基于Tensorflow2的YOLOV4 网络结构及代码解析(1)——backbone网络结构
笔者以tensorflow2代码作为基础,解析yolovV4的网络结构。
主要从以下几个部分剖析yolov4:
1.YOLOV4的backbone网络结构(本博客)
2.YOLOV4的NECK和YoloHead
3.YOLOV4的Loss和Input
4.YOLOV4的创新点以及一些tricks
在详细介绍代码前,谈一谈对整个网络结构的理解。yolo系列用于目标检测,有别于rcnn系列,yolo被认为是one-stage算法,故旨在做到速度与准确率兼顾而不是一味追求高准确率。本人从事嵌入式相关的图像处理工作,实际应用中很少有芯片可以达到PC机的速度,因此对于检测速度和实时性的要求在实际应用中更为重要。笔者主要开发工作在zynq芯片上完成,虽然有fpga作为加速手段,但显而易见的是,使用现有yoloV4移植到芯片中是无法实现实时性的。选择研究yoloV4算法以及TF2的最终目标是可以实现在嵌入式系统中完成实时的目标检测任务。让算法应用于实际工程,创造价值才是程序员的终极目标。
在剖析的同时,会对代码细节进行详细解释(代码来源:https://github.com/bubbliiiing/yolov4-tf2)。本篇博文着重于代码细节,可能对于大牛们而言过于繁琐
Yolov4论文地址:https://arxiv.org/pdf/2004.10934.pdf
backbone网络结构:
yolov4以CSPDarkNet53作为backbone,替换了yolov3原有的DarkNet54。如下图所示(图片来源:https://blog.csdn.net/weixin_44791964/article/details/106533581):
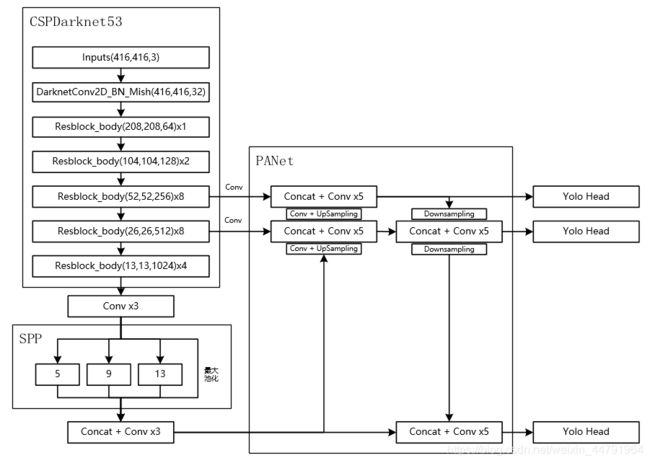
对yoloV4网络结构做个总览。在学习过程中,我将整个网络结构分为几个部分:1.特征提取部分(CSPDarkNet53),2.图像空间金字塔池化部分(SPP),3.NECK部分(PANet),4.检测头部分(YOLO head)。本篇博文着重于特征提取部分也就是CSPDarkNet53。
笔者按照代码顺序逐步剖析yolov4源码,能帮助大家理解相关代码。目标检测任务分为训练部分和检测部分。本篇博客以预测部分代码为主,有关训练部分将放在“YOLOV4的Loss和Input”进行解析。
Let's begin:
yolo = YOLO()将类实例化,YOLO主要包含的方法有:
__init__(self, **kwargs),_get_class(self),_get_anchors(self),generate(self),get_pred(self, image_data, input_image_shape),detect_image(self, image)__init__(self, **kwargs):用于初始化
_defaults = {
"model_path" : 'model_data/yolo4_weight.h5',
"anchors_path" : 'model_data/yolo_anchors.txt',
"classes_path" : 'model_data/coco_classes.txt',
"score" : 0.5,
"iou" : 0.3,
"eager" : True,
"max_boxes" : 100,
"model_image_size" : (416, 416)
}
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
if not self.eager:
tf.compat.v1.disable_eager_execution()
self.sess = K.get_session()
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.generate()初始化YOLO()类时调用了_get_class(self),_get_anchors(self),generate(self)方法。分别获取类,anchors参数以及载入网络模型。
这里有个语法细节:
self.__dict__.update(self._defaults)使用该语法可以简化赋值。该语法等同于如下代码:
def __init__(self):
self.model_path=self._defaults['model_path']
self.anchors_path=self._defaults['anchors_path']
self.classes_path=self._defaults['classes_path']
self.score=self._defaults['score']
self.iou=self._defaults['iou']
self.eager=self._defaults['eager']
self.max_boxes=self._defaults['max_boxes']
self.model_image_size=self._defaults['model_image_size']
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.generate()_get_class(self):用于获取识别时使用的类别名字
_get_anchors(self):用于获取anchors参数
两段代码原理基本相同,一并解释。
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)其中有个语法细节
classes_path = os.path.expanduser(self.classes_path)expanduser函数,它可以将参数中开头部分的 ~ 或 ~user 替换为当前用户的home目录并返回。但是在这里并没有什么用,可能是出于工程的严谨考虑。classes文件通过不同行将类别分开,anchors文件通过“,”将数值分开。
anchors = [float(x) for x in anchors.split(',')]使用for循环分别读取相应数据。上面的代码段也是标准的用法。注:anchors获取数据后进行reshape(-1,2)。
generate(self):生成网络结构并载入网络参数。也是本片博客最重要的部分。
self.yolo_model = yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)通过yolo_body可以生成网络结构。传入参数分别是“Keras.layers.Input”,anchors个数/3(也就等于3)以及类别个数(80)。通过该函数返回Model。其中已经包括SPPNET部分的NECK。返回值为
Model(inputs, [P5_output, P4_output, P3_output])。其中input为输入的tensor,shape为(416,416,3)
P5_output, P4_output, P3_output为输出结果,需要经过yolohead解析后才可以使用。shape分别为(13,13,255),(26,26,255),(52,52,255)。
对应关系:(13,13,255)对应13*13的网格,3个anchors既(13,13,3,85)。85=(x,y,w,h,confident,classes)。具体分析见下一篇博客。
这里有两个细节:
1.语法细节。python语法中,“//”表示整数除法,既返回值为整数。“/”表示浮点出除法,既返回值为浮点数类型
2."Input"用法。对应“from tensorflow.keras.layers import Input ”。查看tensorflow2的api可知,Input()函数用于实例化一个kesras的tensor。主要用于构建Model对象使用,例如:a,b,c均为Keras tensors,可根据已知的输入输出进行构建:model=Model(input=[a,b],output=c)。个人理解,Input函数生成一个指定的tensor,我们可以将这个tensor看作是tf1中的占位符(placeholder).该tensor可以用于tensorflow中的其他操作。另外,Input方法详细用法为:
tf.keras.Input(
shape=None, batch_size=None, name=None, dtype=None, sparse=False, tensor=None,
ragged=False, **kwargs
)shape:输入尺寸,不包括batch的值。"None”表示不知道输入的值,也就是任意值。
batch_size:批量值。
name:名字,在模型中必须唯一。
dtype:数据类型。
sparse与ragged不可以同时为true。理解为是否稀疏矩阵,当值为“None"时,表示ragged维度。代码中未见使用,不做详解。
tensor:选择存在的tensor保证input。
feat1, feat2, feat3 = darknet_body(inputs)该部分为特征提取部分。对应上图中 部分。input为输入图像,shape为(416,416,3)。feat1,feat2,feat3的shape分别为(52,52,256),(26,26,512),(13,13,1024)。
部分。input为输入图像,shape为(416,416,3)。feat1,feat2,feat3的shape分别为(52,52,256),(26,26,512),(13,13,1024)。
CSPDarknet53进行一次DarknetConv2D_BN_Mish后经过5个resblock_body,获取3个有效特征层。
def darknet_body(x):
x = DarknetConv2D_BN_Mish(32, (3,3))(x)
x = resblock_body(x, 64, 1, False) #one
x = resblock_body(x, 128, 2) #two
x = resblock_body(x, 256, 8) #three
feat1 = x
x = resblock_body(x, 512, 8) #four
feat2 = x
x = resblock_body(x, 1024, 4) #five
feat3 = x
return feat1,feat2,feat3三个特征层的输出分别在第三个resblock后,第四个resblock后以及第五个resblock后。
def DarknetConv2D_BN_Mish(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
Mish())DarknetConv2D_BN_Mish是整个特征提取中相对独立的部分。这里有几个地方值得深究
1.卷积层未使用偏置:标准卷积运算后需要加上偏置项,使之成为类似多层感知机来实现特征提取。而现在的网络结构中很多已经放弃了偏置。究其原因在于BN层。网上很多相关的解释说明这个问题,我这里用张图来表明我对这个问题的理解。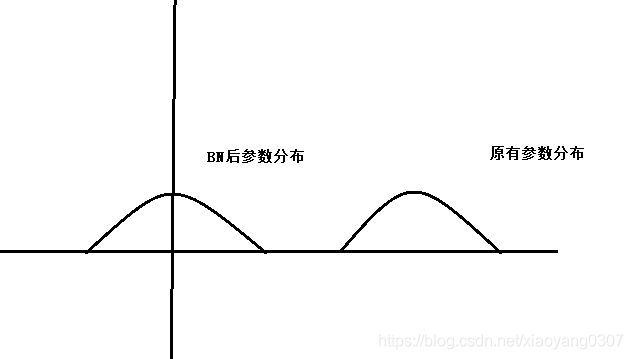 经过批量归一化之后,参数的被限定在相对固定的区域中,故不需要使用偏置项,这样还可以减少内存的消耗。
经过批量归一化之后,参数的被限定在相对固定的区域中,故不需要使用偏置项,这样还可以减少内存的消耗。
2.darknetConv2D函数:
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
# darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs = {}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)该函数有两个细节:1.进行特征图缩小时,并不是使用池化函数,而直接更改步长。具体哪个效果更好,笔者也很难下定义。
2.@wraps(view_func)的作用: 不改变使用装饰器原有函数的结构(如name, doc)。在代码中,加不加@wrap都可以正常运行。从功能上来看,darknetConv2D通过步长修改输出特征图尺寸,其中忽略了‘padding'的功效。
3.BatchNormalization的用法:通常情况下我们调用函数均保持默认参数也不会出现太大的问题,但BN层是个例外。笔者曾在这上面花了很多时间。论文描述: 论文中的流程现实的比较清楚,这里就不加赘述了。tensorflow官方api如下:
论文中的流程现实的比较清楚,这里就不加赘述了。tensorflow官方api如下:
tf.keras.layers.BatchNormalization(
axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True,
beta_initializer='zeros', gamma_initializer='ones',
moving_mean_initializer='zeros',
moving_variance_initializer='ones', beta_regularizer=None,
gamma_regularizer=None, beta_constraint=None, gamma_constraint=None,
renorm=False, renorm_clipping=None, renorm_momentum=0.99, fused=None,
trainable=True, virtual_batch_size=None, adjustment=None, name=None, **kwargs
)其中几个值得注意的参数为:
axis:指定需要归一化的维度。如data_format="channels_first"时,axis=1.data_format="channels_last"时,axis=-1。
momentum:默认值为0.99。当训练batch>100时,不会出现问题。但是当batch数量远远小于100时,几乎不会通过每个批次进行更新。理想对应关系为:batch=10-->momentum=0.9。batch=50-->momentum=0.98。具体算法细节见(https://www.cnblogs.com/jiangxinyang/p/9705198.html)
trainable:训练与预测时的返回值不同。训练时,函数返回![]() 。其中gamma与beat是我们需要学习的参数。
。其中gamma与beat是我们需要学习的参数。
预测时,函数返回![]() 。
。
4.Mish激活函数。
class Mish(Layer):
def __init__(self, **kwargs):
super(Mish, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return inputs * K.tanh(K.softplus(inputs))
def get_config(self):
config = super(Mish, self).get_config()
return config
def compute_output_shape(self, input_shape):
return input_shapemish激活函数 该函数可以理解为将softplus激活函数与tanh进行组合得到。
该函数可以理解为将softplus激活函数与tanh进行组合得到。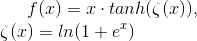 softplus理解为平滑的relu激活函数。mish在多个测试集上的表现由于relu,详见https://blog.csdn.net/u011984148/article/details/101444274。这里不讨论为什么他的表现更好,笔者更关注代码实现本身。这里我们讨论的细节是自定义层的问题。
softplus理解为平滑的relu激活函数。mish在多个测试集上的表现由于relu,详见https://blog.csdn.net/u011984148/article/details/101444274。这里不讨论为什么他的表现更好,笔者更关注代码实现本身。这里我们讨论的细节是自定义层的问题。
自定义层需要继承tf.keras.layers.Layer层,并重写_init_,build,call三个方法。
_init_方法负责初始化。build方法在第一次使用该层的时候调用该部分代码,在这里创建变量可以使得变量的形状自适应输入形状而不需要使用额外指定变量形状。如果已经完全确认变量形状,也可以在_init_中创建。call方法是模型调用时使用的代码。
5.compose方法。
def compose(*funcs):
if funcs:
return reduce(lambda f, g: lambda *a, **kw: g(f(*a, **kw)), funcs)
else:
raise ValueError('Composition of empty sequence not supported.')该方法作用在于实现复合函数。我们需要一步步进行分割解析。参考文献:https://blog.csdn.net/tpz789/article/details/104417869/
通俗解释:reduce(function, sequence): function是一个函数,sequence是一个数据集合(元组、列表等)。先将集合里的第1,2个参数参入函数执行,再将执行结果和第3个参数传入函数执行…,最终得到最后一个结果
在这里,sequence集合是一个函数列表,整个表达式可以理解为Mish(BatchNormalization(DarknetConv2D(*args, **no_bias_kwargs)))
上述部分将所有DarknetConv2D_BN_Mish函数中的细节阐述完整。
resblock_body函数是整个特征提取的主要部分,反复使用了5次,每个block的不同仅在于重复次数和特征维度。CSPNet将浅层特征分为两部分,一部分(Part2)经过正常的ResBlock另一部分(Part1)则直接作为输出,最后将部分concate起来。见下图(图片来源https://www.cnblogs.com/pprp/p/12566116.html)
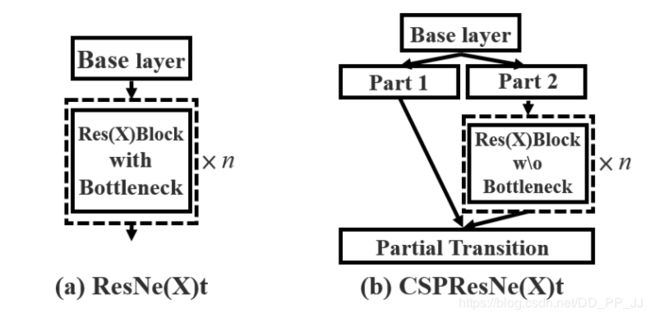
接下来详细分析下。图片来源(https://blog.csdn.net/easonccc/article/details/108879514)


左边是论文中提及的网络结构,右边是源码中实际使用的网络结构。可以看出,源码中并未将特征维度分为两部分再分别进行卷积,而是直接使用1*1卷积核进行降维。
def resblock_body(x, num_filters, num_blocks, all_narrow=True):
preconv1 = ZeroPadding2D(((1,0),(1,0)))(x)
preconv1 = DarknetConv2D_BN_Mish(num_filters, (3,3), strides=(2,2))(preconv1)
shortconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
mainconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Mish(num_filters//2, (1,1)),
DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (3,3)))(mainconv)
mainconv = Add()([mainconv,y])
postconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(mainconv)
route = Concatenate()([postconv, shortconv])
return DarknetConv2D_BN_Mish(num_filters, (1,1))(route)参数:x表示输入特征,num_filters表示输出特征维度,num_block表示小残差块个数,all_narrow表示是否需要大残差块。
CSPDarknet的结构块就是一个大的残差块和内部多个小的残差块组成。在进入resblock之前,利用ZeroPadding2D和一个步长为2x2的卷积块进行高和宽的压缩(缩小一半)
代码中DarknetConv2D_BN_Mish和compose已经在前文中分析,本部分详解的内容:
1.ZeroPadding2D:这里输入的参数是(1,0),(1,0)。根据官方文档,参数表示分别在上面和左边增加1个像素点作为扩充。既输入图像(416,416)变为(417,417)。默认0填充。
2.Add:这里是特征图中的像素依次相加,不改变整个特征图的维度
3.Concatenate:这里是相应维度的特征值做拼接,特征图维度发生改变。参数axis指定所需要拼接的维度。
tf.keras.layers.Concatenate(
axis=-1, **kwargs
)
上述已经将yolov4特征提取部分所有细节全部描述清楚,最后笔者补充两个关于tensorflow关于层和模型的问题。
1.笔者在学习过程中有个问题一直疑惑,代码如下
input_shape = (4, 28, 28, 3)
x = tf.random.normal(input_shape)
y = tf.keras.layers.Conv2D(
2, 3, activation='relu', input_shape=input_shape[1:])(x)这是调用Conv2D最基础的部分。笔者的疑惑在于调用Conv2D(参数)(输入值)。为什么输入的值不是在参数中传入而放在对象后面传入?
原因在于__call__函数:允许一个类的实例像函数一样被调用。实质上说,这意味着 x() 与 x.__call__() 是相同的。注意 __call__ 参数可变。这意味着你可以定义 __call__ 为其他你想要的函数,无论有多少个参数。__call__ 在那些类的实例经常改变状态的时候会非常有效。
换言之,我们是等同于调用了Conv2D类中的__call__函数。顺便提一下的是,如上文所述,我们自定义类是需要重写_init_,build以及call函数。其中call函数被包裹在__call__中,由于tf2需要做一些其他的操作,故暴露出call函数便于我们使用。同理可得,激活函数,池化函数的原理也是相同的。
2.关于Model类的问题。
自定义model时,需要重写__init__和call函数。
当model创建后,可以通过model.compile()配置损失和测量以及通过model.fit()配置训练相关信息,通过model.predict()进行预测单张图片以及evaluate()预测测试集。
本篇博客均为自己对yoloV4以及tensorflow2的部分理解,如果有错误,欢迎纠正和提出意见。
后续将持续更新
-
YOLOV4的NECK和YoloHead
-
YOLOV4的Loss和Input
-
YOLOV4的创新点以及一些tricks
E-mail:[email protected]