HBase环境搭建与编程实践
HBase环境搭建与编程实践
重要知识点:
1.HBase是一个分布式的、面向列的开源数据库,源于Google的一篇论文《BigTable:一个结构化数据的分布式存储系统》。HBase以表的形式存储数据,表有行和列组成,列划分为若干个列族/列簇(column family)。HBase官方网站(http://hbase.apache.org/)。
2.HBase的运行有三种模式:单机模式、伪分布式模式、分布式模式。
单机模式:在一台计算机上安装和使用HBase,不涉及数据的分布式存储;
伪分布式模式:在一台计算机上模拟一个小的集群;
分布式模式:使用多台计算机实现物理意义上的分布式存储。这里出于学习目的,我们只重点讨论单机模式和伪分布式模式。本节课实验采用伪分布式模式。
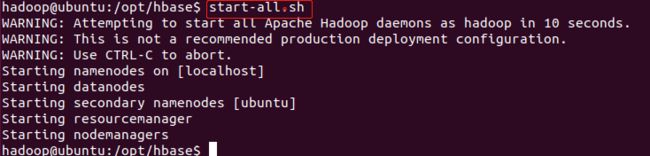
开始此实验之前,要把前面配置的hadoop环境启动。
实验内容与步骤:
一、HBase安装与配置
- HBase下载
网址:http://hbase.apache.org/downloads.html ,建议下载稳定版本。
稳定版下载地址:http://archive.apache.org/dist/hbase/stable/
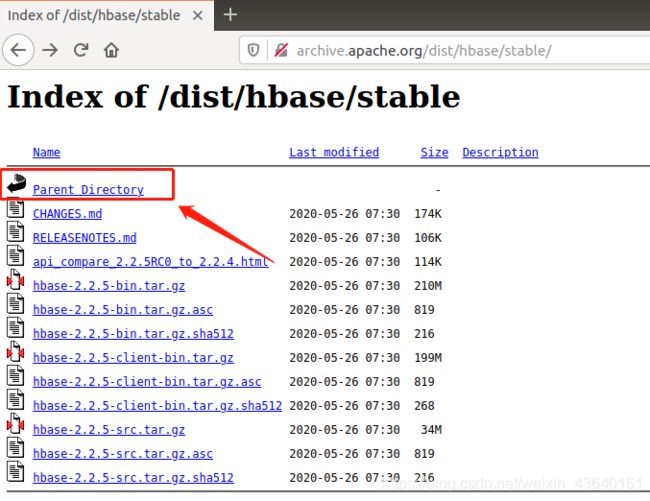
现在稳定版本是 hbase-2.2.5 ,我们此次实验是以hbase-1.2.6.1为例子
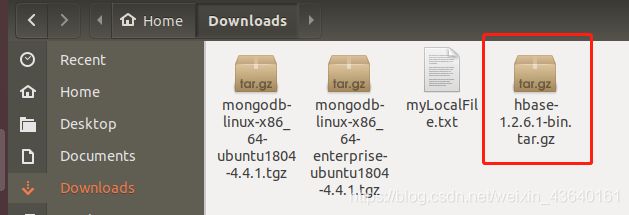
下载完成后,会自动下载到Downloads目录下:
- HBase安装
1)在/opt 目录下面创建文件夹hbase

2)解压安装包hbase-1.2.6.1-bin.tar.gz至路径 /opt/hbase,命令如下:

3)查看是否解压成功
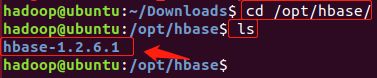
4)配置环境变量
将hbase下的bin目录添加到path中,这样,启动hbase就无需到/opt/hbase/hbase-1.2.6.1目录下,大大的方便了hbase的使用。编辑/etc/profile文件
![]()
如果没有引入过PATH请在/etc/profile文件尾行添加如下内容:
export PATH=$PATH:/opt/hbase/hbase-1.2.6.1/bin
如果已经引入过PATH请在export PATH这行追加/opt/hbase/hbase-1.2.6.1/bin,也可以先设置HBASE_HOME,在配置PATH。这里的“:”是分隔符。如下图:

编辑完成后,再执行source命令使上述配置在当前终端立即生效,命令如下:
![]()
5)添加HBase权限
cd /opt/hbase
终端命令:sudo chown -R hadoop ./hbase-1.2.6.1
#将hbase下的所有文件的所有者改为hadoop,hadoop是当前用户的用户名。
![]()
终端命令:sudo chmod -R 777 ./hbase-1.2.6.1
![]()
6)查看HBase版本,确定hbase安装成功,命令如下:

- HBase配置
HBase有三种运行模式,单机模式、伪分布式模式、分布式模式。作为学习,我们重点讨论单机模式和伪分布式模式。
以下先决条件很重要,比如没有配置JAVA_HOME环境变量,就会报错。
– jdk
– Hadoop( 单机模式不需要,伪分布式模式和分布式模式需要)
– SSH
本实验重点讲伪分布式模式配置。单机模式请自行学习。
伪分布式模式配置:
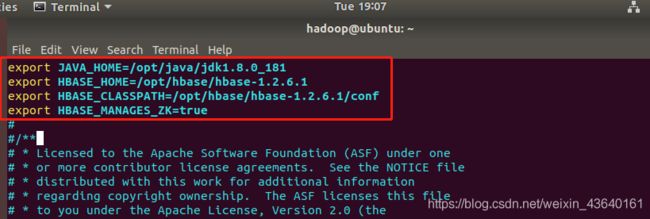
- 配置/opt/hbase/hbase-1.2.6.1/conf/hbase-env.sh。命令如下:
![]()
配置JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK.
HBASE_CLASSPATH设置为本机HBase安装目录下的conf目录.配置HBASE_MANAGES_ZK为true,表示由hbase自己管理zookeeper,不需要单独的zookeeper。
export JAVA_HOME=/opt/java/jdk1.8.0_181
export HBASE_HOME=/opt/hbase/hbase-1.2.6.1
export HBASE_CLASSPATH=/opt/hbase/hbase-1.2.6.1/conf
export HBASE_MANAGES_ZK=true
- 配置/opt/hbase/hbase-1.2.6.1/conf/hbase-site.xml,打开并编辑hbase-site.xml,命令如下:
![]()
修改hbase.rootdir,指定HBase数据在HDFS上的存储路径;将属性hbase.cluter.distributed设置为true。假设当前Hadoop集群运行在伪分布式模式下,在本机上运行,且NameNode运行在9000端口。hbase.rootdir指定HBase的存储目录;hbase.cluster.distributed设置集群处于分布式模式.
hbase.rootdir hdfs://localhost:9000/hbase hbase.cluster.distributed true 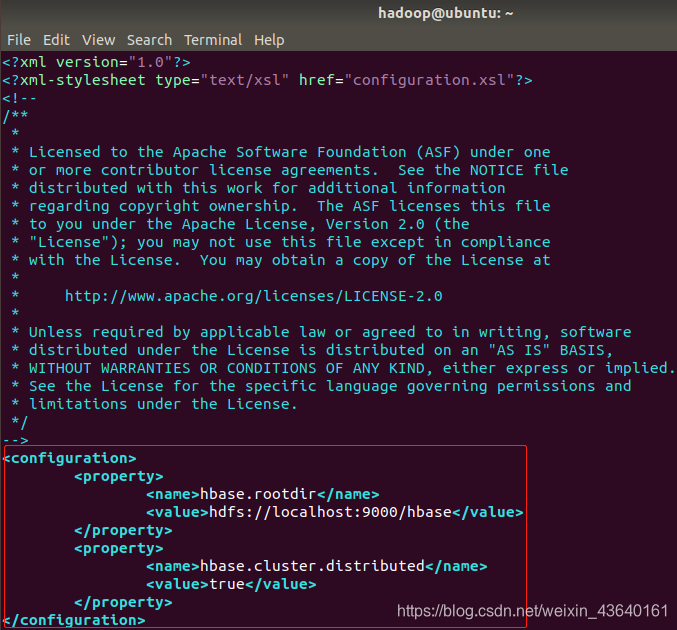- 接下来测试运行HBase。
第1步:首先登陆ssh,之前设置了无密码登陆,因此这里不需要密码;再启动hadoop,如果已经启动hadoop请跳过此步骤。命令如下:
终端命令:start-all.sh
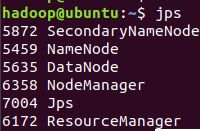
输入命令jps,能看到NameNode,DataNode和SecondaryNameNode都已经成功启动,表示hadoop启动成功,截图如下:
第2步:再启动HBase.命令如下:
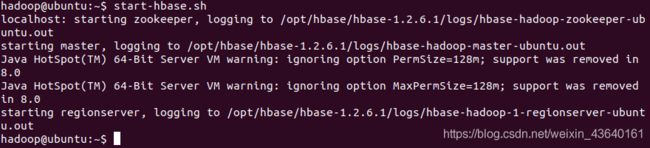
第3步:jps查看是否启动成功:
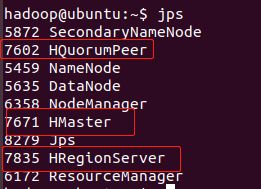
第4步:进入shell界面,测试hbase shell是否可用,命令:hbase shell

如果报slf4j-log4j12-1.7.5冲突错误,请删除/hbase-1.2.6.1/lib目录下的slf4j-log4j12-1.7.5包。原因:该包和hadoop下面的包冲突了。删掉一个即可。
![]()
重新启动hbase shell
第5步:如果要停止HBase运行,命令如下:stop-hbase.sh
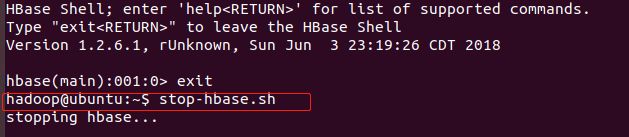
注意:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/opt/hbase)下的logs子目录中的日志文件查看错误原因。
这里启动关闭Hadoop和HBase的顺序一定是:
启动Hadoop—>启动HBase—>关闭HBase—>关闭Hadoop
二、HBase shell命令编程实践
- HBase中创建表
HBase中用create命令创建表,具体如下:
create ‘student’,‘name’,‘sex’,‘age’,‘dept’,‘course’
命令执行截图如下:

此时,即创建了一个“student”表,属性有:name,sex,age,dept,course。因为HBase的表中会有一个系统默认的属性作为行键,无需自行创建,默认为put命令操作中表名后第一个数据。创建完“student”表后,可通过describe命令查看“student”表的基本信息。命令执行截图如下:
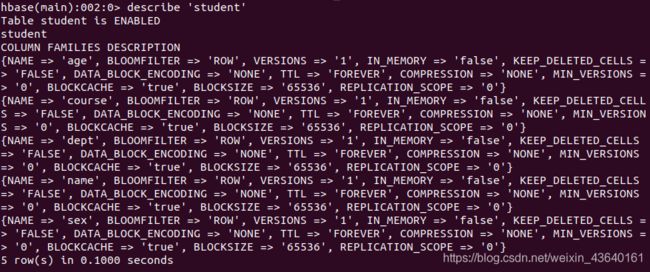
- HBase数据库基本操作
主要练习HBase的增、删、改、查操作。在添加数据时,HBase会自动为添加的数据添加一个时间戳,故在需要修改数据时,只需直接添加数据,HBase即会生成一个新的版本,从而完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的几个版本,保存的版本数可以在创建表的时候指定。
(1)添加数据
HBase中用put命令添加数据,注意:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。
当运行命令:put ‘student’,’18001’,’name’,’zhangsan’时,即为student表添加了学号为18001,名字为zhangsan的一行数据,其行键为18001。shell命令为:
put ‘student’,‘18001’,‘name’,‘zhangsan’
命令执行截图如下,即为student表添加了学号为18001,名字为zhangsan的一行数据,其行键为18001。

Shell命令:
put ‘student’,‘18001’,‘course:math’,‘80’
即为18001行下的course列族的math列添加了一个数据。截图如下:

(2)查看数据
HBase中有两个用于查看数据的命令:
get命令,用于查看表的某一行数据;
scan命令用于查看某个表的全部数据
- get命令
get ‘student’,‘18001’
命令执行截图如下, 返回的是‘student’表‘18001’行的数据。

- scan命令
scan ‘student’
命令执行截图如下, 返回的是‘student’表的全部数据。

(3)删除数据
在HBase中用delete以及deleteall命令进行删除数据操作,它们的区别是:1. delete用于删除一个数据,是put的反向操作;2. delete all操作用于删除一行数据。
-
delete命令
delete ‘student’,‘18001’,‘sex’
命令执行截图如下, 即删除了student表中95001行下的sex列的所有数据。

- deleteall命令
deleteall ‘student’,‘18001’
命令执行截图如下,即删除了student表中的18001行的全部数据。

(4)删除表
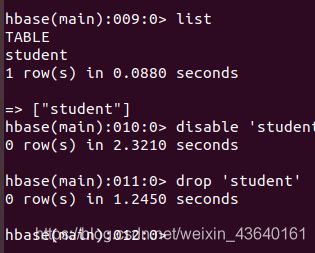
删除表有两步,第一步先让该表不可用,第二步删除表。删除表之前,可以使用list命令查看所有表。命令:
list
disable ‘student’
drop ‘student’
命令执行截图如下:
(5)查询表历史数据
查询表的历史版本,需要两步。
1、在创建表的时候,指定保存的版本数(假设指定为5)
create ‘teacher’,{NAME=>‘username’,VERSIONS=>5}

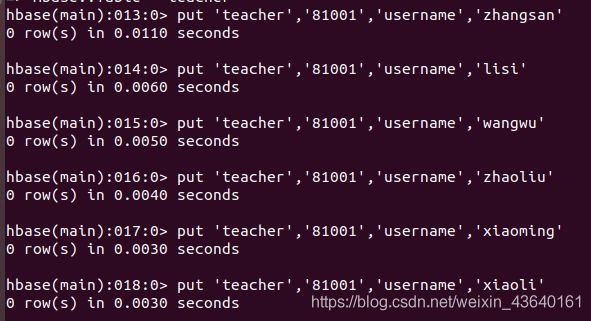
2、插入数据然后更新数据,使其产生历史版本数据,注意:这里插入数据和更新数据都是用put命令
put ‘teacher’,‘81001’,‘username’,‘zhangsan’
put ‘teacher’,‘81001’,‘username’,‘lisi’
put ‘teacher’,‘81001’,‘username’,‘wangwu’
put ‘teacher’,‘81001’,‘username’,‘zhaoliu’
put ‘teacher’,‘81001’,‘username’,‘xiaoming’
put ‘teacher’,‘81001’,‘username’,‘xiaoli’
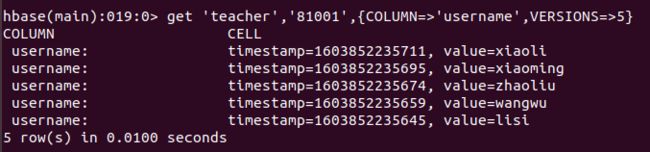
3、查询时,指定查询的历史版本数。默认会查询出最新的数据。(有效取值为1到5)
get ‘teacher’,‘81001’,{COLUMN=>‘username’,VERSIONS=>5}
查询结果截图如下:
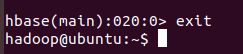
(6)退出HBase数据库操作
最后退出数据库操作,输入exit命令即可退出,注意:这里退出HBase数据库是退出对数据库表的操作,而不是停止启动HBase数据库后台运行。
Shell 命令:exit
到了这一步,本次实验就完成了,你今天学会了吗?