1. python中创建新的csv文件
(1). 使用csv.writer()创建:
代码如下:
import csv
headers = ['学号','姓名','分数']
rows = [('202001','张三','98'),
('202002','李四','95'),
('202003','王五','92')]
with open('score.csv','w',encoding='utf8',newline='') as f :
writer = csv.writer(f)
writer.writerow(headers)
writer.writerows(rows)
会在相同路径下生成一个score.csv文件
VScode中打开如下:

用excel打开如下:
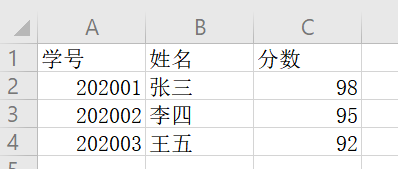
可以发现,逗号','在csv文件中代表换格。除此以外,还有'\n'在csv文件中代表换行。
(2). 使用csv.Dictwriter()创建:
代码如下:
import csv
headers = ['学号','姓名','分数']
rows = [{'学号':'202001','姓名':'张三','分数':'98'},
{'学号':'202002','姓名':'李四','分数':'95'},
{'学号':'202003','姓名':'王五','分数':'92'}]
with open('score.csv','w',encoding='utf8',newline='') as f :
writer = csv.DictWriter(f,headers)
writer.writeheader()
writer.writerows(rows)
会发现结果和方式1相同。
(3). 使用writelines()创建:
import csv
headers = ['学号,姓名,分数','\n']
csv = ['202001,张三,98','\n',
'202002,李四,95','\n',
'202003,王五,92']
with open('score.csv', 'w',encoding='utf8',newline='') as f:
f.writelines(headers) # write() argument must be str, not tuple
f.writelines(csv)
会发现结果和方式1、方式2相同。
综合上述三种方式,csv文件的创建灵活多样,主要依赖于自己创建的原来数据的存放形式,比如方式1、2中的rows和方式3中的csv,以此选择适合的创建csv文件的函数和方式。
实际示例(要灵活使用','、'\n'、append()等):
csv = []
for line in lines:
scores = result[line[0]]
for wav, scores in scores.items():
# csv.append(line[0])
# csv.append(wav)
# csv.append(str(i) for i in scores)
# csv.append('\n')
#csv.append(','.join([wav] + [str(i) for i in scores] + '\n'))
csv.append(line[0] +','+ wav )
for i in scores:
csv.append(','+ str(i))
csv.append('\n')
with open('task3-result.csv', 'w') as f:
f.writelines(csv)
2. python中读取csv文件
原score.csv文件在excel中打开如下:

(1). 使用pandas.read_csv()读取
代码如下:
import pandas as pd
my_matrix = pd.read_csv('score.csv')#,header=None,index_col=None)
'''
header : int or list of ints, default ‘infer',指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0,
index_col : int or sequence or False, default None,用作行索引的列编号或者列名
'''
print(my_matrix)
print(my_matrix.shape)
此时的输出结果为:

若代码参数改为:
my_matrix = pd.read_csv('score.csv',header=None,index_col=None)
结果如下:
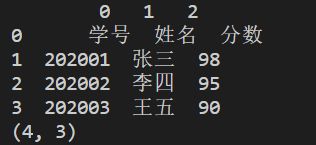
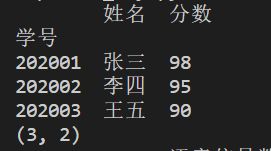
若代码参数改为:
my_matrix = pd.read_csv('score.csv',header=0,index_col=0)
结果如下:
为了方便后续分析,可以将数据类型改为np.array型,代码如下:
import pandas as pd
import numpy as np
my_matrix = pd.read_csv('score.csv')#,header=0,index_col=0)
my_matrix = np.array(my_matrix)
print(my_matrix)
print(my_matrix.shape)
print(my_matrix[0][0])
结果如下:

(2). 使用csv.reader()进行读取
代码如下:
import csv
#读取csv文件
with open('score.csv', "r",encoding='utf8',newline='') as f:
reader = csv.reader(f)
for row in reader:
print(row)
结果如下:

如果想获取某一列,可以通过指定的列标号来查询,代码如下:
for row in reader:
print(row[0])
可以输出某一指定的列 ,结果如下:
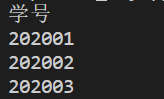
(3). 使用csv.DictReader()进行读取
代码如下:
import csv
#读取csv文件
with open('score.csv', "r",encoding='utf8',newline='') as f:
reader = csv.DictReader(f)
for row in reader:
print(row)
结果如下:

如果想获取某一列,可以通过指定的标题来查询,代码如下:
for row in reader: print(row['学号'])
可以输出指定的某一列,结果如下:
总结
到此这篇关于python中csv文件创建、读取及修改等操作的文章就介绍到这了,更多相关python csv文件创建读取及修改内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!