替代 Elasticsearch,TDengine 助力四维图新将存储空间利用率提升 8 倍
小 T 导读:面对海量的车载轨迹数据,四维图新数据存储面对非常大的压力——每分钟的轨迹数据大概有 2000 万条记录,他们此前使用的 Elasticsearch 存储方式不仅造成了严重的物理资源浪费,还存在查询瓶颈,所以急需转换数据存储中间件。本文讲述了四维图新在数据库选型测试、搭建与迁移等方面的相关实践经验。
企业简介
四维图新成立于 2002 年,是中国导航地图产业的开拓者。经十余年的创新发展,其已成为导航地图、导航软件、动态交通信息、位置大数据以及乘用车和商用车定制化车联网解决方案领域的领导者。如今,四维图新以全面的技术发展战略迎接汽车“新四化”时代的来临,致力于以高精度地图、高精度定位、云服务平台以及应用于 ADAS 和自动驾驶的车规级芯片等核心业务,打造“智能汽车大脑”,赋能智慧出行,助力美好生活,成为中国市场乃至全球更值得客户信赖的智能出行科技公司。
项目介绍
在某车企项目中,面对车载轨迹数据 2000 万/分钟的写入量,整体数据存储的压力非常之大。此前我们采用的是 Elasticsearch,共设置了 15 个节点( 32 核 / 48GB 内存 / 2TB 磁盘空间),不到半个月磁盘占用量就已经达到 80% 了,非常耗用物理资源。同时大量的 IO 操作不仅导致 PaaS 层不稳定,也波及到了其他的依赖资源,如云主机、中间件等。在此背景下,转换数据存储中间件已经迫在眉睫。
从数据特点和处理需求出发,我们选择了更加专业的时序数据库。从数据插入、查询、存储性能提升,硬件或云服务成本降低、设计架构简化和集群版本开源这四个维度进行选型考虑,最终我们初步选择了 TDengine Database,随即便着手进行模拟测试。
一、选型测试
针对时序数据库 TDengine 的写入性能优势,我们选取了一些业务场景接入的轨迹数据进行写入测试,测试环境如下图所示:
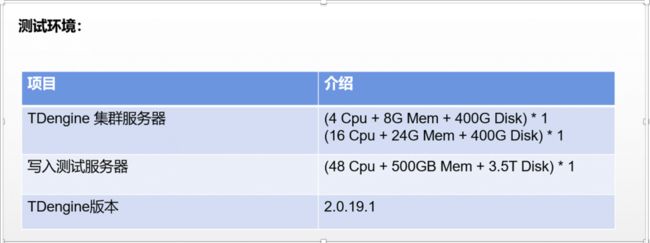
我们以 40 万记录/天/辆车,共计 150 天、120 辆车的数据进行写入测试,写入的记录总数为 72 亿,总线程数为 40,最终的写入和存储性能对比如下图:

总结:相比 Elasticsearch,TDengine 的存储空间利用率提升8倍,写入性能提升 2.5 倍。
因为之前 blocks 只有默认的值,所以在后续测试中我们按照业务实际场景修改成了 100,将每 Vnode 写入缓存块数做了适当的优化。
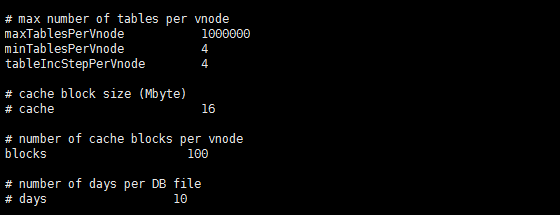
之后我们从单日数据、单辆车数据、单日单车数据三个维度对 TDengine 进行查询测试,测试结果如下图所示:

总结:相比 Elasticsearch,TDengine 的“count(*)”查询性能提升 4 倍,“select*”查询性能提升 3-10 倍。
此外,TDengine 支持查询单个设备一个时间段数据的需求,和我们的业务场景不谋而合;它的类 SQL 设计也非常便利,几乎不需要学习成本,运维管理成本也几乎为零。同时,它还是国产开源数据库,相比其他开源软件,能给中国的软件工程师提供更好的本地服务。作为一款完全自主研发的时序数据库,TDengine 的稳定性和安全性也已经被很多企业验证过,相对已经比较成熟了。
经过多重测试和考量,最终我们选择将 TDengine 接入到系统之中,以支撑当下的业务需求。
二、实际运行
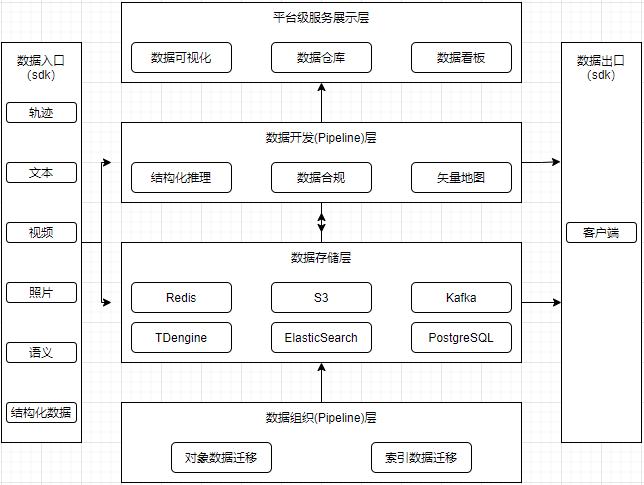
在接入 TDengine 之后,业务上近实时的写入大量轨迹数据的需求轻松实现,数据部门可以日更亿级轨迹数据,在达成存储要求的同时,查询性能也能满足下游的业务团队使用。整体架构图如下:
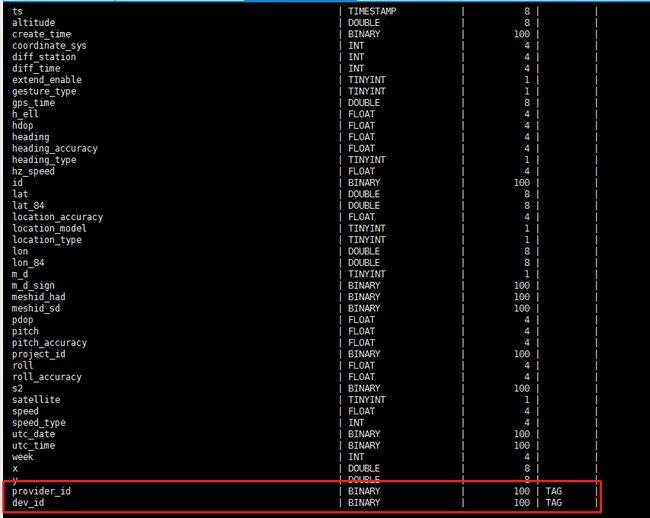
在表结构的搭建上,我们是按照设备和众包车的编码设置的 tag,建立了如下所示的索引关系。
而具体到实际业务中,TDengine 仍然表现出上述测试所展现出的优秀性能。以存储性能为例,之前我们使用 ES集群时,15个节点只能支持3个月的数据存储,在接入 TDengine 之后,7 个同样配置的集群,已经支撑了 5 个月的数据存储。
三、经验分享
实际上,在数据迁移工作中,我们的本地业务从 Elasticsearch 迁移到 TDengine 的过程并不复杂。一是由于 TDengine 支持的编程语言非常多,且是采用与 MySQL 相似的 SQL 语言,这种特性极大地简化了迁移所需的资源成本和人力成本。此外,通过我们自研的传输工具,300T+ 数据的迁移工作在短时间内就完成了 。
在具体实现上,传输工具是采用多线程方式将数据读取到 CSV,然后再批量写入到新的集群中,示例代码如下图所示:
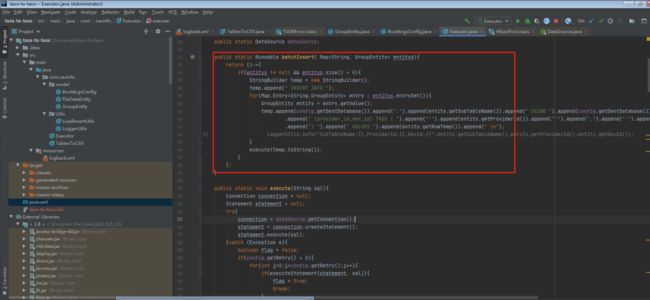
除此之外,在 TDengine 的应用上,我们也遇到了一些小问题,在涛思数据伙伴们的通力合作下,最终问题也都得到了解决。借此机会将这些经验分享出来,给大家一些参考。
我们有一个场景是“在页面上画一个矩形框”,刚开始我们是直接使用经纬度进行轨迹点数据的获取,所需的时间非常长,基本没法使用,代码如下所示:

在优化之后,我们使用 Spark 程序动态去请求,通过经纬度获取某类型车的轨迹点个数,通过划取时间点的方式,达到了最终的效果:
![]()
在后期使用 TDengine 进行多维度、大数据量查询的时候,出现了查询性能线性下降的问题,后面我们通过查询官网资料,再对比本地的集群配置参数以及数据建模方式,最终找到了性能问题的原因,而后结合本地应用场景以及未来业务规模进行了重新配置和数据建模,成功解决了查询性能的问题。
所以,如果大家在应用 TDengine 的过程中出现了一些问题,建议可以先去官网查找资料,官网文档非常全面,可以称得上是 TDengine 使用的“百科全书”了,一些小问题都可以在这里找到解决办法。
四、写在最后
基于 TDengine Database在当下业务中所表现出的优异成绩,我们在未来考虑向 TDengine 中接入更大规模的轨迹数据以及其他业务中的时序数据。也希望未来我们能借力 TDengine,实现大量的轨迹计算及挖掘,将公司内部的数据实现快速变现,加速充电桩业务的发展,依赖 LBS 帮助客户挖掘更多的潜在客户,实现多边共赢。
作者简介
曹志强,四维图新位置服务部门数据平台负责人,主要负责解决整个集团的数据接入、存储、查询和使用,支撑公司内部自动驾驶和智慧城市的数据治理工作。
想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。
