优化算法:《Lookahead Optimizer: k steps forward, 1 step back》
《Lookahead Optimizer: k steps forward, 1 step back》
作者:Michael R. Zhang, James Lucas,Geoffrey Hinton,Jimmy Ba(adam作者)
来源:多伦多大学
论文地址:https://arxiv.org/abs/1907.08610v1
Pytorch实现:https://github.com/alphadl/lookahead.pytorch
Tensorflow:https://github.com/Janus-Shiau/lookahead_tensorflow
文章目录
- 0 前言
- 1 相关研究
- 2 Lookahead
- 3 实验分析
- 4 lookahead在HRNet上的表现
-
- 4.1 初步训练
- 4.2 再次训练
- 5 参考文献
0 前言
最优化方法一直主导着模型的学习过程,没有最优优化器,模型也就没了灵魂。好的最优化方法一直是 ML 社区在积极探索的,它几乎对任何机器学习任务都会有极大的帮助。
从最开始的批量梯度下降,到后来的随机梯度下降,然后到 Adam 等一大帮基于适应性学习率的方法,最优化器已经走过了很多年。尽管目前 Adam 差不多已经是默认的最优优化器了,但从 17 年开始就有各种研究表示 Adam 还是有一些缺陷的,甚至它的收敛效果在某些环境下比 SGD 还差。
为此,我们期待更好的标准优化器已经很多年了…
最近,来自多伦多大学向量学院的研究者发表了一篇论文,提出了一种新的优化算法——Lookahead。值得注意的是,该论文的最后作者 Jimmy Ba 也是原来 Adam 算法的作者,Hinton 老爷子也作为三作参与了该论文,所以作者阵容还是很强大的。
1 相关研究
SGD 算法虽然简洁,但其在神经网络训练中的性能堪比高级二阶优化方法。尽管 SGD 每一次用小批量算出来的更新方向可能并非那么精确,但更新多了效果却出乎意料地好。
一般而言,SGD 各种变体可以分成两大类:
- 自适应学习率机制,如 AdaGrad 和 Adam;
- 加速机制,如 Polyak heavyball 和 Nesterov momentum 等
这两种方法都利用之前累积的梯度信息实现快速收敛,它们希望借鉴以往的更新方向。但是,要想实现神经网络性能提升,通常需要花销高昂的超参数调整。
其实很多研究者都发现目前的最优化方法可能有些缺点,不论是Adam还是带动量的SGD,它们都有难以解决的问题。例如我们目前最常用的 Adam,我们拿它做实验是没啥问题的,但要是想追求收敛性能,那么最好还是用SGD结合Momentum。但使用动量机制又会有新的问题,我们需要调整多个超参数以获得比较好的效果,不能像 Adam 给个默认的学习率 0.0001 就差不多了。
在 ICLR 2018 的最佳论文 On the Convergence of Adam and Beyond 中,研究者明确指出了 Adam 收敛不好的原因。他们表明在利用历史梯度的移动均值情况下,模型只能根据短期梯度信息为每个参数设计学习率,因此也就导致了收敛性表现不太好。
那么 Hinton 等研究者是怎样解决这个问题的?他们提出的最优化方法能获得高收敛性能的同时,还不需要调参吗?
2 Lookahead
本文提出的新的优化方法lookahead,该方法与之前的SGD有所不同, 整体算法如下图:

他拥有2套权重:
-
Fast Weights :
它是由内循环优化器(inner-loop)生成的k次序列权重;这里的优化器就是原有的优化器,如SGD,Adam等均可;其优化方法与原优化器并没有区别,例如给定优化器A,目标函数L,当前训练mini-batch样本d,其更新规则:
θ t , i + 1 = θ t , i + A ( L , θ t , i − 1 , d ) \theta_{t,i+1} = \theta_{t,i}+A(L,\theta_{t,i-1},d) θt,i+1=θt,i+A(L,θt,i−1,d)
但这里会将该轮循环的k次权重,用序列都保存下来 -
Slow Weights:
在每轮内循环结束后,根据本轮的k次权重,计算等到Slow Weights;这里采用的是指数移动平均(exponential
moving average (EMA))算法来计算,我之前有篇博客总结了该算法,有兴趣可以去看看

最终模型使用的参数也是慢更新(Slow Weights)那一套,因此快更新(Fast Weights)相当于做了一系列实验,然后慢更新再根据实验结果选一个比较好的方向,这有点类似 Nesterov Momentum 的思想。
该研究表明这种更新机制能够有效地降低方差。研究者发现 Lookahead 对次优超参数没那么敏感,因此它对大规模调参的需求没有那么强。此外,使用 Lookahead 及其内部优化器(如 SGD 或 Adam),还能实现更快的收敛速度,因此计算开销也比较小。
研究者在多个实验中评估 Lookahead 的效果。比如在 CIFAR 和 ImageNet 数据集上训练分类器,并发现使用 Lookahead 后 ResNet-50 和 ResNet-152 架构都实现了更快速的收敛。
研究者还在 Penn Treebank 数据集上训练 LSTM 语言模型,在 WMT 2014 English-to-German 数据集上训练基于 Transformer 的神经机器翻译模型。在所有任务中,使用 Lookahead 算法能够实现更快的收敛、更好的泛化性能,且模型对超参数改变的鲁棒性更强。
这些实验表明 Lookahead 对内部循环优化器、fast weight 更新次数以及 slow weights 学习率的改变具备鲁棒性。
3 实验分析
研究人员在一系列深度学习任务上使用 Lookahead 优化器和业内最强的基线方法进行了对比,其中包括在 CIFAR-10/CIFAR-100、ImageNet 上的图像分类任务。此外,研究人员在 Penn Treebank 数据集上训练了 LSTM 语言模型,也探索了基于 Transformer 的神经机器翻译模型在 WMT 2014 英语-德语数据集上的表现。对于所有实验,每个算法都使用相同数量的训练数据。
不同优化算法的性能比较:

(左)在 CIFAR-100 上的训练损失;(右)使用不同优化器的 ResNet-18 在 CIFAR 数据集上的验证准确率。研究者详细研究了其它优化器的学习率和权重衰减;Lookahead 和 Polyak 超越了 SGD。
ImageNet 的训练损失:

星号表示激进的学习率衰减机制,其中 LR 在迭代 30、48 和 58 次时衰减。右表展示了使用 Lookahead 和 SGD 的 ResNet-50 的验证准确率。
Lookahead在Penn Treebank上的表现:

从这些实验中,可以得到如下结论:
对于内部优化算法A、k 和 α 的鲁棒性:研究人员在 CIFAR 数据集上的实验表明,Lookahead 可以始终如一地在不同初始超参数设置中实现快速收敛。我们可以看到 Lookahead 可以在基础优化器上使用更高的学习率进行训练,且无需对 k 和 α 进行大量调整。
内循环和外循环评估:研究人员发现,在每个内循环中 fast weights 可能会导致任务性能显著下降——这证实了研究者的分析:内循环更新的方差更高
4 lookahead在HRNet上的表现
4.1 初步训练
任务描述:
- 在HRNet框架上,hrnet_w18模型,训练其在手部关键点任务
- lookahead采用pytorch实现版本
- 对比算法:adam
- lookahead:内训练采用adam
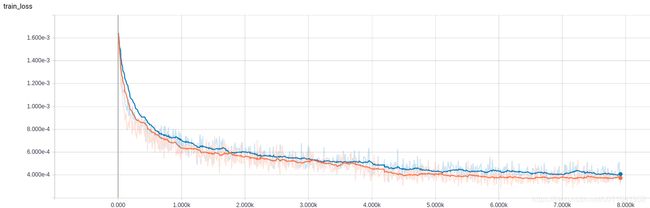
train_loss:
- 红线:adam
- 蓝线:lookahead+adam
- loss
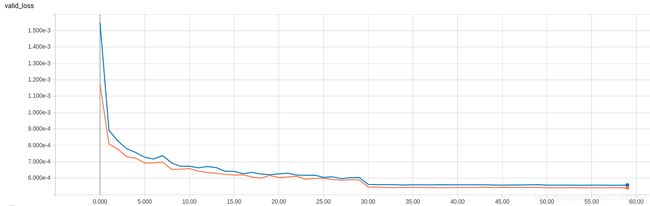
valid_loss:
- loss
分析:
- 从loss上看,lookahead并没有提升效果,反而下降一点点
- 可能是lookahead对HRNet无效
- 更可能,是我没能正确使用该算法,没有领悟其精髓,上面是个错误示范
- 后期将在多训练测试
4.2 再次训练
1)任务描述:
- 在HRNet框架上,hrnet_w18模型,训练其在hand关键点任务
- lookahead采用pytorch实现版本
- 训练集:21120
- 测试集:3000
2)图例说明:

- 图中不同颜色与后面图中loss曲线对应
- sgd分别使用0.01,0.001,0.0001初始学习率;
- lookahead,rmsprop,adam都采用0.0001初始学习率;
- 总共迭代30 epoch,在20,25 epoch时学习率下降10倍
- batch_size = 32
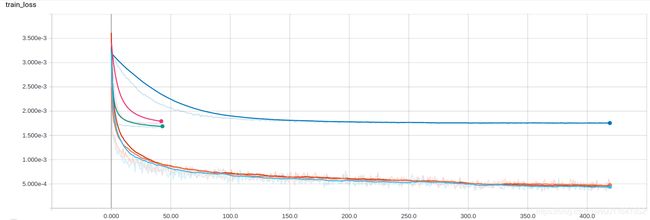
3)Train Loss:
- 平滑前

- 平滑后
- 说明:
1)SGD:上面的3条线都是sgd曲线,区别在初始学习率不一样,从上往下分别为0.0001,0.001,0.01(时间关系有2条线没有训练完,也因为sgd loss曲线下降太慢,看着着急)
2)lookahead,rmsprop,adam:下面贴在一起的3条曲线;从曲线上看adam(最下面的淡蓝色)稍微好一点点,其次为lookahead(中间的黄色),最后为rmsprop(上面的红色)
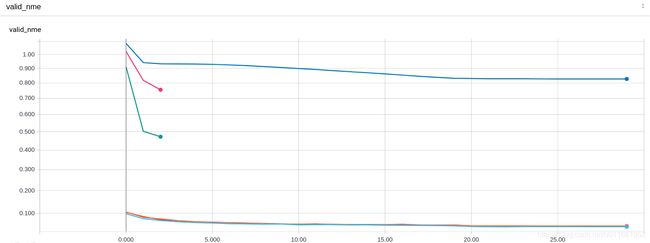
4)Test Loss:
- valid 曲线和train曲线反映一致
- sgd收敛慢
- adam > lookahead > rmsprop

4)NME Loss: - nme 曲线和train曲线反映一致
- adam > lookahead > rmsprop > sgd
5 参考文献
[1] Adam作者大革新, 联合Hinton等人推出全新优化方法Lookahead: https://www.jiqizhixin.com/articles/2019-07-25-14
[2]lookahead : https://blog.csdn.net/jacke121/article/details/97296669