lightgbm打卡笔记(一):部署与分类预测可视化
lightgbm的安装
CPU安装方式
默认CPU:
pip install lightgbm
GPU安装方式
GPU安装方式有点难,如果是在linux下,预装环境需要编译的东西有点多,详情见上一篇为:
linux下openssl、cmake与boost的更新总结
如果确保了cmake是在3.16版本以上,boost这些前置环境编译成功,那么就可以编译lightgbm了。
1. 从源码安装lightgbm
git clone --recursive https://github.com/microsoft/LightGBM ;
cd LightGBM
mkdir build && cd build
# 开启MPI通信机制,训练更快
# cmake -DUSE_MPI=ON ..
# GPU版本,训练更快
# cmake -DUSE_GPU=1 ..
cmake -DUSE_GPU=1 -DOpenCL_LIBRARY=/usr/local/cuda/lib64/libOpenCL.so -DOpenCL_INCLUDE_DIR=/usr/local/cuda/include/ ..
make -j4
这里我出现了一个很神奇的问题,因为微软这个lightgbm项目是有子项目的,即submodule,我在拉取过程中会报错为:
![]()
如果不管这个东西,然后针对上面这些失败的submodule去一一手动拉取,在lightgbm进行make阶段是会报错的,报错原因忘了截取,所以这时候就需要针对submodule这一问题进行相关git命令:
# 在git clone针对submodule失效后,在clone下的文件夹运行submodule命令
git submodule init && git submodule update
这将会让项目产生关联。
2. pip安装lightgbm
pip install lightgbm --install-option=--gpu
or
pip install lightgbm --install-option=--gpu --install-option="--opencl-include-dir=/usr/local/cuda/include/" --install-option="--opencl-library=/usr/local/cuda/lib64/libOpenCL.so"
这里如果出现报错,即是还有一些lightgbm依赖包的版本需要升级,比如graphviz以及protobuf等,按照报错去一一安装就行了。
这里,如果没有去进行预编译,而选择直接安装,我再另一台机器上试了一下,lightgbm报错信息为:
Installing collected packages: lightgbm
Running setup.py install for lightgbm ... error
ERROR: Command errored out with exit status 1:
command: /home/anaconda3/envs/py37_kt/bin/python3.7 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py'"'"'; __file__='"'"'/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-osfog8le/install-record.txt --single-version-externally-managed --compile --install-headers /home/anaconda3/envs/py37_kt/include/python3.7m/lightgbm --gpu
cwd: /tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/
Complete output (32 lines):
running install
INFO:LightGBM:Starting to compile the library.
INFO:LightGBM:Starting to compile with CMake.
Traceback (most recent call last):
File "/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py", line 95, in silent_call
subprocess.check_call(cmd, stderr=log, stdout=log)
File "/home/anaconda3/envs/py37_kt/lib/python3.7/subprocess.py", line 363, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['cmake', '/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/compile', '-DUSE_GPU=ON']' returned non-zero exit status 1.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "" , line 1, in <module>
File "/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py", line 378, in <module>
'Topic :: Scientific/Engineering :: Artificial Intelligence'])
File "/home/anaconda3/envs/py37_kt/lib/python3.7/site-packages/setuptools/__init__.py", line 163, in setup
return distutils.core.setup(**attrs)
File "/home/anaconda3/envs/py37_kt/lib/python3.7/distutils/core.py", line 148, in setup
dist.run_commands()
File "/home/anaconda3/envs/py37_kt/lib/python3.7/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/home/anaconda3/envs/py37_kt/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py", line 252, in run
nomp=self.nomp, bit32=self.bit32, integrated_opencl=self.integrated_opencl)
File "/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py", line 198, in compile_cpp
silent_call(cmake_cmd, raise_error=True, error_msg='Please install CMake and all required dependencies first')
File "/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py", line 99, in silent_call
raise Exception("\n".join((error_msg, LOG_NOTICE)))
Exception: Please install CMake and all required dependencies first
The full version of error log was saved into /root/LightGBM_compilation.log
----------------------------------------
ERROR: Command errored out with exit status 1: /home/anaconda3/envs/py37_kt/bin/python3.7 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py'"'"'; __file__='"'"'/tmp/pip-install-uahhte3w/lightgbm_80759da9ff414317ac2404c99f0529c3/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-osfog8le/install-record.txt --single-version-externally-managed --compile --install-headers /home/anaconda3/envs/py37_kt/include/python3.7m/lightgbm --gpu Check the logs for full command output.
任务一:lightgbm模型训练与预测
这里选用iris数据集进行训练与预测,iris数据集是作为sklearn.dataset提供自带的数据集,可视化为:
# 改用花瓣d的长宽这个变量绘制图表
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data[:,2] # X- Axis - petal length
y = iris.data[:, 3] # Y- Axis - petal width
species = iris.target # species
x_min, x_max = x.min() -0.5, x.max() + 0.5
y_min, y_max = y.min() -0.5, y.max() + 0.5
# Scatterplot
plt.figure()
plt.title("Iris Dataset - Classification By Petal Sizes", size = 14)
plt.scatter(x, y, c = species)
plt.xlabel("Petal length")
plt.ylabel("Petal width")
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()

针对iris的训练与预测为:
import lightgbm as lgb
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
print("Train data length:", len(X_train))
print("Test data length:", len(X_test))
# 转换为Dataset数据格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 参数
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
# 模型训练
gbm = lgb.train(params, lgb_train, num_boost_round=20, valid_sets=lgb_eval, early_stopping_rounds=5)
# 模型保存
gbm.save_model('model.txt')
# 模型加载
gbm = lgb.Booster(model_file='model.txt')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# 模型评估
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
"""
Train data length: 120
Test data length: 30
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.906890 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 90
[LightGBM] [Info] Number of data points in the train set: 120, number of used features: 4
[LightGBM] [Info] Start training from score 1.050000
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's auc: 1 valid_0's l2: 0.624825
Training until validation scores don't improve for 5 rounds
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[2] valid_0's auc: 1 valid_0's l2: 0.566515
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[3] valid_0's auc: 1 valid_0's l2: 0.513776
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[4] valid_0's auc: 1 valid_0's l2: 0.465978
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[5] valid_0's auc: 1 valid_0's l2: 0.422738
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[6] valid_0's auc: 1 valid_0's l2: 0.382663
Early stopping, best iteration is:
[1] valid_0's auc: 1 valid_0's l2: 0.624825
The rmse of prediction is: 0.7904584473551157
"""
任务二:模型保存与加载
上面为第一种格式,如下为第二种:
gbm = LGBMRegressor(objective='regression', num_leaves=31, learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
# 模型存储
joblib.dump(gbm, 'loan_model.pkl')
# 模型加载
gbm = joblib.load('loan_model.pkl')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
保存格式可以为之后的继续训练作为基础:
# continue training
# init_model accepts:
# 1. model file name
# 2. Booster()
gbm = lgb.train(params,
lgb_train,
num_boost_round=10,
init_model='model.txt', # 读取保存继续训练
valid_sets=lgb_eval)
print('Finished 10 - 20 rounds with model file...')
任务三:分类、回归和排序任务
步骤1 :学习LightGBM中sklearn接口的使用,导入分类、回归和排序接口。
步骤2 :学习LightGBM中原生train接口的使用。
步骤3 :二分类任务/多分类任务/回归任务
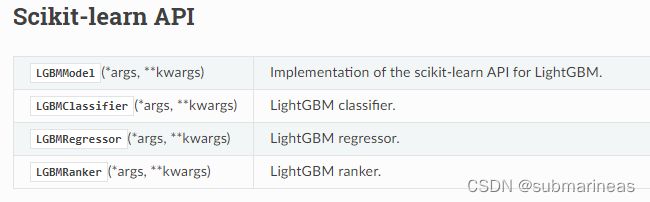
对于sklearn中,lightgbm的api是有四个,但就我目前只用过中间两个,LGBMranker我也是第一次听说可以做排序,但找了很久,即使是官网中,也只是在test_sklearn提了一下,后来在另一个GitHub中找到了案例,这里贴一下链接,第二个链接更具有学习意义:
https://github.com/microsoft/LightGBM/blob/8a34b1af2d5ae734a446f97ee984508a55ecb2d4/tests/python_package_test/test_sklearn.py
https://github.com/jiangnanboy/learning_to_rank
关于原生train接口,对比LGBMClassifier与LGBMRegressor,个人偏向于用train,因为不论是做比赛,或者只要有用到lightgbm的,能自己制定params就自己制定,记太多api也难于记忆,并且sklearn中接口参数是不好写的。
关于原生与sklearn api的一些区别,我也搜了些资料,但好像只有kaggle的一个issue讨论过这个问题,不过我也没看出啥来。就我个人理解,train和fit的不同在于,fit作为sklearn的api,它接受 pandas df 或 numpy 数组作为输入,而train采用 (Dataset/DataMatrix) ,另外从输出方面讲,sklearn的分类predict输出是0/1,而原生predict为概率,如果从源码分析,kaggle上有人说fit是封装了一层train,这可以使结果不具有太大差异,然而结果只是一方面,我其实更想关注性能,但这个问题可能只有去看源码才会知晓答案了。
制作数据集
使用sklearn.datasets下的make_regression、make_classification制作数据集,回归数据集如下所示:
from sklearn.datasets import make_regression
X, y, coef =make_regression(n_samples=1000, n_features=1,noise=10, coef=True)
plt.scatter(X, y, color='black')
plt.plot(X, X*coef, color='blue',
linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()

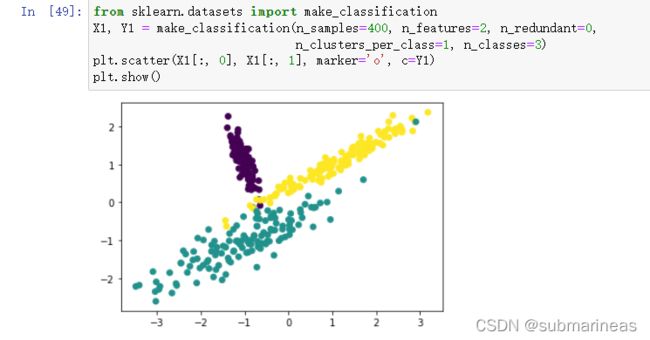
分类数据集为:
from sklearn.datasets.samples_generator import make_classification
X1, Y1 = make_classification(n_samples=400, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
plt.show()
下面介绍二分类、多分类与回归相关写法,这里不准备写sklearn版本,因为第一确实是我不太熟悉,并且主要原因是比赛中基本没有看过sklearn的写法,精通一种就够了,另一种其实只是基于sklearn的api需要修改一些参数。
二分类
data,target=datasets.make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0,n_repeated=0, n_classes=2, n_clusters_per_class=1)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data,target, test_size=0.2)
print("Train data length:", len(X_train))
print("Test data length:", len(X_test))
# 转换为Dataset数据格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 参数
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'binary', # 目标函数
'metric': {'binary_logloss', 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
# 模型训练
gbm = lgb.train(params, lgb_train, num_boost_round=20, valid_sets=lgb_eval, early_stopping_rounds=5)
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
"""
Train data length: 80
Test data length: 20
[LightGBM] [Info] Number of positive: 42, number of negative: 38
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000021 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 56
[LightGBM] [Info] Number of data points in the train set: 80, number of used features: 2
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.525000 -> initscore=0.100083
[LightGBM] [Info] Start training from score 0.100083
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's binary_logloss: 0.665382 valid_0's auc: 0.958333
Training until validation scores don't improve for 5 rounds
......
[6] valid_0's binary_logloss: 0.549485 valid_0's auc: 0.927083
Early stopping, best iteration is:
[1] valid_0's binary_logloss: 0.665382 valid_0's auc: 0.958333
"""
多分类
data,target=datasets.make_classification(n_samples=300, n_features=3, n_informative=3, n_redundant=0,n_repeated=0, n_classes=3, n_clusters_per_class=1)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data,target, test_size=0.2)
print("Train data length:", len(X_train))
print("Test data length:", len(X_test))
# 转换为Dataset数据格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 参数
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'multiclass', # 目标函数
'num_class': 3,
'metric': 'multi_logloss', # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': -1, # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
# 模型训练
gbm = lgb.train(params, lgb_train, num_boost_round=20, valid_sets=lgb_eval, early_stopping_rounds=5)
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
"""
Train data length: 240
Test data length: 60
[1] valid_0's multi_logloss: 1.03556
Training until validation scores don't improve for 5 rounds
[2] valid_0's multi_logloss: 0.977001
[3] valid_0's multi_logloss: 0.924362
......
[18] valid_0's multi_logloss: 0.46049
[19] valid_0's multi_logloss: 0.440463
[20] valid_0's multi_logloss: 0.420385
Did not meet early stopping. Best iteration is:
[20] valid_0's multi_logloss: 0.420385
"""
回归
X, y, coef =make_regression(n_samples=1000, n_features=1,noise=10, coef=True)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print("Train data length:", len(X_train))
print("Test data length:", len(X_test))
# 转换为Dataset数据格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 参数
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
# 模型训练
gbm = lgb.train(params, lgb_train, num_boost_round=20, valid_sets=lgb_eval, early_stopping_rounds=5)
# 模型保存
gbm.save_model('model.txt')
# 模型加载
gbm = lgb.Booster(model_file='model.txt')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# 模型评估
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
"""
Train data length: 800
Test data length: 200
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000041 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 800, number of used features: 1
[LightGBM] [Info] Start training from score 0.003554
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's l2: 601.565 valid_0's auc: 0.961913
Training until validation scores don't improve for 5 rounds
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
......
[6] valid_0's l2: 402.323 valid_0's auc: 0.961411
Early stopping, best iteration is:
[1] valid_0's l2: 601.565 valid_0's auc: 0.961913
The rmse of prediction is: 24.526813192924457
"""
任务四:模型可视化
步骤1 :安装graphviz
步骤2 :将树模型预测结果进行可视化,并将结果保存为图像,
步骤3(扩展) :在任务2中我们保存了json版本的树模型,其中一家包含了每棵树的结构,进行展示
安装:
pip install graphviz
这一步如果是经过GPU编译的情况下,是已经预安装了,然后我们就能针对如上模型进行可视化,展示为:
lgb.plot_tree(gbm, tree_index=3, figsize=(20, 8), show_info=['split_gain'])
plt.show()

如果要下载,需要svg图像:
ax = lgb.create_tree_digraph(gbm)
with open('fst.png', 'w') as f:
f.write(ax._repr_svg_())
然后可以在在线平台上转换成jpg显示,或者直接用代码转换:
