《大数据概论》自学报告第二章
第二章 理论基础
2.1 数据科学的学科地位
 数据科学正是三大知识领域的重叠之处
数据科学正是三大知识领域的重叠之处
2.1.1数学与统计知识
“数学与统计知识“”是数据学科主要理论基础之一。但是,数据科学与(传统)数学和统计学区别的,主要体现在以下四个方面。
1.数据科学中的“数据”并不仅仅是“数值”,也不等同于“数值”。
2.数据科学中的“计算”并不仅仅是加减乘除等”数学计算“,还包括数据的查询、挖掘、洞见、分析、可视化等更多类型。
3.数据科学关注的不是“单一学科”的问题,超出了数学、统计学、计算机科学等单一学科的研究范畴,进而涉及多个学科(统计学、计算机科学等)的研究范畴,他强调的是跨学科视角。
4.数据科学并不仅仅是“理论研究”,也不是纯“领域实务知识”,他关注和强调的是两者的结合。
2.1.2黑客精神与技能
“黑客精神与技能”是数据科学家的主要精神追求和技能要求——大胆创新、喜欢挑战、追求完美和不断改进
黑客(Hacker):喜欢发现和解决技术挑战、攻击计算机网络系统的精通计算机技能的人
骇客(Cracker):闯入计算机系统和网络试图破坏和偷窃个人信息的个体
显然这里的黑客不同于外界的认知,这里的黑客精神是指热衷挑战、崇尚自由、主张信息共享和大胆创新的精神,与常人理解不同的是,黑客遵守道德规则和行为规范。
下面是道德准则的词条解释

2.1.3领域实务知识
“领域实务知识”是对数据科学家的特殊要求,具有显著的面向领域性。如我们想为电商公司提供可行的商品销售趋势预测,那么我也需要具备相关商品营销的知识。对于各领域的应用总结起来就是大数据技术+领域实务知识=应用数学科学
2.1.4小结
总之,数据科学不是一个以特定理论为基础发展起来的,而是包括数学与统计学、计算机科学技术、数据工程和知识工程、也定学科领域的理论在内的多个理论相互融合后形成的新兴学科。
通常,把数据科学的理论基础进一步具体化为四个方面:
1.统计学
2.机器学习
3.数据可视化
4.(某一)领域实务知识与经验。
2.2 统计学
2.2.1统计学与数据科学
统计学是数据科学的主要理论基础之一。
数据科学的理论、方法,技术和工具往往来源于统计学,实际上,第一篇以“数据科学(Data Science)”为标题的学术期刊论文及时由统计学家W.S.Cleveland完成的
2.2.2数据科学中常用的统计学知识
行为目的与思维方式角度
描述统计:采用图标或数学方法描述数据的统计特征
推断统计:在数据科学中,有时需要通过“样本”对“总体”进行推断分析。常用的推断方法有两种:参数估计和假设检验。如下图所示:
参数估计和假设检验的区别
方法论角度
从方法论角度看,基于统计的数据分析方法又可分为两个不同的层次——基本分析方法和元分析方法,如下图所示:
基本分析法:
相关链接:八大基本分析法
元分析法:
2.2.3数据科学视角下的统计学
随着理论研究与实践需求的发展,尤其是大数据的出现,统计学的研究不断面临着新的视角和研究课题,其研究范围和研究方法也在不断地被挑战和更新。V.Mayer-Schönberger和K.Cukier在其著名论著Big data中就提出了大数据时代统计的思维变革
- 不是随机样本,而是全体数据
- 不是精确性,而是混杂性
- 不是因果关系,而是相关关系
2.2.4统计学与机器学习的区别和联系
统计学和机器学习之间的界定一直很模糊。
无论是业界还是学界一直认为机器学习只是统计学批了一层光鲜的外衣。
而机器学习支撑的人工智能也被称为“统计学的外延。对此常见的说法有:
"机器学习和统计的主要区别在于它们的目的。机器学习模型旨在使最准确的预测成为可能。统计模型是为推断变量之间的关系而设计的。
统计学和机器学习到底有什么区别?
2.3 机器学习
2.3.1机器学习与数据科学
主要议题:如何实现和优化机器的自我学习
大概含义和基本思路就是:以现有的部分数据(称为训练集)为学习素材(输入),通过特定的学习方法(机器学习算法),让机器学习到(输出)能够处理更多或未来数据的新能力(称为目标函数)。在多数情况下人们很难找到目标函数的精确定义,所以,通常采用函数逼近算法进行估计目标函数。概念图如下:
同时别忘记机器学习的重要三要素:T P E
对应用例子解释就是
2.3.2数据科学中常用的机器学习知识
常见类型
其中书上重点介绍了KNN(K近邻)算法
KNN(K- Nearest Neighbor),即K最邻近算法,是数据挖掘分类技术中最简单的方法之一。简单来说,它是根据“最邻近”这一特征来对样本进行分类。
这里不做详细介绍,相关链接:KNN算法
同时补充KNN算法中用到的一些相似性度量方法:常用相似性(距离)度量方法概述
这里重点介绍下增强学习
机器学习算法大致可以分为三种:
1. 监督学习(如回归,分类)
2. 非监督学习(如聚类,降维)
3. 增强学习
那什么是增强学习捏?来看定义
增强学习(reinforcementlearning, RL)又叫做强化学习,是近年来机器学习和智能控制领域的主要方法之一。
也就是说增强学习关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。
通过增强学习,一个智能体应该知道在什么状态下应该采取什么行为。RL是从环境状态到动作的映射的学习,我们把这个映射称为策略。
具体说用模型来表达,我们使用奖惩机制来训练agents。Agent做出正确的行为会得到奖励,做出错误的行为就会受到惩罚。这样的话,agent就会试着将自己的错误行为最少化,将自己的正确行为最多化。
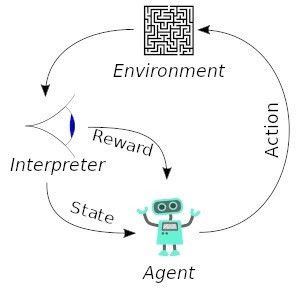
来看些实例应用
游戏中的应用
flappy bird 是现在很流行的一款小游戏

如果说想让小鸟自行进行游戏,但是我们却没有小鸟的动力学模型,也不打算了解它的动力学。要怎么做呢?
那么就可以给它设计一个增强学习算法,然后让小鸟不断的进行游戏,如果小鸟撞到柱子了,那就获得-1的回报,否则获得0回报。通过这样的若干次训练,我们最终可以得到一只飞行技能高超的小鸟,它知道在什么情况下采取什么动作来躲避柱子。
无人驾驶中的应用
比如,自动停车策略能够完成自动停车。变道能够使用q-learning来实现,超车能应用超车学习策略来完成超车的同时躲避障碍并且此后保持一个稳定得速度。
AWS DeepRacer是一款设计用来测试强化学习算法在实际轨道中的变现的自动驾驶赛车。它能使用摄像头来可视化赛道,并且可以使用强化学习模型来控制油门和方向。

Wayve.ai已经成功应用了强化学习来训练一辆车如何在白天驾驶。他们使用了深度强化学习算法来处理车道跟随任务的问题。他们的网络结构是一个有4个卷积层和3个全连接层的深层神经网络。例子如图。中间的图像表示驾驶员视角。

强化学习在机器人控制中的应用
通过深度学习和强化学习方法训练机器人,可以使其能够抓取各种物体,甚至是训练中未出现过的物体。因此,可将其用于装配线上产品的制造。
上述想法是通过结合大规模分布式优化和QT-Opt(一种深度Q-Learning变体)实现的。其中,QT-Opt支持连续动作空间操作,这使其可以很好处理机器人问题。在实践中,先离线训练模型,然后在真实的机器人上进行部署和微调。
针对抓取任务,谷歌AI用了4个月时间,使用7个机器人运行了800机器人时。

实验表明,在700次实验中,QT-Opt方法有96%的概率成功抓取陌生的物体,而之前的方法仅有78%的成功率。
增强学习在各领域都有很大的应用前景
2.3.3机器学习在数据科学中的应用
IBM Watson 是一款基于 IBM DeepQA 架构,并运行在基于 IBM POWER7处理器的服务器中的工作负载优化系统,在机器学习和认知计算领域具有重要地位。
(1)机器学习的应用:命中列表 。问题分类。迁移学习 。答案合并 。最优答案选择 。证据扩散 。多项答案 。
(2)机器学习与其他技术的集成应用:统计分析。信息检索。
自然语言处理。知识表示与推理。人机接口 等相关知识领域的融合,较好地反映了这些不同技术的集成化应用趋势。
2.3.4数据科学视角下的机器学习
目前仍存在的挑战:
过拟合:目标函数在训练集上的准确率高,在测试集的效率却很低。
维度灾难:在高纬度空间数据上效果底,甚至不可行。
特征工程:实际数据处理中,往往需要分析训练集的样本特征——分类标签特征。
算法的可扩展性:硬件,软件以及训练集上的可扩展性。
模型集成:将多个模型进行集成处理。
2.4 数据可视化
数据为什么要可视化?
-
一方面是因为数字太抽象,图表更直观,而且图表可以突出数据中的关注点(比如某个月的交易大幅度波动等);
-
另一方面,数据面向的受众大都不具备专业的数据知识,可视化的形式有助于降低读懂数据的门槛;
简言之,数据可视化提高了数据沟通的效率。
一个直白的例子,可视化前的原始数据表

可视化处理之后,一下直观许多(Boss看了都想给你加薪)
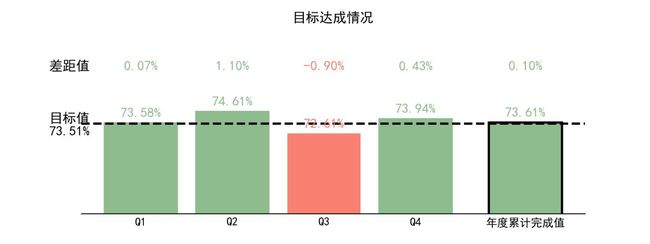
2.4.1可视化在数据科学中的地位
(1)视觉感知是人类大脑的最主要途径:视觉感知是人类大脑的最主要功能之一;眼睛是感知信息能力最强的人体器官之一。
(2)相对于统计分析,数据可视化的主要优势体现在:数据可视化处理可以洞察统计分析无法发现的结构和细节;数据可视化结果的解读对用户知识水平的要求较低。
(3)可视化可以帮助人类提高理解与处理数据的效率。
(4)在人类数据处理和科学技术的发展中扮演着重要的角色。
2.4.2常用的数据可视化工具
1.Tableau(球队数据的分析)
2.Matplotlib
Matplotlib 是Python中类似 MATLAB 的绘图工具,熟悉 MATLAB 也可以很快的上手 Matplotlib。
Python--Matplotlib(基本用法)
3.Seaborn

Seaborn常见绘图总结
数据科学求学道路还长,大家共勉