强化学习代码实操和讲解(一)
强化学习代码实操
- 写在最前面
-
- 总体思路
- 背景介绍
- 重点代码解析
-
- 环境设置
- reset函数设置
- act函数设置
- step函数
- 杂项代码解析
-
- simulate函数
- figure_2_2:对比ε的作用
- figure_2_3:对比乐观初始值的作用
- figure_2_4:基于UCB的动作选择的效果
- figure_2_5:梯度赌博机和是否使用baseline的结果对比
- 总结
写在最前面
本人本科生,为了大创项目在老师的帮助下自学强化学习和深度学习等知识,目前听过了David Silver和周博磊等大牛的课程,对于强化学习的基础知识有了一定的了解,但是上升到打代码上却依然一头雾水,不知道从何写起,因而我从GitHub上面找到了一些感觉很好的练习示例项目,大多数源自《Reinforcement Learning: An introduction》一书,来进行赏析学习。这是原项目地址。里面基本分了章节进行了排布,部分代码有注释,但是没有注释的一部分我对着书研究了一段时间。因而这一系列的文章既是学习过程的记录,也是对自己的一种鞭策。本博客跳过了原书第一章的导论部分,从第二章的多臂赌博机开始。
总体思路
我在接下来的文章中主要用以下思路进行排布:
1.对代码所在的章节背景进行一个简介
2.对重点代码进行赏析解释
3.结合理论对代码进行复盘
4.对学习内容进行总结
希望我能够坚持到底,希望各位看到这篇文章的有缘人也能指出我的不成熟看法并且给些建议。
那接下来让我们开始吧!
背景介绍
k臂赌博机是本书中十分经典的一个模型,在此模型之下没有状态(state)的差异,我们仅仅需要关心我们拉哪个臂的动作(action)。另外,k臂赌博机有动作的真实价值,动作的真实价值从一个均值为0,方差为1的标准正态分布中选择,而实际选择某个动作时,我们所收获的实际收益(return)又是以每个动作的真实价值为均值的方差为1的标准正态分布(整体结构如图所示)。我一开始不明白这个环境的不确定性在哪里,后来才发现实际收益是真实价值基础上的一个分布,并不是确定值(不然也不能算赌博机)。
def figure_2_1(): #绘制下图回报分布的代码
plt.violinplot(dataset=np.random.randn(200, 10) + np.random.randn(10))
plt.xlabel("Action")
plt.ylabel("Reward distribution")
plt.savefig('figure_2_1.png')
plt.close()
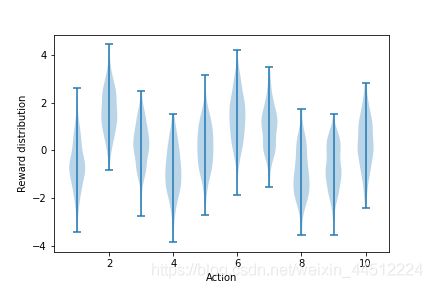
接下来我们将根据书上的描述对一个赌博机进行1000时刻的交互,以评估性能和动作,这将构成一轮的试验。我们再用2000个不同的赌博机(价值、收益不同)完成2000次独立重复实验,从而获得对一个学习算法平均表现的评估。
重点代码解析
我们将在k臂赌博机的环境下实验 ε ε ε-贪心方法再不同 ε ε ε下的训练情况,赌博机简单的增量式实现,乐观初始值的应用,基于置信度上界(UCB)的动作选择以及梯度赌博机算法。基本涵盖了第二章所有有关实操的知识,让我们来逐步分析。
环境设置
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
from tqdm import trange
matplotlib.use('TkAgg')
class Bandit:
def __init__(self,k_arm=10,epsilon=0.,initial=0.,step_size=0.1,sample_average=False,UCB_parameter=None,gradient=False,gradient_baseline=False,true_reward=0.):
self.k=k_arm #设定赌博机臂数
self.step_size=step_size #设定更新步长
self.sample_average=sample_average #bool变量,表示是否使用简单增量式算法
self.indices=np.arange(self.k) #创建动作索引(和赌博机臂数长度相同)
self.time=0 #计算所有选取动作的数量,为UCB做准备
self.UCB_parameter=UCB_parameter #如果设定了UCB的参数c,就会在下面使用UCB算法
self.gradient=gradient #bool变量,表示是否使用梯度赌博机算法
self.gradient_baseline=gradient_baseline #设定梯度赌博机算法中的基准项(baseline),通常都用时刻t内的平均收益表示
self.average_reward=0 #用于存储baseline所需的平均收益
self.true_reward=true_reward #存储一个赌博机的真实收益均值,为下面制作一个赌博机的真实价值函数做准备
self.epsilon=epsilon #设定epsilon-贪婪算法的参数
self.initial=initial #设定初始价值估计,如果调高就是乐观初始值
首先肯定是引入一些环境,主要是matplotlib和numpy包,下面的tqdm主要是用来在实际训练过程中打印进度条的。
接下来就是创建bandit类并且初始化一些变量。所有步骤的含义我都写在了代码块里,要特别注意的是本类涵盖了第二章里的多个任务,所以需要添加一些变量来指示接下来要完成哪个任务,这块代码里的主要难点就是许多不同任务中需要的参量混杂在一起,给理解上带来困难。
接下来就是agent与环境交互和学习的主要部分,大概由以下三个部分组成:
1.reset:在一幕(episode)结束后重置状态以及各项参数;
2.act:agent根据自己的策略选择行动的部分
3.step:环境接受agent的动作并返回return,同时在内部维护一个Q函数,为agent的下一步选择做好准备
之所以要在这里强调这三个部分,是因为这是强化学习编程中的一个很好的分块思想,之后的代码实操很多都是按照这样的思路进行的。
reset函数设置
def reset(self): #初始化训练状态,设定真实收益和最佳行动状态
self.q_true=np.random.randn(self.k)+self.true_reward #设定真实价值函数,在一个标准高斯分布上抬高一个外部设定的true_reward,true_reward设置为非0数字以和不使用baseline的方法相区分
self.q_estimation=np.zeros(self.k)+self.initial #设定初始估计值,在全0的基础上用initial垫高,表现乐观初始值
self.action_count=np.zeros(self.k) #计算每个动作被选取的数量,为UCB做准备
self.best_action=np.argmax(self.q_true) #根据真实价值函数选择最佳策略,为之后做准备
self.time=0 #设定时间步t为0
我把每一步的具体含义也打在代码中了,值得注意的是其中true_reward的用意,我是根据上下文才推测出来的,由于之后要对比使用和不使用baseline的训练效果,而真实价值是一个标准正态分布,这就导致它回报的平均值会接近0,即baseline接近0,这和不使用baseline的效果是类似的,所以在对比baseline效果的实验中我们通过true_reward把真实价值垫高。
act函数设置
def act(self):
if np.random.rand()<self.epsilon:
return np.random.choice(self.indices) #以epsilon的几率随机选择动作
if self.UCB_parameter is not None: #当有设置UCB的参数时,使用基于UCB的动作选择
UCB_estimation=self.q_estimation+self.UCB_parameter*np.sqrt(np.log(self.time+1)/(self.action_count+1e-5)) #预测值更新函数
q_best=np.max(UCB_estimation) #选择不同动作导致的预测值中最大的
return np.random.choice(np.where(UCB_estimation==q_best)[0]) #返回基于UCB的动作选择下值最大的动作
if self.gradient: #如果使用梯度赌博机算法
exp_est=np.exp(self.q_estimation)
self.action_prob=exp_est/np.sum(exp_est) #以上两步按照softmax分布确定动作概率
return np.random.choice(self.indices,p=self.action_prob) #按概率选择执行动作
q_best=np.max(self.q_estimation) #如果不使用以上的其他方法,则使用贪心算法,与第一步构成epsilon-贪心算法
return np.random.choice(np.where(self.q_estimation==q_best)[0]) #执行估计值最大的动作
基本上每一步的用意我也写在了代码中,这一段完成了三个任务,第一是 ε ε ε-greedy算法,第二是基于UCB的动作选择,第三是梯度赌博机算法。每一步都比较严格地按照树上的流程来编写,如果对照书本应该可以很快看懂。
step函数
def step(self,action):
reward=np.random.rand()+self.q_true[action] #奖励是以真实值为平均的正态分布
self.time+=1 #总行动数量+1
self.action_count[action]+=1 #某个行动的行动数量+1
self.average_reward+=(reward-self.average_reward)/self.time #计算平均回报(return),为baseline做好准备
if self.sample_average: #如果使用增量式实现
self.q_estimation[action]+=(reward-self.q_estimation[action])/self.action_count[action] #用采样数据来更新行动价值(赌博机实验中只有一个状态,所以只更新行动价值)
elif self.gradient: #如果使用梯度赌博机
one_hot=np.zeros(self.k)
one_hot[action]=1 #把应该采取的行动概率置为1
if self.gradient_baseline: #在梯度赌博机上使用baseline
baseline=self.average_reward #平均收益天生就是一个良好的baseline
else:
baseline=0 #这里不使用baseline的话baseline就设置为0,如果上面的q_true不用true_reward抬高的话就没办法区分有没有使用baseline了
self.q_estimation+=self.step_size*(reward-baseline)*(one_hot-self.action_prob) #梯度赌博机更新状态价值估计
else:
self.q_estimation[action]+=self.step_size*(reward-self.q_estimation[action]) #使用固定步长更新状态价值
return reward
step函数的任务是接受agent动作,根据agent选择的方法更新价值函数估计,并返回reward以进行平均reward的计算。其他代码解释我都已经打在注释中,值得注意我在baseline=0处的注释与上面true_reward参量的用意相呼应。
杂项代码解析
以上三个函数构成了bandit类,接下来的函数就是调用bandit类来进行模拟、计算和绘图。其中simulate函数用来进行循环实验并返回不同策略指导下赌博机的平均回报和做出最佳选择的概率,剩余的figure函数对应于我们需要的不同实验图像。
simulate函数
def simulate(runs,time,bandits):
rewards=np.zeros((len(bandits),runs,time)) #接收不同赌博机每一轮每一步的回报,方便制成平均回报来画图以对比算法
best_action_count=np.zeros(rewards.shape) #计算选择到最佳动作的数量,为算法对比做准备
for i,bandits in enumerate(bandits): #开始对每个选择不同算法和参数的赌博机进行循环
for r in trange(runs): #对runs个不同的赌博机(算法和超参数相同,奖励分布不同)进行独立实验
bandits.reset()
for t in range(time): #对每个赌博机进行time次实验
action=bandits.act() #赌博机选择动作
reward=bandits.step(action) #返回每个动作的reward
rewards[i,r,t]=reward #把reward放到相应的索引位置方便之后对比
if action==bandits.best_action:
best_action_count[i,r,t]=1 #当赌博机选到最佳动作时+1(最佳动作在赌博机初始化的时候就已经得到)
mean_best_action_counts=best_action_count.mean(axis=1) #计算每个赌博机平均选到最佳动作的概率
mean_rewards=rewards.mean(axis=1) #计算每个赌博机收到的平均回报
return mean_best_action_counts,mean_rewards
书上的没有这一块循环的直接展示,这里由三个循环,第一个循环是有对不同参数设置的赌博机进行循环,不同参数的赌博机对应不同的算法;第二个循环是创建runs个有着相同超参数但是不同奖励分布的赌博机进行循环;第三个循环是对每个赌博机进行time步实验,在其中进行实际的act与回报计算。最后返回每个赌博机选到最佳动作的概率和每个赌博机的平均回报,即选择不同计算策略和不同参数赌博机的表现,方便后面画图对比。
figure_2_2:对比ε的作用
def figure_2_2(runs=2000, time=1000): #对比不同epsilon下的训练情况
epsilons = [0, 0.1, 0.01]
bandits = [Bandit(epsilon=eps, sample_average=True) for eps in epsilons] #这里用了一个list存储了三个相同参数的赌博机(除了epsilon),方便下面迭代对比
best_action_counts, rewards = simulate(runs, time, bandits)
plt.figure(figsize=(10, 20))
plt.subplot(2, 1, 1)
for eps, rewards in zip(epsilons, rewards):
plt.plot(rewards, label='epsilon = %.02f' % (eps))
plt.xlabel('steps')
plt.ylabel('average reward')
plt.legend() #绘制三个赌博机在epsilon不同的情况下的平均奖励对比图
plt.subplot(2, 1, 2)
for eps, counts in zip(epsilons, best_action_counts):
plt.plot(counts, label='epsilon = %.02f' % (eps))
plt.xlabel('steps')
plt.ylabel('% optimal action')
plt.legend()
plt.savefig('figure_2_2.png')
plt.close() #绘制三个赌博机在epsilon不同的情况下最佳动作选择百分比的对比图
第一个绘图函数绘制了在 ε ε ε分别为0,0.1,0.01下贪心算法的实验情况,使用了增量式算法,对比了它们的平均收益和最佳动作的百分比。如图所示。
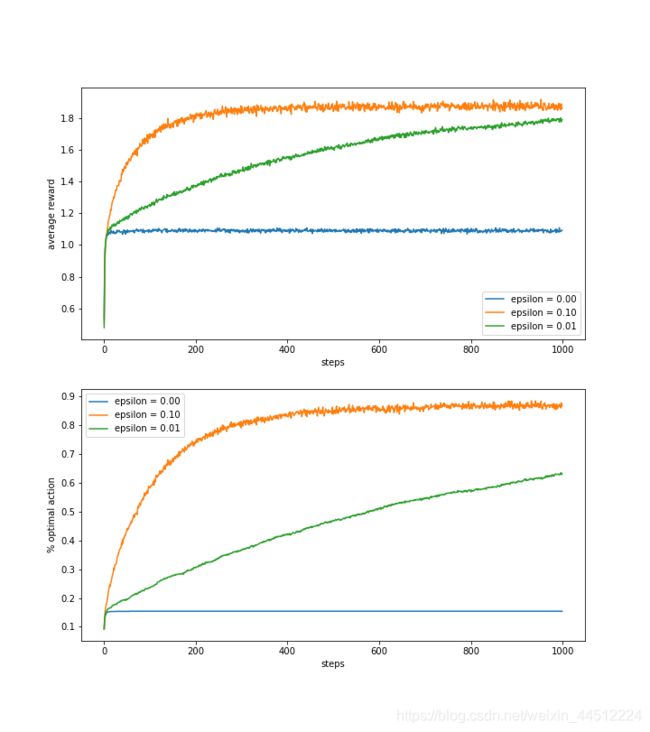
上图显示平均收益随着经验的增长而增长。根据教材上的说法,贪心方法( ε ε ε=0)在最初长得略快些,但最后稳定在一个较低的水平。从长远看,完全贪心的算法无论在何层面上表现都很糟糕,下图表示它只在15%的情况下会选择最好的动作,实际上这和乱猜的情况十分接近,因为贪心算法没法跳出来选择其他策略。 ε ε ε=0.1时试探得最多因而它能够有表现的快速增长,但是它选择最优动作的概率不会超过91%,因为它要在 ε ε ε=0.1的情况下试探。虽然 ε ε ε=0.01时改善较慢,但是它最终的表现会超过 ε ε ε=0.1的情况。
figure_2_3:对比乐观初始值的作用
def figure_2_3(runs=2000, time=1000): #对比乐观初始值的作用
bandits = []
bandits.append(Bandit(epsilon=0, initial=5, step_size=0.1))
bandits.append(Bandit(epsilon=0.1, initial=0, step_size=0.1)) #创建两个赌博机,一个使用乐观初始值5,但是不用epsilon-贪婪进行探索,一个不使用乐观初始值,但是用epsilon探索
best_action_counts, _ = simulate(runs, time, bandits)
plt.plot(best_action_counts[0], label='epsilon = 0, q = 5')
plt.plot(best_action_counts[1], label='epsilon = 0.1, q = 0')
plt.xlabel('Steps')
plt.ylabel('% optimal action')
plt.legend()
plt.savefig('figure_2_3.png')
plt.close() #绘制两个赌博机最佳动作选择百分比的对比图
这里在一张图中展现了使用乐观初始值的探索和使用 ε ε ε-贪婪的探索对比,可以发现乐观初始值的探索在初期拥有非常好的探索能力,但在后期逐渐被 ε ε ε-贪婪的探索超越。如图所示。
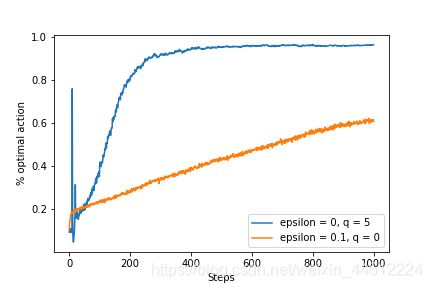
可以非常清楚地看到乐观初始值初期的探索能力很强,但是在300步后趋于平稳,而 ε ε ε-贪婪探索几乎保持线性增长。用书上的话说,就是过度乐观的估计会鼓励动作-价值方法去探索,但是无论哪种动作获得的收益都会让算法感到失望进而促进它不断探索。虽然这种办法在平稳问题中非常有效,但是它试探的驱动力天生是暂时的,所以运作的步数一多它就失去了探索性,趋于平缓。而且在非平稳问题中,比如任务发生了变化,对试探的需求变了,它就无法提供帮助。打个比方,乐观初始值就像“后浪”,在祖宗留下经验的领域(平稳问题)初期发展非常快,但是后期就十分疲软;当社会环境和行情发生变化时(非平稳问题),这种吃老本的方式就不如自我发展的方式(ε-贪婪)来的好。所以我们不应该过多地关注这种做法,书上在后面也没再用过这种方法。
p.s. 书上在这一块留下一个问题,为什么乐观初值在初期会有一个尖峰,本人还没想明白。
figure_2_4:基于UCB的动作选择的效果
def figure_2_4(runs=2000, time=1000): #对比基于UCB的动作选择的作用
bandits = []
bandits.append(Bandit(epsilon=0, UCB_parameter=2, sample_average=True)) #创建一个使用基于UCB的动作选择的赌博机
bandits.append(Bandit(epsilon=0.1, sample_average=True)) #创建一个基于epsilon-贪婪的赌博机
_, average_rewards = simulate(runs, time, bandits)
plt.plot(average_rewards[0], label='UCB c = 2')
plt.plot(average_rewards[1], label='epsilon greedy epsilon = 0.1')
plt.xlabel('Steps')
plt.ylabel('Average reward')
plt.legend()
plt.savefig('figure_2_4.png')
plt.close() #绘制两个赌博机的平均收益
基于UCB的动作选择同样是一种试探方法,相较于 ε ε ε-greedy这种充满随机性的动作选择,基于UCB的动作选择更具有一定的目的性。笼统来说,就是价值较低和被选过很多次的动作再次被选到的可能性会变低。两种试探方式的平均收益如图所示。
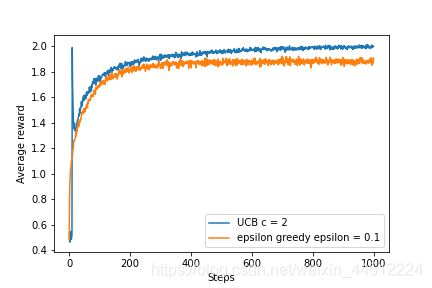
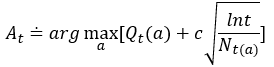
公式中t表示时刻,从侧面也反映了所有动作的总选择次数, N t ( a ) N_t(a) Nt(a)则是在时刻t时动作a被选择的次数,c是大于0的常数,反映了置信水平。每次选择a时,根号内项的分子分母就会同时增大,但是分子上的增长速度大于分母,所以根号项总体会变小,使得再次选择动作a的价值变小;但是如果长时间不选动作a,这一项的价值又会变大,总体上呈现出试探长时间未尝试的动作的状态,相较于ε-贪婪具有更强的目的性。从上面的实验结果来看,基于UCB的动作选择方法表现良好。但是这种方法很难推广到更一般的强化学习问题,第一个困难是处理非平稳问题时这种方法会被改进地更加复杂,另一个困难是在大的状态空间中(特别是之后需要近似的问题中)这种方法很难有用武之地,因为这种方法本质上适合小规模离散问题(因为需要数数)。
p.s.这张图中基于UCB的方法在初期同样有一个尖峰,大伙可以想一想为什么。
figure_2_5:梯度赌博机和是否使用baseline的结果对比
def figure_2_5(runs=2000, time=1000): #对比梯度赌博机中是否使用baseline的结果
bandits = []
bandits.append(Bandit(gradient=True, step_size=0.1, gradient_baseline=True, true_reward=4))
bandits.append(Bandit(gradient=True, step_size=0.1, gradient_baseline=False, true_reward=4))
bandits.append(Bandit(gradient=True, step_size=0.4, gradient_baseline=True, true_reward=4))
bandits.append(Bandit(gradient=True, step_size=0.4, gradient_baseline=False, true_reward=4)) #创建四个赌博机,分别把α设置为两个0.1和两个0.4,其中一个使用baseline一个不使用
best_action_counts, _ = simulate(runs, time, bandits)
labels = ['alpha = 0.1, with baseline',
'alpha = 0.1, without baseline',
'alpha = 0.4, with baseline',
'alpha = 0.4, without baseline']
for i in range(len(bandits)):
plt.plot(best_action_counts[i], label=labels[i])
plt.xlabel('Steps')
plt.ylabel('% Optimal action')
plt.legend()
plt.savefig('figure_2_5.png')
plt.close()
梯度赌博机考虑的价值不同于之前的动作价值,它针对每个动作a学习一个数值化的偏好函数 H t ( a ) H_t(a) Ht(a),并利用偏好函数通过softmax分布计算选择动作的概率,并根据概率分布选择动作。最终四种使用梯度赌博机算法的赌博机训练结果如下。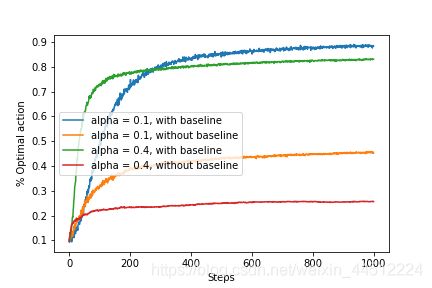
在偏好函数的更新过程中,α代表步长, R ^ t \hat R_t R^t代表时刻t内所有收益的平均值,也就是一个baseline,当一个动作的收益高于它时,偏好函数就会增加,在未来选择这个动作的可能性就会上升。关于baseline的重要性书上并没有详细说明,我从周博磊的课程中猜测,梯度赌博机也相当于用蒙特卡洛法来进行试探,收集到的数据比较noisy,baseline就相当于一个平均数,减去它相当于对数据进行标准化,进而达到更好的训练结果的目的。事实上书上的描述为“收益的平均值变化对梯度赌博机算法没有影响,因为收益基准项可以让它马上适应新的收益水平”,这点应该与数据标准化的观点不谋而合。
总结
本文的最后将本章提到的所有算法进行一个集合展示,以表达他们对比的效果。如图所示。
可以看出不同的算法在不同的参数下达到最高值,要想分辨出哪个算法是最好的显然是不太可能的(虽然从这张图上来看UCB算法拥有较为明显的优势)。况且根据前文的分析,许多算法虽然在本章表现良好,但是难以推广到更一般的问题和更大的空间上,因而价值就大大降低了。本章深入探讨了一些平衡探索与开发的方法,在这些方法种,许多都具有局限性,目前来看,ε-greedy算法是一种非常简单且更易推广的算法,事实上后面的章节中也多拿ε-greedy算法来进行开发。当然目前还有很多新的平衡exploitation和exploration的方法,但是正如书上所说,这依然是强化学习界的最大难题之一。
最后我把本章的含中文注释的完整代码放到这里
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
from tqdm import trange
matplotlib.use('TkAgg')
class Bandit:
def __init__(self,k_arm=10,epsilon=0.,initial=0.,step_size=0.1,sample_average=False,UCB_parameter=None,gradient=False,gradient_baseline=False,true_reward=0.):
self.k=k_arm #设定赌博机臂数
self.step_size=step_size #设定更新步长
self.sample_average=sample_average #bool变量,表示是否使用简单增量式算法
self.indices=np.arange(self.k) #创建动作索引(和赌博机臂数长度相同)
self.time=0 #计算所有选取动作的数量,为UCB做准备
self.UCB_parameter=UCB_parameter #如果设定了UCB的参数c,就会在下面使用UCB算法
self.gradient=gradient #bool变量,表示是否使用梯度赌博机算法
self.gradient_baseline=gradient_baseline #设定梯度赌博机算法中的基准项(baseline),通常都用时刻t内的平均收益表示
self.average_reward=0 #用于存储baseline所需的平均收益
self.true_reward=true_reward #存储一个赌博机的真实收益均值,为下面制作一个赌博机的真实价值函数做准备
self.epsilon=epsilon #设定epsilon-贪婪算法的参数
self.initial=initial #设定初始价值估计,如果调高就是乐观初始值
def reset(self): #初始化训练状态,设定真实收益和最佳行动状态
self.q_true=np.random.randn(self.k)+self.true_reward #设定真实价值函数,在一个标准高斯分布上抬高一个外部设定的true_reward,true_reward设置为非0数字以和不使用baseline的方法相区分
self.q_estimation=np.zeros(self.k)+self.initial #设定初始估计值,在全0的基础上用initial垫高,表现乐观初始值
self.action_count=np.zeros(self.k) #计算每个动作被选取的数量,为UCB做准备
self.best_action=np.argmax(self.q_true) #根据真实价值函数选择最佳策略,为之后做准备
self.time=0 #设定时间步t为0
def act(self):
if np.random.rand()<self.epsilon:
return np.random.choice(self.indices) #以epsilon的几率随机选择动作
if self.UCB_parameter is not None: #当有设置UCB的参数时,使用基于UCB的动作选择
UCB_estimation=self.q_estimation+self.UCB_parameter*np.sqrt(np.log(self.time+1)/(self.action_count+1e-5)) #预测值更新函数
q_best=np.max(UCB_estimation) #选择不同动作导致的预测值中最大的
return np.random.choice(np.where(UCB_estimation==q_best)[0]) #返回基于UCB的动作选择下值最大的动作
if self.gradient: #如果使用梯度赌博机算法
exp_est=np.exp(self.q_estimation)
self.action_prob=exp_est/np.sum(exp_est) #以上两步按照softmax分布确定动作概率
return np.random.choice(self.indices,p=self.action_prob) #按概率选择执行动作
q_best=np.max(self.q_estimation) #如果不使用以上的其他方法,则使用贪心算法,与第一步构成epsilon-贪心算法
return np.random.choice(np.where(self.q_estimation==q_best)[0]) #执行估计值最大的动作
def step(self,action):
reward=np.random.rand()+self.q_true[action] #奖励是以真实值为平均的正态分布
self.time+=1 #总行动数量+1
self.action_count[action]+=1 #某个行动的行动数量+1
self.average_reward+=(reward-self.average_reward)/self.time #计算平均回报(return),为baseline做好准备
if self.sample_average: #如果使用增量式实现
self.q_estimation[action]+=(reward-self.q_estimation[action])/self.action_count[action] #用采样数据来更新行动价值(赌博机实验中只有一个状态,所以只更新行动价值)
elif self.gradient: #如果使用梯度赌博机
one_hot=np.zeros(self.k)
one_hot[action]=1 #把应该采取的行动概率置为1
if self.gradient_baseline: #在梯度赌博机上使用baseline
baseline=self.average_reward #平均收益天生就是一个良好的baseline
else:
baseline=0 #这里不使用baseline的话baseline就设置为0,如果上面的q_true不用true_reward抬高的话就没办法区分有没有使用baseline了
self.q_estimation+=self.step_size*(reward-baseline)*(one_hot-self.action_prob) #梯度赌博机更新状态价值估计
else:
self.q_estimation[action]+=self.step_size*(reward-self.q_estimation[action]) #使用固定步长更新状态价值
return reward
def simulate(runs,time,bandits):
rewards=np.zeros((len(bandits),runs,time)) #接收不同赌博机每一轮每一步的回报,方便制成平均回报来画图以对比算法
best_action_count=np.zeros(rewards.shape) #计算选择到最佳动作的数量,为算法对比做准备
for i,bandits in enumerate(bandits): #开始对每个选择不同算法和参数的赌博机进行循环
for r in trange(runs): #对runs个不同的赌博机(算法和超参数相同,奖励分布不同)进行独立实验
bandits.reset()
for t in range(time): #对每个赌博机进行time次实验
action=bandits.act() #赌博机选择动作
reward=bandits.step(action) #返回每个动作的reward
rewards[i,r,t]=reward #把reward放到相应的索引位置方便之后对比
if action==bandits.best_action:
best_action_count[i,r,t]=1 #当赌博机选到最佳动作时+1(最佳动作在赌博机初始化的时候就已经得到)
mean_best_action_counts=best_action_count.mean(axis=1) #计算每个赌博机平均选到最佳动作的概率
mean_rewards=rewards.mean(axis=1) #计算每个赌博机收到的平均回报
return mean_best_action_counts,mean_rewards
def figure_2_1():
plt.violinplot(dataset=np.random.randn(200, 10) + np.random.randn(10))
plt.xlabel("Action")
plt.ylabel("Reward distribution")
plt.savefig('figure_2_1.png')
plt.close()
def figure_2_2(runs=2000, time=1000): #对比不同epsilon下的训练情况
epsilons = [0, 0.1, 0.01]
bandits = [Bandit(epsilon=eps, sample_average=True) for eps in epsilons] #这里用了一个list存储了三个相同参数的赌博机(除了epsilon),方便下面迭代对比
best_action_counts, rewards = simulate(runs, time, bandits)
plt.figure(figsize=(10, 20))
plt.subplot(2, 1, 1)
for eps, rewards in zip(epsilons, rewards):
plt.plot(rewards, label='epsilon = %.02f' % (eps))
plt.xlabel('steps')
plt.ylabel('average reward')
plt.legend() #绘制三个赌博机在epsilon不同的情况下的平均奖励对比图
plt.subplot(2, 1, 2)
for eps, counts in zip(epsilons, best_action_counts):
plt.plot(counts, label='epsilon = %.02f' % (eps))
plt.xlabel('steps')
plt.ylabel('% optimal action')
plt.legend()
plt.savefig('figure_2_2.png')
plt.close() #绘制三个赌博机在epsilon不同的情况下最佳动作选择百分比的对比图
def figure_2_3(runs=2000, time=1000): #对比乐观初始值的作用
bandits = []
bandits.append(Bandit(epsilon=0, initial=5, step_size=0.1))
bandits.append(Bandit(epsilon=0.1, initial=0, step_size=0.1)) #创建两个赌博机,一个使用乐观初始值5,但是不用epsilon-贪婪进行探索,一个不使用乐观初始值,但是用epsilon探索
best_action_counts, _ = simulate(runs, time, bandits)
plt.plot(best_action_counts[0], label='epsilon = 0, q = 5')
plt.plot(best_action_counts[1], label='epsilon = 0.1, q = 0')
plt.xlabel('Steps')
plt.ylabel('% optimal action')
plt.legend()
plt.savefig('figure_2_3.png')
plt.close() #绘制两个赌博机最佳动作选择百分比的对比图
def figure_2_4(runs=2000, time=1000): #对比基于UCB的动作选择的作用
bandits = []
bandits.append(Bandit(epsilon=0, UCB_parameter=2, sample_average=True)) #创建一个使用基于UCB的动作选择的赌博机
bandits.append(Bandit(epsilon=0.1, sample_average=True)) #创建一个基于epsilon-贪婪的赌博机
_, average_rewards = simulate(runs, time, bandits)
plt.plot(average_rewards[0], label='UCB c = 2')
plt.plot(average_rewards[1], label='epsilon greedy epsilon = 0.1')
plt.xlabel('Steps')
plt.ylabel('Average reward')
plt.legend()
plt.savefig('figure_2_4.png')
plt.close() #绘制两个赌博机的平均收益
def figure_2_5(runs=2000, time=1000): #对比梯度赌博机中是否使用baseline的结果
bandits = []
bandits.append(Bandit(gradient=True, step_size=0.1, gradient_baseline=True, true_reward=4))
bandits.append(Bandit(gradient=True, step_size=0.1, gradient_baseline=False, true_reward=4))
bandits.append(Bandit(gradient=True, step_size=0.4, gradient_baseline=True, true_reward=4))
bandits.append(Bandit(gradient=True, step_size=0.4, gradient_baseline=False, true_reward=4)) #创建四个赌博机,分别把α设置为两个0.1和两个0.4,其中一个使用baseline一个不使用
best_action_counts, _ = simulate(runs, time, bandits)
labels = ['alpha = 0.1, with baseline',
'alpha = 0.1, without baseline',
'alpha = 0.4, with baseline',
'alpha = 0.4, without baseline']
for i in range(len(bandits)):
plt.plot(best_action_counts[i], label=labels[i])
plt.xlabel('Steps')
plt.ylabel('% Optimal action')
plt.legend()
plt.savefig('figure_2_5.png')
plt.close()
def figure_2_6(runs=2000, time=1000): #绘制四种方法的参数研究图
labels = ['epsilon-greedy', 'gradient bandit',
'UCB', 'optimistic initialization']
generators = [lambda epsilon: Bandit(epsilon=epsilon, sample_average=True),
lambda alpha: Bandit(gradient=True, step_size=alpha, gradient_baseline=True),
lambda coef: Bandit(epsilon=0, UCB_parameter=coef, sample_average=True),
lambda initial: Bandit(epsilon=0, initial=initial, step_size=0.1)]
parameters = [np.arange(-7, -1, dtype=np.float),
np.arange(-5, 2, dtype=np.float),
np.arange(-4, 3, dtype=np.float),
np.arange(-2, 3, dtype=np.float)]
bandits = []
for generator, parameter in zip(generators, parameters):
for param in parameter:
bandits.append(generator(pow(2, param)))
_, average_rewards = simulate(runs, time, bandits)
rewards = np.mean(average_rewards, axis=1)
i = 0
for label, parameter in zip(labels, parameters):
l = len(parameter)
plt.plot(parameter, rewards[i:i+l], label=label)
i += l
plt.xlabel('Parameter(2^x)')
plt.ylabel('Average reward')
plt.legend()
plt.savefig('figure_2_6.png')
plt.close()
if __name__ == '__main__':
figure_2_1()
figure_2_2()
figure_2_3()
figure_2_4()
figure_2_5()
figure_2_6()