Hbase的表查询操作
目录
1.scan
2.get
1.filterBySingleColumnValueFilter(String tablename, String strF, String strC, String strClass)
1.1基本代码
1.2 过滤值的大小范围
RegexStringComparator
SubstringComparator
BinaryPrefixComparator
比较运算符
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP 排除所有
1.scan
可以不用输入rowkey,能按照一定的规则查出来对应的rowkey和值
public void scan(String tablename,String cf,String column) throws Exception{
HTable table=new HTable(conf,tablename);
Scan s=new Scan();
s.setStartRow(Bytes.toBytes("0"));//可以限定rowkey的范围,字典序
s.setStopRow(Bytes.toBytes("g"));
// s.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
ResultScanner res=table.getScanner(s);
for(Result r:res) {
byte[] row=r.getRow();
byte[] val=r.getValue(Bytes.toBytes(cf), Bytes.toBytes(column));
System.out.println("Scan:"+Bytes.toString(row)+"的"+ column
+" values is "+Bytes.toString(val));
}
res.close();
table.close();
}2.get
需要传入这4个字段,能找出对应的值
String tablename,String rowkey,String cf(列族),String cq(列限定符)
public void get(String tablename,String row,String info,String name) throws Exception{
HTable table=new HTable(conf,tablename);
Get g=new Get(Bytes.toBytes(row));
Result result = table.get(g);
byte[] val = result.getValue(Bytes.toBytes(info),Bytes.toBytes(name));
System.out.println(info+" "+name+" "+"Values =" + Bytes.toString(val));
}下面是一些过滤器的使用
1.filterBySingleColumnValueFilter(String tablename, String strF, String strC, String strClass)
1.1基本代码
public void filterBySingleColumnValueFilter(String tablename, String strF, String strC, String strClass) throws Exception
{
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
SingleColumnValueFilter sf =
new SingleColumnValueFilter(Bytes.toBytes(strF),
Bytes.toBytes(strC), CompareOp.NOT_EQUAL,
Bytes.toBytes(strClass));
s.setFilter(sf);
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
byte[] row = r.getRow();
byte[] value = r.getValue(Bytes.toBytes(strF), Bytes.toBytes(strC));
System.out.println("Filter: " + Bytes.toString(row) + "的 " + strC + " " + Bytes.toString(value));
}
rs.close();
table.close();
}好像不能设置多个列族。。。
1.2 过滤值的大小范围
public void filterBySingleColumnValueFilter(String tablename, String strF, String strC,String dayu,String xiaoyu) throws Exception
{
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
//组成区间过滤
SingleColumnValueFilter filter1 =
new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.LESS_OR_EQUAL,Bytes.toBytes(xiaoyu));
SingleColumnValueFilter filter2 =
new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.GREATER_OR_EQUAL,Bytes.toBytes(dayu));
filterList.addFilter(filter1);
filterList.addFilter(filter2);
s.setFilter(filterList);
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
byte[] row = r.getRow();
byte[] value = r.getValue(Bytes.toBytes(strF), Bytes.toBytes(strC));
System.out.println("Filter: " + Bytes.toString(row) + "的 " + strC + " " + Bytes.toString(value));
}
rs.close();
table.close();
}
关键代码
SingleColumnValueFilter filter1 =
new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.LESS_OR_EQUAL,Bytes.toBytes(xiaoyu));
SingleColumnValueFilter filter2 =
new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.GREATER_OR_EQUAL,Bytes.toBytes(dayu));
可设置rowkey的范围以及返回的条数
Filter filter = new PageFilter(2); // Hbase获取前2条记录,只能放到后面,在追加的列主前面无效
s.setFilter(filter);
s.setStartRow(Bytes.toBytes("0"));
s.setStopRow(Bytes.toBytes("3"));
注意:追加列族,如果不写,就默认追加全部,如果写了,就默认查出来的数据就是你追加的数据限定,不会出现其他的
s.addColumn(Bytes.toBytes("info"), Bytes.toBytes(strC));//追加列族和列
s.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"));//追加列族和列
下面我举个例子:
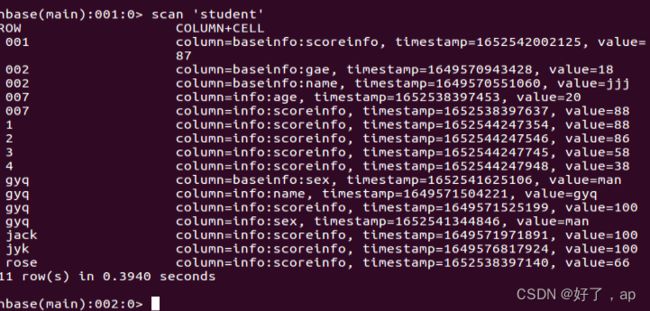
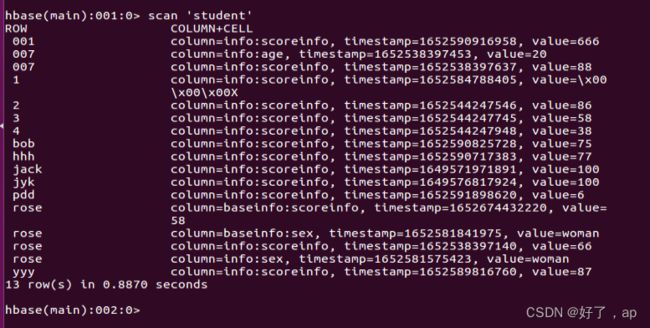
这个是我的表,如果我只追加scoreinfo,

我想查询sex这一列就查不到

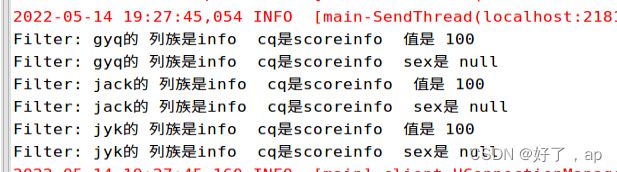
设置过滤器"scoreinfo:60-70的数据,RegexStringComparator匹配正则表达式
RegexStringComparator
RegexStringComparator comp =new RegexStringComparator("^[67][0-9]$");
SingleColumnValueFilter filter_zz = new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.EQUAL, comp);
s.setFilter(filter_zz);找出来scoreinfo中包含6的数字
SubstringComparator
SubstringComparator comp_con = new SubstringComparator("6");//包含6
SingleColumnValueFilter filter_con = new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.EQUAL, comp_con);
s.setFilter(filter_con);
BinaryPrefixComparator
匹配开头,前缀二进制比较器,找出6开头的数据
BinaryPrefixComparator comp_pre =new BinaryPrefixComparator("8".getBytes());//以6开头的
SingleColumnValueFilter filter_pre = new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.EQUAL, comp_pre);
// s.setFilter(filter_pre);我想过滤60到70之间的数据,可以怎么写呢?
方法一:
直接在得到的结果里面加一个判断函数:
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
byte[] row = r.getRow();
byte[] value = r.getValue(Bytes.toBytes(strF), Bytes.toBytes(strC));
if(Integer.valueOf(Bytes.toString(value))>60&&Integer.valueOf(Bytes.toString(value))<70) {
System.out.println("Filter: " + Bytes.toString(row) + "的 " +"列族是"+strF+" cq是"+ strC + " 值是 " + Integer.valueOf(Bytes.toString(value)));
}方法二,用正则表达式,过滤找出60到70的数据
RegexStringComparator comp =new RegexStringComparator("^[67][0-9]$");
SingleColumnValueFilter filter_zz = new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.EQUAL, comp);
s.setFilter(filter_zz);方法三,用比较器,但是有些许问题呢,比如我有个数据是666,它字典序。。。
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
//组成区间过滤
SingleColumnValueFilter filter1 =
new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.LESS_OR_EQUAL,Bytes.toBytes("70"));
SingleColumnValueFilter filter2 =
new SingleColumnValueFilter(Bytes.toBytes(strF), Bytes.toBytes(strC), CompareOp.GREATER_OR_EQUAL,Bytes.toBytes("60"));
filterList.addFilter(filter1);
filterList.addFilter(filter2);
s.setFilter(filterList);