Datawhale 7月学习——李弘毅深度学习:卷积神经网络
前情回顾
- 机器学习简介
- 回归
- 误差与梯度下降
- 深度学习介绍和反向传播机制
- 网络的优化
1 卷积神经网络
1.1 为什么要有卷积神经网络

我们希望hidden layer每一层都挖掘到新的信息,但是对于图片来说每一个像素都去挖掘,太多了,网络会很大。
而CNN是把这个过程简化和focus的方法,用比较少的参数来完成影像处理。
为什么可以完成这样的处理?
-
我们所关注图片的信息往往是一部分
我们判断一个pattern在图片中有没有出现,只需要看图中的一小部分就好。比如判断是不是有鸟嘴,只要看鸟嘴那个部分就好。

-
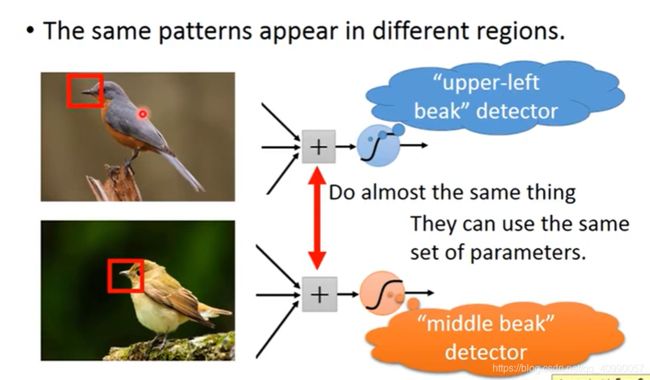
所关注的信息出现的位置不需要固定
同样的pattern在图片里面,可能会出现在图片不同的部分,但是代表的是同样的含义,它们有同样的形状,可以用同样的neural,同样的参数就可以把pattern侦测出来。比如不同图片中的鸟嘴不一定会出现在同一个地方。
-
图片缩小可能不影响查看
把一个图片去掉部分行列的像素并不会影响人对照片的理解。

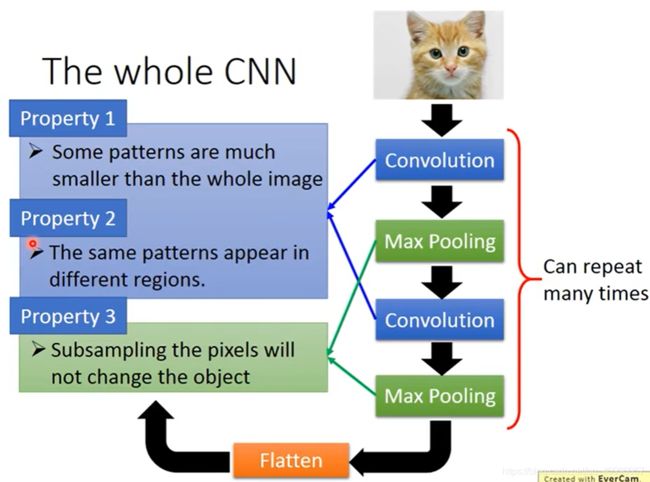
对应到我们设计的CNN,CNN是输入一张图片,然后经过若干的卷积层(Convolution)和池化层(max pooling),然后最后再进行一个flatten出来一个结果。
对应到前面的三点观察就是,使用卷积层来进行细节的非确定位置关注(所以卷积层为什么能实现这个功能),使用池化层来完成类似缩小的功能。
1.2 卷积和池化
1.2.1 卷积
卷积层(Convolution)是完成卷积操作的主要层。
卷积操作是这样完成的,使用一个Filter矩阵, 然后对图片像素矩阵按行按列以指定步长逐个进行内积计算,可以得到一个缩小的矩阵。
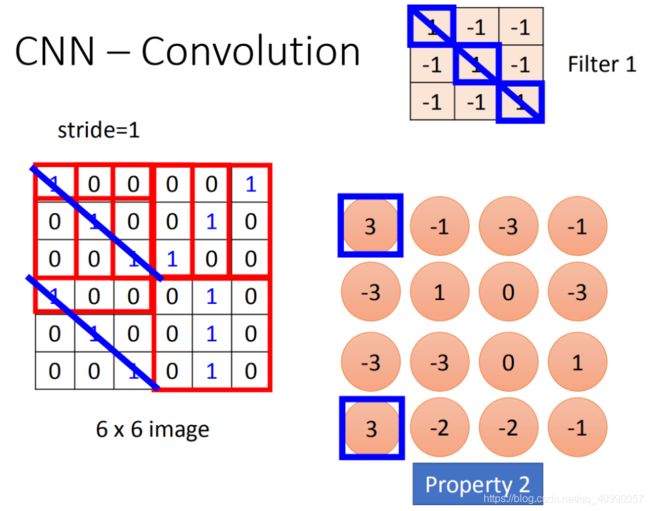
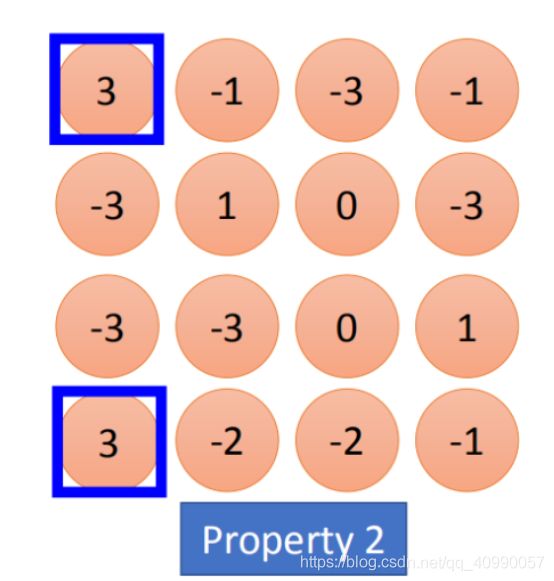
卷积层是如何实现细节非确定位置关注的呢?
- 一定大小的filter可以实现区域的关注

- 同一个filter可以实现同一细节不同位置的关注
我们可能不止关注一种细节,每种细节都可以计算对每一个filter,而每一个filter都可以对应出一个feature map,就是经过一系列内积计算后出来的那个的矩阵。

而对于rgb图来说,由于我们面临的输入是三个二维矩阵,则对应的每个filter也需要是三个二维矩阵。

在做convolution的话,就是将filter的9个值和image的9个值做内积(不是把每一个channel分开来算,而是合在一起来算,一个filter就考虑了不同颜色所代表的channel)
convolution和fully connected在神经网络中的地位是等同的,都是一个运算层,只是计算的方式不同,这个比较好理解,就不展开叙述。

1.2.2 池化
把卷积完的结果再分组把信息集合起来,集合的方式可以是max,min或者mean等。
这一步的目的应该是进一步减小矩阵的大小。
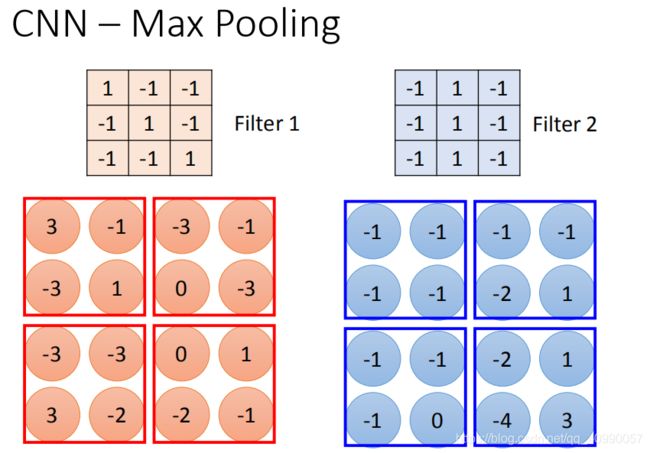

假设我们选择四个里面的max vlaue保留下来,这样可能会有个问题,把这个放到neuron里面,这样就不能够微分了,但是可以用微分的办法来处理的 (打个问号)
1.2.3 卷积与池化结合
那么一个卷积+池化就构成了如下一个处理过程。
有点像是对原有的矩阵进行了一个特征提取,然后每一个filter 对应可能是一类特征,对应一个提取出来的结果,图中写的是channel。
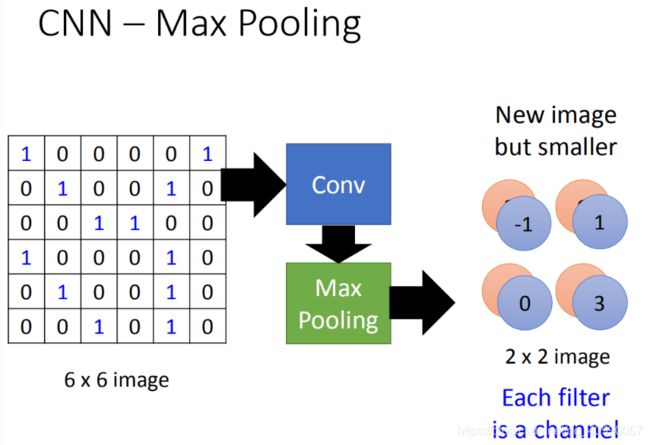
这样的过程可以反复进行很多次。
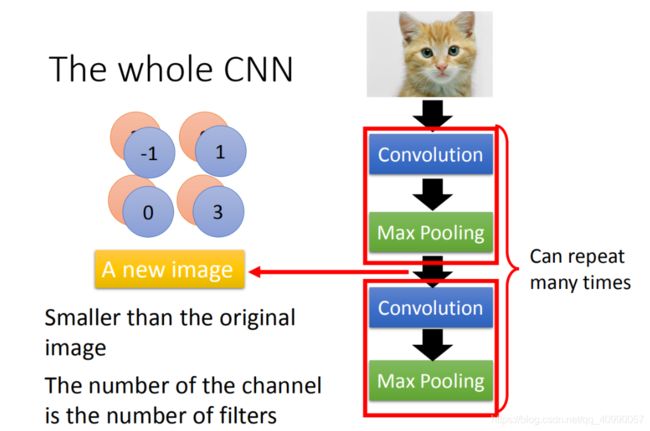
这边有一个问题:第一次有25个filter,得到25个feature map,第二个也是由25个filter,那将其做完是不是要得到 2 5 2 25^2 252的feature map。其实不是这样的!
假设第一层filter有2个,第二层的filter在考虑这个imput时是会考虑深度的,并不是每个channel分开考虑,而是一次考虑所有的channel。所以convolution有多少个filter,output就有多少个filter(convolution有25个filter,output就有25个filter。只不过,这25个filter都是一个立方体)
1.2.4 Flatten
其实就是一个把二维拉平成一维的过程,拉直之后就可以丢到fully connected feedforward network。

2 卷积神经网络的实现
2.1 卷积神经网络在keras中的实现
在keras中,与一般的神经网络相比,主要是要放入两类层,convolution卷积层和pooling池化层(最常用的是max pooling)。

课件中提供的代码已经过时,此处针对keras版本2.5.0进行更新。
对应的卷积层函数为layers.Con2D
tf.keras.layers.Conv2D(
filters,
kernel_size,
strides=(1, 1),
padding=“valid”,
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=None,
use_bias=True,
kernel_initializer=“glorot_uniform”,
bias_initializer=“zeros”,
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
第一个参数对应filter数量,第二个参数对应kernel_size。
下述案例展示了维度的变化。
>>> input_shape = (4, 28, 28, 3)
>>> x = tf.random.normal(input_shape)
>>> y = tf.keras.layers.Conv2D(
... 2, 3, activation='relu', input_shape=input_shape[1:])(x)
>>> print(y.shape)
(4, 26, 26, 2)
对应的池化层函数为layers.MaxPooling2D
tf.keras.layers.MaxPooling2D(
pool_size=(2, 2), strides=None, padding=“valid”, data_format=None, **kwargs
)
第一个参数为池化大小。
使用MINST手写数据集进行一个简单的卷积神经网络搭建,代码参考了keras官方文档。
首先进行数据集的导入和预处理。
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
# Model / data parameters
num_classes = 10
input_shape = (28, 28, 1)
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
可以得到
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
接下来搭建卷积神经网络。
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.summary()
model.summary()方法输出了模型的结构。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1600) 0
_________________________________________________________________
dropout (Dropout) (None, 1600) 0
_________________________________________________________________
dense (Dense) (None, 10) 16010
=================================================================
Total params: 34,826
Trainable params: 34,826
Non-trainable params: 0
进行训练。
batch_size = 128
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
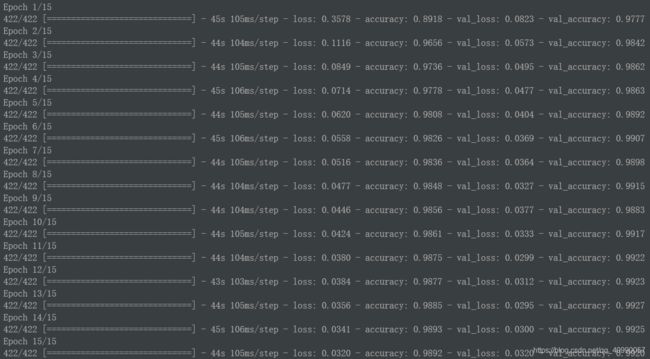
在测试集上的表现。
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
结果如下:
Test loss: 0.023392125964164734
Test accuracy: 0.9922999739646912
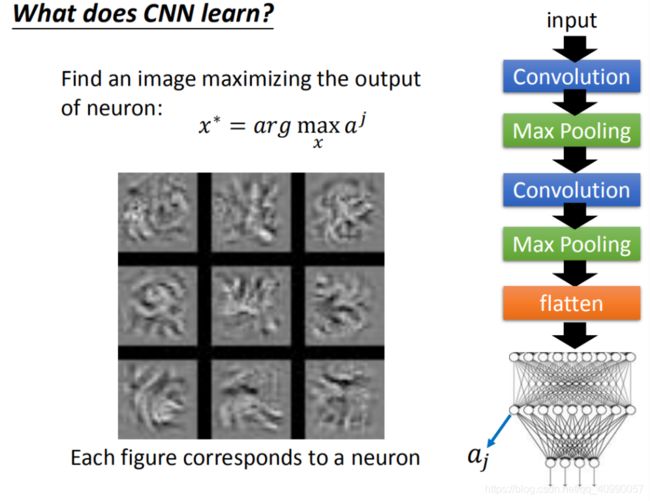
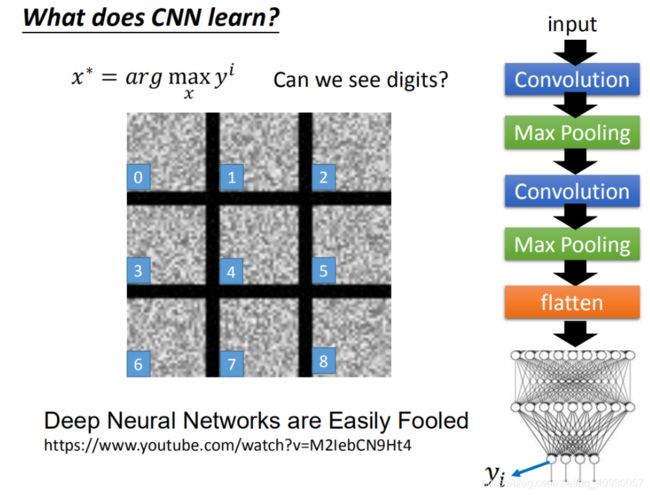
2.2 卷积神经网络学到了什么

李宏毅把第一层filter所对应的输出结果画了出来。

接入全连接层后的输出如下图
参考阅读
- 李宏毅机器学习笔记(LeeML-Notes)
- 李宏毅机器学习课程视频