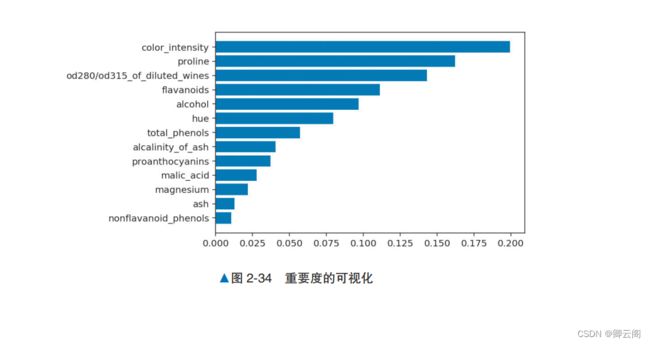
让我们用随机森林基于 3 种葡萄酒的各种测量值数据,对葡萄酒进行分类。from sklearn.datasets import load_wine from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 读取数据 data = load_wine() X_train, X_test, y_train, y_test = train_test_split( data.data, data.target, test_size=0.3) model = RandomForestClassifier() model.fit(X_train, y_train) # 训练 y_pred = model.predict(X_test) accuracy_score(y_pred, y_test) # 评估0.9629629629629629可视化特征随机森林可以让我们知道每个特征对预测结果的重要度。下面我们先了解一下特征重要度的计算方法,然后以葡萄酒分类为例,看一下各特征的重要度。首先介绍一下使用随机森林计算重要 度的方法。前面讲过,每棵决策树的学习方法都是通过沿着某个值分割特征,使不纯度尽可能地 小。通过对随机森林的所有决策树求在以某个特征分割时的不纯度并取平均值,可以得到特征的重 要度。将重要度高的特征用于分割,有望大幅度减小不纯度。反之,重要度低的特征即使被用于分割,也无法减小不纯度,所以可以说这样的特征是非必要的。基于特征的重要度,我们可以去除非必要的特征。 接下来,我们以葡萄酒分类为例,看一下特征的重要度。图 2-34 所示为使用随机森林算出的 特征重要度。 图中重要度高的特征 color_intensity 表示色泽,这说明它对葡萄酒的分类非常重要, 这个结论直观,让人信服。