【深度学习】初识ndarray
文章目录
- 前言
- 1. 矩阵操作
-
- 1.1 ndarray
- 1.2 创建行向量
- 1.3 改变张量的形状
- 1.4 获取张量中的元素个数
- 2. 创建矩阵
-
- 2.1 创建一个全是0的矩阵
- 2.2 创建一个全是1的矩阵
- 2.3 创建随机数矩阵
- 3. 矩阵运算
-
- 3.1 矩阵的加减乘除运算
- 3.2 矩阵元素类型转换
- 3.3 矩阵连接
- 4. 矩阵的索引
-
- 4.1 矩阵的标量索引
- 4.2 矩阵的向量索引
- 4.3 更加精确的索引
- 5. 内存节省
- 总结
前言
?? 主要介绍pytorch中对于ndarray的一些基础操作;
1. 矩阵操作
1.1 ndarray
?? ndarray(N-dimensional array)意思是n维数组;
?? n维数组,也称为张量(tensor)或矩阵(matrix);
?? 实际上三者略有不同,我们暂时不区分,在本文中数组、张量和矩阵为同义词;
?? 一个零维数组,也就是一个点,我们称作标量(scalar);一个一维数组,也就是一行或者一列,我们称作向量(vector);一个二维的数组,我们称作矩阵(matrix);
1.2 创建行向量
?? 代码如下:
x = torch.arange(12)#12表示从一个[0,11]的区间,创建的是一个从小到大排列的整型向量;
x
?? 输出结果为:

1.3 改变张量的形状
?? 张量的形状可以改变,比如把一个1 X 12的张量改为一个3 X 4的张量;
?? 代码如下:
X = x.reshape(3, 4)
X
?? 输出结果为:

?? 对于二维张量来说,如果知道张量的元素个数,行数和列数只需知道一个,我们就可以确定另一个,所以我们可以只输入行数或者列数,另一个用-1代替;


1.4 获取张量中的元素个数
?? 获取张量中的元素个数,我们使用numel函数(number of elements),代码如下:
x.numel()#x是我们之前在x=torch.arange(12)中创建的向量;
?? 输出结果为:

2. 创建矩阵
2.1 创建一个全是0的矩阵
?? 代码如下:
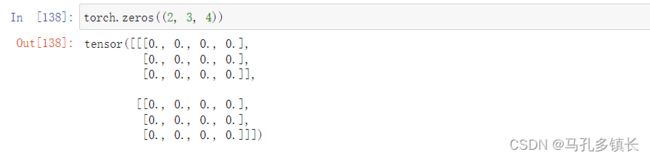
torch.zeros((2, 3, 4))#2表示二维数组的个数,3表示行数,4表示列数;
?? 输出结果为:
2.2 创建一个全是1的矩阵
?? 代码如下:
torch.ones((2, 3, 4))
?? 输出结果为:

2.3 创建随机数矩阵
?? 代码如下:
torch.randn(2 ,3, 4)
?? 输出结果为:

3. 矩阵运算
3.1 矩阵的加减乘除运算
?? 我们可以对两个相同形状的矩阵进行加减乘除运算;
?? 代码如下:
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
?? 输出结果为:

3.2 矩阵元素类型转换
?? 代码如下:
X = torch.arange(12, dtype=torch.float32)
X
?? 输出结果为:

3.3 矩阵连接
?? 代码如下:
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)#dim=0表示按行连接,dim=1表示按列连接;
?? 输出结果为:

4. 矩阵的索引
4.1 矩阵的标量索引
?? 矩阵的索引就是元素下标,python对于矩阵中标量的索引与C语言相同;
?? 代码如下:
X[1,3]#表示矩阵x的第二行第四列元素;
??输出结果为:

4.2 矩阵的向量索引
?? 与标量索引不同的是,python对于向量元素下标的标记方式是把“,”换成“:”,采用的是左闭右开区间,如x[1:3]表示矩阵x的第二行第三行的元素,用数学表达式表示也就是[1,3);
?? 代码入下:
X[1:3]
?? 输出结果为:

?? 访问某一列向量时,使用矩阵名称[:,n],n为列的下标;
?? 代码如下:
X[:,1]
?? 输出结果为:

?? 如果不写逗号右边的数,会默认为输出整个矩阵;

4.3 更加精确的索引
?? 若想要一个更加精确的索引区域,我们还可以在逗号两边的":"上做文章;
??我们已经知道,X[:,:]输出的是整个矩阵X,那么如果我们输入 下列代码会有什么不同呢?
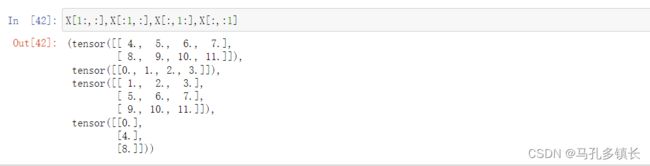
X[1:,:],X[:1,:],X[:,1:],X[:,:1]
?? 输出结果为:
?? 我们可以画图对比一下四种索引的区别;

?? X[:,:]表示整个矩阵,我们可以在逗号左边添加数字对行进行操作;在逗号左边的冒号左边添加数字“1”,表示返回范围为[1,n+1]的矩阵(n为最后一行的下标);
?? 在逗号左边的冒号的右边添加数字“1”,表示返回范围为[0,1)的矩阵;
?? 在逗号右边添加数字对列进行操作;在逗号的右边的冒号的左边添加数字“1”,表示返回范围为[1,n+1]的矩阵(n为最后一列的下标);
?? 在逗号的右边冒号的右边添加数字“1”,表示返回范围为[0,1)的矩阵;
?? 我们也可以在逗号的左右两边的冒号的左右两边都添加数字,比如X[1:2,1:3];

?? 逗号左边的[1,2]表示的行下标的范围是[1,2);逗号右边表示的列下标的范围是[1,3),取它们的交集,所以为tensor[5,6],这就是更精确的数据处理;
5. 内存节省
?? 对于变量X,Y,进行“Y=X+Y”或“Y+=X”运算时,python与C的逻辑并不同;
?? 在python中,进行“Y=X+Y”或“Y+=X”运算后,会增加一块新的内存“Y”,这块内存与原来的“Y”的地址不同,将“Y+X”的值赋给新的变量“Y”后,旧的“Y”的内存地址将被取消引用,转给引用新的“Y”的地址;
?? 我们可以写一段代码来验证一下:
before = id(Y)
Y=Y+X
id(Y) == before
#若为true,证明内存地址没有改变,否则,证明内存地址改变;
?? 输出结果为:

?? 在C语言中,系统会为每个变量分配内存空间,当改变变量的值时,改变的是内存空间中的值,变量的地址是不改变的。
?? 我们同样可以使用代码来验证一下:
#include
int main() {
int a = 1;
int b = 2;
printf("求和前a的地址为:%p
", &a);
a = a + b;
printf("求和后a的地址为:%p
", &a);
return 0;
}
?? 输出结果为:

?? 这就意味着,当我们使用这种方式计算,就要不断地开辟新的空间,一是容易造成内存浪费;二是可能仍有部分参数在引用旧的“Y”的地址,导致程序运行错误;
?? 那么如何解决这个问题呢?我们可以使用Y[:]=X+Y,就跟C中一样了;
?? 可以用代码再次验证一下:
before = id(Y)
Y[:]=Y+X
id(Y) == before
#若为true,证明内存地址没有改变,否则,证明内存地址改变;
?? 输出结果为:

总结
如果您觉得有用的话,不妨点个赞吧!