电信保温杯笔记——《统计学习方法(第二版)——李航》第4章 朴素贝叶斯法
电信保温杯笔记——《统计学习方法(第二版)——李航》第4章 朴素贝叶斯法
- 论文
- 介绍
- 特点
- 数学基础
-
- 条件概率
- 全概率公式
- 贝叶斯公式
- 先验概率
- 后验概率
- 似然函数
- 极大似然估计(MLE)
- 最大后验概率估计(MAP)
- 贝叶斯估计(BE)
-
- 代价函数
-
- 平方代价函数
- 均匀代价函数
- 极大似然估计、最大后验概率估计和贝叶斯估计的异同
-
- 思路
- 优化目标
- 朴素贝叶斯法原理
- 朴素贝叶斯法的参数估计
- 朴素贝叶斯法步骤
-
- 例子
- 朴素贝叶斯参数估计技巧
-
- 例子
- 本章概要
- 相关视频
- 相关的笔记
- 相关代码
-
- pytorch
- tensorflow
-
- keras
- pytorch API:
- tensorflow API
论文
电信保温杯笔记——《统计学习方法(第二版)——李航》
没有找到对应的原始论文。
介绍
本文是对原书的精读,会有大量原书的截图,同时对书上不详尽的地方进行细致解读与改写。
朴素贝叶斯法(naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布,然后基于此模型,对给定的输入 x x x,利用贝叶斯定理求出后验概率最大的输出 y y y。
朴素贝叶斯法与贝叶斯估计(Bayesian estimation)是不同的概念;
特征条件独立假设的成立时,该模型称为朴素贝叶斯模型;
特征条件独立假设的不成立时,该模型称为贝叶斯网络。

特点
朴素贝叶斯法实现简单、学习与预测的效率都很高,是一种常用的方法。
数学基础
可以把事件A、B分别理解为
| A | 结果、证据 、(乌云、卷积云等) |
|---|---|
| B | 原因、结论、(下雨、打雷等) |
条件概率
P ( B ∣ A ) = P ( A B ) P ( A ) P(B|A)=\frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
全概率公式
P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i ) P(A)=\sum\limits_{i=1}^n P(A|B_i)P(B_i) P(A)=i=1∑nP(A∣Bi)P(Bi)
贝叶斯公式
又称贝叶斯定理:
P ( B i ∣ A ) = P ( A ∣ B i ) P ( B i ) ∑ j = 1 n P ( A ∣ B j ) P ( B j ) , i = 1 , 2 , . . . , n . P(B_i|A)=\frac{P(A|B_i)P(B_i)}{\sum\limits_{j=1}^n P(A|B_j)P(B_j)},i=1,2,...,n. P(Bi∣A)=j=1∑nP(A∣Bj)P(Bj)P(A∣Bi)P(Bi),i=1,2,...,n.
当 i = 1 i=1 i=1时,上式退化为:
P ( B ∣ A ) = P ( A ∣ B ) P ( B ) P ( A ) . ( 1 ) P(B|A)=\frac{P(A|B)P(B)}{P(A)}.\quad\quad\quad\quad\quad(1) P(B∣A)=P(A)P(A∣B)P(B).(1)
先验概率
此时,公式(1)中的 P ( B ) P(B) P(B) 称为先验概率,是指根据以往经验和分析得到的概率,是在本次实验、验证之前就知道概率是固定的,不会随着观测数据或观测到的特征而改变,是频率派的主张。比如判断今日是否下雨,就以这个地区下雨的概率作为判断的依据;比如抛硬币正面的概率,则认为是1/2。
后验概率
此时,公式(1)中的 P ( B ∣ A ) P(B|A) P(B∣A) 称为后验概率,是在给定观测值 A A A 的条件下 B B B 发生的概率,意味着事件 B B B 的发生概率不能盲目的遵循以往的经验,还要基于目前观测到的特征,这是贝叶斯派的主张。比如判断今日是否下雨,在观测到事件 A A A 乌云的条件下,下雨的概率就不能盲目地认为是这个地区下雨的概率了;再比如我们观测到一枚硬币抛1w次,正面是7k次,那么这个硬币很有可能就是做工有问题的,也不能简单地认为正面的概率就是1/2了。
似然函数
此时,公式(1)中的 P ( A ∣ B ) P(A|B) P(A∣B) 称为似然函数,事件 A A A 作为结果,事件 B B B 作为原因的话,它的意义就是,基于这个原因,发生这样的结果的概率,这就是似然的意思——像这样,发生像这样的结果的概率。下面还会解释一次。
极大似然估计(MLE)
引入下面的函数
P ( X ∣ θ ) = ∏ i = 1 n P ( x i ∣ θ ) P(X|\theta)=\prod\limits_{i=1}^n P(x_i|\theta) P(X∣θ)=i=1∏nP(xi∣θ)
X X X:代表观测数据,观测结果等。例如上面下雨的例子,那么这里就可以代表 X = ( x 1 , x 2 , . . . , x n ) = X=(x_1,x_2,...,x_n)= X=(x1,x2,...,xn)=(一号下雨,二号下雨,三号不下雨…),对一段时间每天下雨情况的观测;
θ \theta θ:代表模型的参数。在下雨的例子中,可以代表地区的经度,维度,月份,人口分布等;
P ( x ∣ θ ) P(x|\theta) P(x∣θ):代表单次结果的预测模型,在下雨的例子中就是今天下雨的概率。
当模型的参数 θ \theta θ 已知,此时函数 P ( X ∣ θ ) P(X|\theta) P(X∣θ) 是观测数据概率分布;
当模型的参数 θ \theta θ 未知,此时函数 P ( X ∣ θ ) P(X|\theta) P(X∣θ) 是似然函数;
是概率分布还是似然函数,只是同一条式子的不同说法,关键不同在于模型的参数是否已知。
极大似然估计(Maximum Likelihood Estimate,MLE),就是已知观测数据 X X X 和预测模型 P ( x ∣ θ ) P(x|\theta) P(x∣θ),可得出似然函数 P ( X ∣ θ ) P(X|\theta) P(X∣θ),当似然函数取得最大值时,得到参数 θ o p t \theta_{opt} θopt,即
θ o p t = arg max θ P ( X ∣ θ ) . ( 2 ) \theta_{opt} = {\underset {\theta}{\operatorname {arg\,max} }}\,P(X|\theta).\quad\quad\quad\quad\quad(2) θopt=θargmaxP(X∣θ).(2)
将 θ o p t \theta_{opt} θopt 带入预测模型得到 P ( x ∣ θ o p t ) P(x|\theta_{opt}) P(x∣θopt),就可以用于预测 x x x 发生的概率。在下雨的例子中,就是已知过去一段时间下雨的记录,还有当天是否下雨的预测模型,得到这些天这样下雨的可能性,探究地理信息,推测 θ o p t = \theta_{opt}= θopt= (这样的经度,这样的维度,这样的人口分布等),使这样下雨的可能性最大,以此地理信息用于预测当地今天是否下雨。总之,就是使结果的可能性最大,反推此时的原因。
最大后验概率估计(MAP)
最大后验概率估计(Maximum a posteriori estimation,MAP),就是已知观测数据 X X X 、预测模型 P ( x ∣ θ ) P(x|\theta) P(x∣θ)、参数概率密度 P ( θ ) P(\theta) P(θ),求发生这种结果,最大可能性是由于什么参数,就是求后验概率 P ( θ ∣ X ) P(\theta|X) P(θ∣X) 的最大值,即
θ o p t = arg max θ P ( θ ∣ X ) = arg max θ P ( X ∣ θ ) P ( θ ) P ( X ) \theta_{opt} = {\underset {\theta}{\operatorname {arg\,max} }}\,P(\theta|X) = {\underset {\theta}{\operatorname {arg\,max} }}\,\frac{P(X|\theta) P(\theta) }{P(X) } θopt=θargmaxP(θ∣X)=θargmaxP(X)P(X∣θ)P(θ)
由于 P ( X ) P(X) P(X) 是与参数 θ \theta θ 无关的量,所以上式可以化简成
θ o p t = arg max θ P ( θ ∣ X ) = arg max θ P ( X ∣ θ ) P ( θ ) . ( 3 ) \theta_{opt} = {\underset {\theta}{\operatorname {arg\,max} }}\,P(\theta|X) = {\underset {\theta}{\operatorname {arg\,max} }}\,P(X|\theta) P(\theta).\quad\quad\quad\quad\quad(3) θopt=θargmaxP(θ∣X)=θargmaxP(X∣θ)P(θ).(3)
将 θ o p t \theta_{opt} θopt 带入预测模型得到 P ( x ∣ θ o p t ) P(x|\theta_{opt}) P(x∣θopt),就可以用于预测 x x x 发生的概率。
贝叶斯估计(BE)
贝叶斯估计(Bayesian Estimation,BE)认为,实际环境中待估计量 θ \theta θ 可能是一个随机变量,并且概率密度 P ( θ ) P(\theta) P(θ) 已知。这时极大似然估计依然可用,但未能充分利用待估计量的信息。
代价函数
在估计某个参量 θ \theta θ 时,噪声的影响会使估计产生误差,这种噪声从何而来,以下雨为例子,人口的迁移会造成人口密度的变化,工业排放也会引起空气的变化,地壳运动,板块移动,可能导致经纬度也会有稍微的变化,这个时候参数 θ \theta θ 就是一个随机变量, θ = θ 0 + σ \theta = \theta_0 + \sigma θ=θ0+σ, σ \sigma σ 是噪声。
估计误差是要付出代价的,这种代价可以用代价函数来加以描述,记为 c ( θ , θ ^ ) c(\theta, \hat{\theta}) c(θ,θ^), θ \theta θ 是实际值, θ ^ \hat{\theta} θ^是估计值。代价函数有多种,这里只列举其中2种:
平方代价函数
c ( θ , θ ^ ) = ( θ , θ ^ ) 2 c(\theta, \hat{\theta}) = (\theta, \hat{\theta})^2 c(θ,θ^)=(θ,θ^)2
均匀代价函数
c ( θ , θ ^ ) = { 1 ∣ θ − θ ^ ∣ ≥ ϵ / 2 0 ∣ θ − θ ^ ∣ < ϵ / 2 ϵ 为一常数 c(\theta, \hat{\theta}) = \begin{cases} 1 \quad\quad |\theta-\hat{\theta}| \ge \epsilon /2\\ 0 \quad\quad |\theta-\hat{\theta}| < \epsilon /2 \end{cases} \quad\quad \epsilon \text{为一常数} c(θ,θ^)={1∣θ−θ^∣≥ϵ/20∣θ−θ^∣<ϵ/2ϵ为一常数
给定观测数据 X X X,估计误差的平均代价为:
c ˉ ( θ ∣ X ) = ∫ − ∞ ∞ c ( θ , θ ^ ( X ) ) p ( θ ∣ X ) d θ . \bar{c}(\theta|X) = \int_{-\infty}^{\infty} c(\theta, \hat{\theta}(X))p(\theta|X)\, d\theta. cˉ(θ∣X)=∫−∞∞c(θ,θ^(X))p(θ∣X)dθ.
此时贝叶斯估计的最优值为:
θ o p t = arg min θ c ˉ ( θ ∣ X ) = arg min θ ∫ − ∞ ∞ c ( θ , θ ^ ( X ) ) p ( θ ∣ X ) d θ . ( 4 ) \theta_{opt} = {\underset {\theta}{\operatorname {arg\,min} }}\,\bar{c}(\theta|X) = {\underset {\theta}{\operatorname {arg\,min} }}\, \int_{-\infty}^{\infty} c(\theta, \hat{\theta}(X))p(\theta|X)\, d\theta.\quad\quad\quad\quad\quad(4) θopt=θargmincˉ(θ∣X)=θargmin∫−∞∞c(θ,θ^(X))p(θ∣X)dθ.(4)
将 θ o p t \theta_{opt} θopt 带入预测模型得到 P ( x ∣ θ o p t ) P(x|\theta_{opt}) P(x∣θopt),就可以用于预测 x x x 发生的概率。
代价函数不同时,贝叶斯估计的结果也不同。
极大似然估计、最大后验概率估计和贝叶斯估计的异同
思路
都是已知模型求参数。
极大似然估计(MLE):使当前的结果 P ( X ∣ θ ) P(X|\theta) P(X∣θ) 发生的可能性最大,再求此时的参数 θ \theta θ,它认为参数 θ \theta θ 是一个常量;
最大后验概率估计(MAP):直接求最可能的原因 P ( θ ∣ X ) P(\theta|X) P(θ∣X),以导致这样的结果的发生;
贝叶斯估计(BE):求猜错成本最低的原因,即使参数的估计值 θ ^ ( X ) \hat{\theta}(X) θ^(X) 造成的估计误差的代价最小,求此时的 θ ^ ( X ) \hat{\theta}(X) θ^(X),因为它认为参数 θ \theta θ 是一个随机变量。
优化目标
极大似然估计(MLE):
θ o p t = arg max θ P ( X ∣ θ ) . ( 2 ) \theta_{opt} = {\underset {\theta}{\operatorname {arg\,max} }}\,P(X|\theta).\quad\quad\quad\quad\quad(2) θopt=θargmaxP(X∣θ).(2)
最大后验概率估计(MAP):
θ o p t = arg max θ P ( X ∣ θ ) P ( θ ) . ( 3 ) \theta_{opt} = {\underset {\theta}{\operatorname {arg\,max} }}\,P(X|\theta) P(\theta).\quad\quad\quad\quad\quad(3) θopt=θargmaxP(X∣θ)P(θ).(3)
贝叶斯估计(BE):
θ o p t = arg min θ ∫ − ∞ ∞ c ( θ , θ ^ ( X ) ) p ( θ ∣ X ) d θ . ( 4 ) \theta_{opt} = {\underset {\theta}{\operatorname {arg\,min} }}\, \int_{-\infty}^{\infty} c(\theta, \hat{\theta}(X))p(\theta|X)\, d\theta.\quad\quad\quad\quad\quad(4) θopt=θargmin∫−∞∞c(θ,θ^(X))p(θ∣X)dθ.(4)
极大似然估计与最大后验概率估计只相差了一个 P ( θ ) P(\theta) P(θ),当参数 θ \theta θ 的分布为均匀分布时,极大似然估计等同最大后验概率估计。最大后验概率估计实际上是在最大似然估计的基础上利用待估计参数的先验知识进行修正。
最大后验概率估计与贝叶斯估计都考虑了待估计参数 θ \theta θ 的先验知识 P ( θ ) P(\theta) P(θ),而最大后验概率估计是贝叶斯估计的代价函数为均匀代价的情况,且代价函数的0代价点在最大后验概率估计的估计值 θ m a p \theta_{map} θmap :
c ( θ , θ ^ ) = { 1 ∣ θ m a p − θ ^ ∣ ≥ ϵ / 2 0 ∣ θ m a p − θ ^ ∣ < ϵ / 2 ϵ 为一常数 c(\theta, \hat{\theta}) = \begin{cases} 1 \quad\quad |\theta_{map}-\hat{\theta}| \ge \epsilon /2\\ 0 \quad\quad |\theta_{map}-\hat{\theta}| < \epsilon /2 \end{cases} \quad\quad \epsilon \text{为一常数} c(θ,θ^)={1∣θmap−θ^∣≥ϵ/20∣θmap−θ^∣<ϵ/2ϵ为一常数
将代价函数带入公式(4)可知, θ ^ = θ m a p \hat{\theta}=\theta_{map} θ^=θmap 时代价最小,此时最大后验概率估计等同贝叶斯估计。
朴素贝叶斯法原理
给定输入 X X X,最大后验概率的那个类就是预测的类别 c o p t c_{opt} copt:
c o p t = arg max c k P ( c k ∣ X ) . c_{opt} = {\underset {c_k}{\operatorname {arg\,max} }}\,P(c_k|X) . copt=ckargmaxP(ck∣X).
要计算上式就要计算:
c o p t = arg max c k P ( c k ∣ X ) = arg max c k P ( X ∣ c k ) P ( c k ) P ( X ) c_{opt} = {\underset {c_k}{\operatorname {arg\,max} }}\,P(c_k|X) = {\underset {c_k}{\operatorname {arg\,max} }}\,\frac{P(X|c_k)P(c_k)}{P(X)} copt=ckargmaxP(ck∣X)=ckargmaxP(X)P(X∣ck)P(ck)
下面就是计算上式的过程:


![]()

朴素贝叶斯法的参数估计
![]()
就是估计式子(4.7)中的量。

P ( Y = c k ) P(Y=c_k) P(Y=ck),有 K K K 个类别,就要储存 K K K 个参数。
![]()

P ( X ( j ) = a j l ∣ Y = c k ) P(X^{(j)}=a_{jl}|Y=c_k) P(X(j)=ajl∣Y=ck),有 K ∑ j = 1 n S j K\sum_{j=1}^n S_j K∑j=1nSj 种情况,就要储存 K ∑ j = 1 n S j K\sum_{j=1}^n S_j K∑j=1nSj 个参数。
朴素贝叶斯法步骤

例子

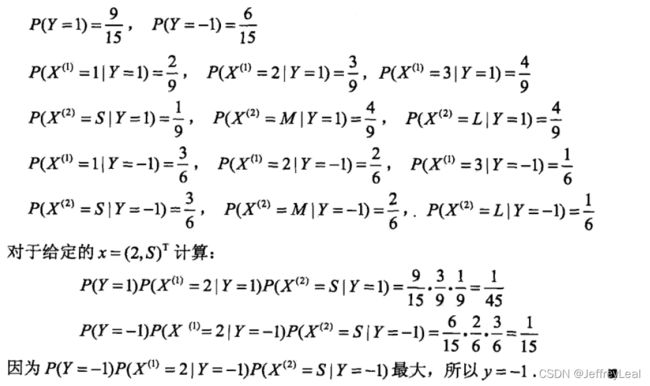
朴素贝叶斯参数估计技巧
由于特征维度高,每个特征的取值范围也很大,分类类别也多,很容易出现样本 X X X 没有在数据集中出现过得情况,如果直接令某个特征值的条件概率 P ( X ( j ) = a j l ∣ Y = c k ) = 0 P(X^{(j)}=a_{jl}|Y=c_k) = 0 P(X(j)=ajl∣Y=ck)=0 的话,在累乘计算 P ( X ∣ Y = c k ) P(X|Y=c_k) P(X∣Y=ck) 的时候就会出现等于0的情况,但概率很小和0在计算上天差地别,为解决这个问题,可以将所有不同特征取值以及类别的情况都人为添加一个样本,这样概率就不为零,总体上也没有太大的影响。
书上说这一部分为贝叶斯估计:

例子

本章概要


相关视频
相关的笔记
hktxt /Learn-Statistical-Learning-Method
详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
相关代码
Dod-o /Statistical-Learning-Method_Code,在实际代码中,计算概率的累乘时,有可能由于接近0的累乘项 P ( X ( j ) = a j l ∣ Y = c k ) P(X^{(j)}=a_{jl}|Y=c_k) P(X(j)=ajl∣Y=ck) 太多,而导致计算结果 ∏ j = 1 n P ( X ( j ) = a j l ∣ Y = c k ) \prod _{j=1}^n P(X^{(j)}=a_{jl}|Y=c_k) ∏j=1nP(X(j)=ajl∣Y=ck)下溢,即小数实在太小了,计算机的位数也捕捉不了。使用 ∑ j = 1 n log P ( X ( j ) = a j l ∣ Y = c k ) \sum _{j=1}^n \log P(X^{(j)}=a_{jl}|Y=c_k) ∑j=1nlogP(X(j)=ajl∣Y=ck),就能解决这个问题,保持了计算结果的单调性,又不会下溢。