ROS机器人Diego 1#制作(七)ROS语音系统
更多创客作品,请关注笔者网站园丁鸟,搜集全球极具创意,且有价值的创客作品
现在语音识别很火,但从笔者的实际经验来看,目前的语音识别技术还远没有到大规模使用的阶段,语音识别现在无论是在线的还是离线的都在相对安静的环境下识别率比较高,但一旦有噪音,或者多人对话,现在语音识别技术都没有办法准确识别。
国内使用的比较多的是科大讯飞的识别技术,而且在线识别的准确率比较高,笔者本也打算集成科大讯飞的,但从其网站下载的SDK来发现,其对Linux只支持x86,x64的计算机,对于树莓派是不支持的,有网友说可以通过其客服获得树莓派版本的,但多次联系科大讯飞的客服都没有得到回复,这里要吐槽一下

在ROS中语音识别包使用的是sphinx,在笔者前面的智能小车中已经介绍过了,但在ROS kinetic这个版本中是没有安装sphinx的,需要手动安装,安装过程如下:
一、语音识别
1.首先安装如下依赖包
sudo apt-get install ros-kinetic-audio-common
sudo apt-get install libasound2
sudo apt-get install gstreamer0.10-*
sudo apt-get install python-gst0.10
2.安装libsphinxbase1
https://packages.debian.org/jessie/libsphinxbase1
由于Diego使用的是树莓派平台,所以请下载armhf版本的
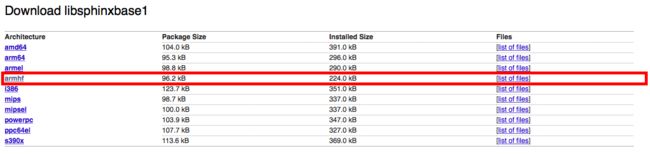
下载完后执行
sudo dpkg -i libsphinxbase1_0.8-6_amdhf.deb
3.安装libpocketsphinx1
https://packages.debian.org/jessie/libpocketsphinx1
也下载armhf版本,下载完成后后执行
sudo dpkg -i libpocketsphinx1_0.8-5_amdhf.deb
4.安装gstreamer0.10-pocketsphinx
https://packages.debian.org/jessie/gstreamer0.10-pocketsphinx
同样下载armhf版本,下载完后执行
sudo dpkg -i gstreamer0.10-pocketsphinx_0.8-5_amdhf.deb
5.安装pocketsphinx
进入工作目录,克隆git目录
cd ~/catkin_ws/src
Git clone https://github.com/mikeferguson/pocketsphinx
6.下载英文语音包pocketsphinx-hmm-en-tidigits (0.8-5)
https://packages.debian.org/jessie/pocketsphinx-hmm-en-tidigits
在包pocketsphinx下面建一个model目录,存放语音模型文件
cd ~/catkin_ws/src/pocketsphinx
mkdir model
将下载好的语音文件,解压后,将其中的model文件下的所有文件拷贝到~/catkin_ws/src/pocketsphinx/model下

7.在~/catkin_ws/src/pocketsphinx目录下新建launch文件夹,创建diego_voice_test.launch文件
cd ~/catkin_ws/src/pocketsphinx
mkdir launch
vi diego_voice_test.launch
diego_voice_test.launch文件内容如下
8.修改recognizer.py文件
在def init(self):函数中增加hmm参数的读取
def __init__(self):
# Start node
rospy.init_node("recognizer")
self._device_name_param = "~mic_name" # Find the name of your microphone by typing pacmd list-sources in the terminal
self._lm_param = "~lm"
self._dic_param = "~dict"
self._hmm_param = "~hmm" #增加hmm参数
# Configure mics with gstreamer launch config
if rospy.has_param(self._device_name_param):
self.device_name = rospy.get_param(self._device_name_param)
self.device_index = self.pulse_index_from_name(self.device_name)
self.launch_config = "pulsesrc device=" + str(self.device_index)
rospy.loginfo("Using: pulsesrc device=%s name=%s", self.device_index, self.device_name)
elif rospy.has_param('~source'):
# common sources: 'alsasrc'
self.launch_config = rospy.get_param('~source')
else:
self.launch_config = 'gconfaudiosrc'
rospy.loginfo("Launch config: %s", self.launch_config)
self.launch_config += " ! audioconvert ! audioresample " \
+ '! vader name=vad auto-threshold=true ' \
+ '! pocketsphinx name=asr ! fakesink'
# Configure ROS settings
self.started = False
rospy.on_shutdown(self.shutdown)
self.pub = rospy.Publisher('~output', String)
rospy.Service("~start", Empty, self.start)
rospy.Service("~stop", Empty, self.stop)
if rospy.has_param(self._lm_param) and rospy.has_param(self._dic_param):
self.start_recognizer()
else:
rospy.logwarn("lm and dic parameters need to be set to start recognizer.")
在def start_recognizer(self):函数hmm参数的代码,如下
def start_recognizer(self):
rospy.loginfo("Starting recognizer... ")
self.pipeline = gst.parse_launch(self.launch_config)
self.asr = self.pipeline.get_by_name('asr')
self.asr.connect('partial_result', self.asr_partial_result)
self.asr.connect('result', self.asr_result)
self.asr.set_property('configured', True)
self.asr.set_property('dsratio', 1)
# Configure language model
if rospy.has_param(self._lm_param):
lm = rospy.get_param(self._lm_param)
else:
rospy.logerr('Recognizer not started. Please specify a language model file.')
return
if rospy.has_param(self._dic_param):
dic = rospy.get_param(self._dic_param)
else:
rospy.logerr('Recognizer not started. Please specify a dictionary.')
return
#读取hmm属性,从配置文件中
if rospy.has_param(self._hmm_param):
hmm = rospy.get_param(self._hmm_param)
else:
rospy.logerr('Recognizer not started. Please specify a hmm.')
return
self.asr.set_property('lm', lm)
self.asr.set_property('dict', dic)
self.asr.set_property('hmm', hmm) #设置hmm属性
self.bus = self.pipeline.get_bus()
self.bus.add_signal_watch()
self.bus_id = self.bus.connect('message::application', self.application_message)
self.pipeline.set_state(gst.STATE_PLAYING)
self.started = True
8.启动shpinx
roslaunch pocketsphinx diego_voicd_test.launch
现在可以对着你的机器人说话了,注意要说语音模型字典中的单词

用户可以参考智能小车制作过程全纪录: 五、软件平台— Sphinx语音识别
一文中介绍的方法制作自己的模型字典
sphinx对于特定的语音环境识别还是不错的,但是一旦环境发生变化,有了不同的噪音,识别率会显著降低,这也是现在语音识别技术所面临的共同难题
二、语音合成
在ROS中已经集成了完整的语音合成包source_play,只支持英文的语音合成,执行如下命令,即可测试
rosrun sound_play soundplay_node.py
rosrun sound_play say.py "hi, i am diego."