【数据库-Hive】Hive基础知识
hive基础
hive基本命令
基本类型
- 基本数据类型:int/float/double/string/boolean/bigint
- 复杂类型:array/map/struct
常见Hive语法
use database_name
create database if not exist db_name
desc database db_name
create table table_name(...) row format delimited fields terminated by "\t" atore as textline
select * from table_name
alter table table_name rename to new_table_name
hive -e "sql-cmd"
hive -f test.sql
beeline
生成学生数据
# coding='utf8'
import uuid
import random
import json
name = ['Tom', 'Jerry', 'Jim', 'Angela']
hobby = ['readding', 'play', 'dancing', 'sing']
subject = ['math', 'chinese', 'english', 'computer']
data = []
# user_id|user_name|hobby|scores
# dc8fa3d7414049218c78036e898f10ae|Tom|["sing","dancing"]|{"math":72,"chinese":87,"english":84,"computer":87}
for item in name:
scores = {key: random.randint(60, 100) for key in subject}
data.append("|".join([uuid.uuid4().hex, item, ','.join(random.sample(set(hobby), 2)),
','.join(["{0}:{1}".format(k, v) for k, v in scores.items()])]))
with open('student.csv', 'w') as f:
f.write('\n'.join(data))
创建表
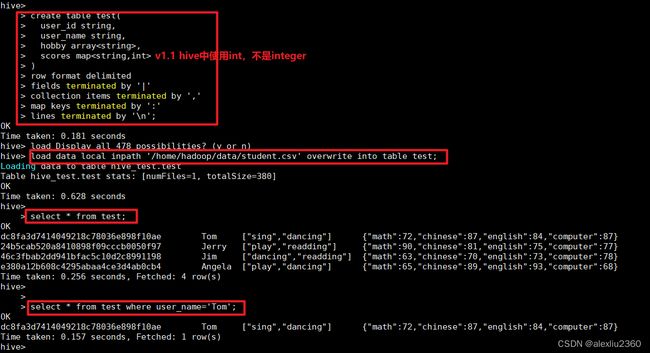
create database hive_test;
use hive_test;
-- 创建内部表
create table test(
user_id string,
user_name string,
hobby array<string>,
scores map<string,int>
)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
load data local inpath '/home/hadoop/data/student.csv' overwrite into table test; -- 本地加载
select * from test;
select * from test where user_name='Tom';
hive -e 'select * from hive_test.test'
hive -f hive_test.sql
beeline -u jdbc:hive2://localhost:10000 -u hadoop -e "select * from hive_test.test"
image.png
内部表&外部表
内部表:和传统数据库的table类似,对应HDFS存储目录,删除表时,删除元数据和表数据
外部表:指向已经存在的hdfs数据,删除时只删除元数据信息
-- 创建外部表
create external table external_table(
user_id string,
user_name string,
hobby array<string>,
scores map<string,int>
)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
-- 这里的test.csv是本地的数据
load data local inpath '/home/hadoop/test.csv' overwrite into table external_table; -- 本地加载

hdfs dfs -ls /hive/warehouse/hive_test.db/external_table

表删除
-- 内部表删除后即物理删除,外部表删除后,在hdfs中还存在
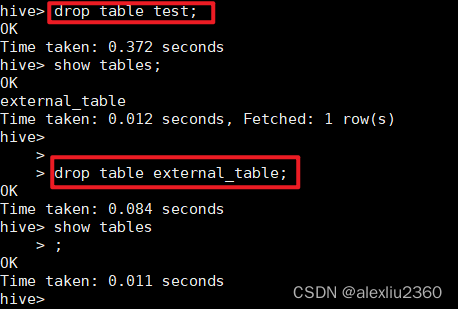
drop table test;
drop table exertnal_table;


分区表&分桶表
分区表:partition对应普通数据库第partiton列的密集索引,将数据按照partition列存储到不同目录,便于并行分析,减少数据量
分桶表:对数据进行hash,放到不同文件存储,方便抽样和join查询
创建分区表
-- 创建分区表
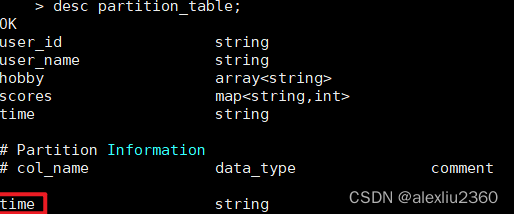
create table partition_table(
user_id string,
user_name string,
hobby array<string>,
scores map<string,int>
)
partitioned by (time string)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
-- 载入数据
load data local inpath '/home/hadoop/data/student.csv' overwrite into table partition_table partition (time='201912');
-- 查看数据
select count(*) from partition_table where time='201912';
hadoop fs -ls /user/hive/warehouse/partition_table
![]()
创建分桶表
-- 创建分桶表
create table bucket_table(
user_id string,
user_name string,
hobby array<string>,
scores map<string,int>
)
clustered by (user_name) sorted by (user_name) into 2 buckets -- clustered
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
-- 从test表中读取数据插入
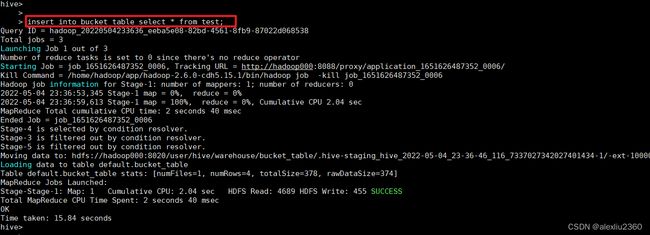
insert into bucket_table select * from test;
-- 采样
select * from bucket_table tablesample(bucket 1 out of 2 on user_name);
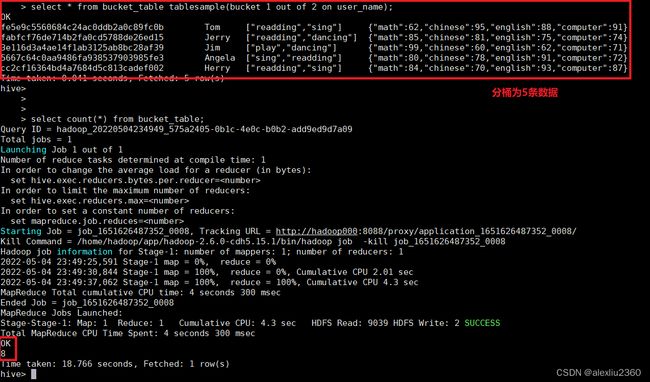
Hive函数
内置函数
- 字符串类型
- concat
- substr
- upper
- lower
- 时间类型
- year
- month
- day
- 复杂类型
- size
- get_json_object
自定义函数
UDF:用来处理输入一行,输出一行的操作,类似于map
UDAF:自定义聚合函数,用来处理输入多行,输出一行的操作,类似reduce
UDTF:自定义表产生函数,用来处理输入一行,输出多行的操作
执行jar包
make clean install
hadoop fs -mkdir /udf
hadoop fs -put /udf/*.jar /udf
add jar hdfs:///udfs/udf-test-1.0-SNAPSHOT.jar;
-- 注册临时函数
create temporary function avg_score as "com.imooc.hive.udf.AvgScore";
select user_name, strlen(user_name),avg_score(scores) from test;
-- 删除注册函数
drop temporary function avg_score;
-- 永久注册需要将jar包放到hdfs上,避免无法找到
create function avg_score as 'com.imooc.hive.udf.AvgScore' using jar 'hdfs://udf/hive-udf-test-1.0-SNAPSHOT.jar';
-- 删除注册函数
drop function avg_score;
Hive存储格式
| 格式 | 优点 | 缺点 |
|---|---|---|
| TextFile | 简单,方便查看 | 不支持分片 |
| SequenceFile | 可压缩 可分割 | 需要合并 不易查看 |
| OrcFile | 分片 按列查询 速度快 | 不易查看 |
ORCFile存储格式

列式存储
- OrcFile
- 支持有限的ACID和更新
- 查询效率高
- Parquet
- 不支持ACID和更新
- 压缩能力高
总结
一句话描述Hive
Hive是一个构建在Hadoop之上的数据仓库软件,它可以使已经存的数据结构化,它提供类似sql的查询语句HiveQL对数据进行分析处理。
HQL转换为MapReduce的流程
了解了MapReduce实现SQL基本操作之后,我们来看看Hive是如何将SQL转化为MapReduce任务的,整个编泽过程分为六个阶段;
- Antir定义SQL的语法规则,亮成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
- 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
- 遍历QueryBlock,翻译为执行操作树OperatorTree
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shutfle数据量
- 遍历OperatorTree,翻译为MapReduce任务
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
Hive与Mysql的区别
- 产品定位
Hive是数据仓库,是为海量数据的离线分析设计的,不支持OLTP(联机事务处理)所需的关健功能ACID,而更接近于0LAP(联机分析技术),适合高线处理大数据集;而MySQL是关系型数据库,是为实时业务设计的。
- 可扩展性
Hive中的数据存储在HDFS(Hadop的分布式文件系统),metastore元数据一般存稳在独立的关系型数据库中,而MySQL则是服务量本地的文件系统;因此Hive具有良好的可扩展性,数据库由于ACID语义的严格限制,扩展性十分有限。
- 读写模式
Hive为读时模式,数据的验证则是在查询时进行的,这有利于大数据集的导入,读时模式使数据的加酸非常讯速,数据的加战仅是文件复制或移动。MySQL为写时模式,数据在与入数据库时对照模式检查,与时模式有利于提升查询性能,因为数据库可以对列进行索引。
- 数据更新
Hive是针对数据仓库应用设计的,而数仓的内容是读多写少的,Hive中不支持对数据进行改写,所有数据都是在加载的时候确定好的;而数据库中的数据通常是需要经常进行修改的,
- 索引
Hive支持索引,但是He的索引与关系型数据库中的索引并不相同,比如,Hve不支持主提或者外性,He课供了有限的案引功能,可以为一些字段建立案引,一张表的索引数据在储在另外一张表中,由于数看的访间延识较高,Hve不活合在的数据查询:数据库在少量的特定条件的数据访问中,索引可以提供较低的延记。
- 计算模型
Hive使用的模型是MapReduce(也可以onspark),而MySQL使用的是自己设计的Executor计算模
Hive数据存储格式
Hive中的数据存储格式分为TextFle,SequenceFile和Orc三种,其中TexFle是默认的存结格式,通过简单的分隔符可以对csv等类型的文件进行解析。而ORCFile是我们常用的一种存储格式,因为ORCFle是列式存储格式,更加适合大数据查的场景,
Hive表类型
Hive几和基本表类型:内部表、外部表、分区表、分桶表。
**内部表: **内部表的数据,会存放在HDFS中的特定的位置中,我们在安装Hive的配置中是在/hive/warehouse,当删除表时,数据文件也会一并删除;适用于临时创建的中间表
**外部表: **适用于想要在Hive之外使用表的数据的情况。当你删除Extemal Table时,只是删除了表的元数据,它的数据并没有被清除,适用于数据多部门共享,建表时使用create exdernal table,指定exdernal关键字即可。
**分区表: **分区表创建表的时候需要指定分区字段,分区字段与普通字段的区别;分区字段会在HDFS表目录下生成一个分区字段名称的目录,而普通字段则不会,查询的时候可以当成普通字段来使用,一般不直接和业务直接相关。
**分桶表: **将内部表,外部表和分区表进一步组织成桶表,可以将表的列通过Hash算法进一步分解成不同的文件存储。
重点关注一下分区表和分桶表,HQL通讨where字句来限制条件提取数据,那么遍历一张大表,不如将这张大表拆分成多个小表,并通过合话的索引来扫描表中的一小部分,分区和分桶都是采用了这种理念。
分区会创建物理目录,并目可以具有子目录(通常会按照时间,地区分区),目录名以=创建,分区名会作为表中的伪列,这样通过where字句中加入分区的眼制可以在仅扫描对应子目录下的数据,通过parifioned by (field1 tvpe…)
分桶可以继续在分区的基础上再划分小表,分桶根据哈希值来确定数据的分布(即MapReducer中的分区!),比如分区下的一部分数据可以根据分桶再分为多个桶,这样在查询时先计算对应列的哈希值并计算桶号,只需要扫满对应桶中的数据即可,通过clustered by(field ) into n buckets
Hive自定义函数
当Hive提供的内置函数无法满定你的业务处理需要时,此时就可以考虑使用用户自定义函数,Hive中包含三类自定义函数:
**UDF:**普通的用户自定义函故、接受单行输入,并产生单行输出。如转换字符串大小写,获取字符串长度等
**UDAF:**用户定义聚集因数(User-defined aggregatefunction),接受多行输入,并产生单行输出,比如MAX,COUNT函数。
**UDTF:**用户定义表生成函数(User-defined table-generating function)。接受单行输入,井产生多行输出(即一个表),不是特别常用
面试题
1、提交一条SQL到Hive后,Hive的执行流程是什么样的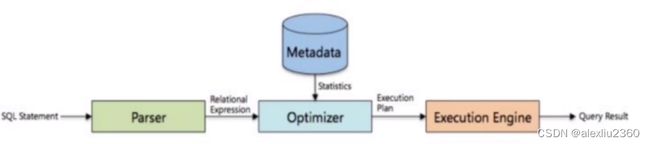
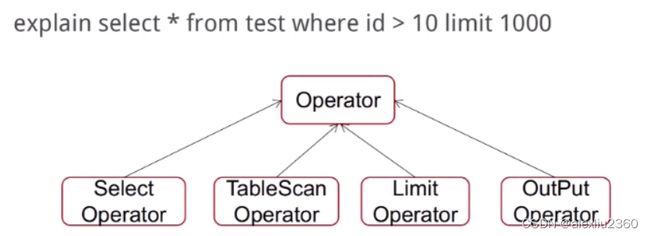
2、Hive表存储模型有哪些?分区分桶的作用?
3、什么是数据倾斜,如何解决数据倾斜?
- 原因
- key分布不均匀,业务数据本身的特型
- 建表考虑不周,SQL语句本身有数据倾斜
- 解决
- 调整参数:hive.map.aggr hive.groupby.skewindata
- 调整SQL语句:Join方式、空值、大小表join
4、Hive存储格式有哪些?平常用哪个?
5、Hive查询时有哪些优化项?
6、使用Hive过程中,遇到过哪些问题?如何解决?