炸场!通用人工智能最新突破:一个模型、一套权重通吃600+视觉文本和决策任务,DeepMind两年研究一朝公开...
梦晨 鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
通用人工智能,还得看DeepMind。
这回,只一个模型,使用相同的权重,不仅把看家本领雅达利游戏玩得飞起。
和人类聊聊天、看图写话也不在话下。
甚至还能在现实环境里控制机械臂,让其听从指令完成任务!
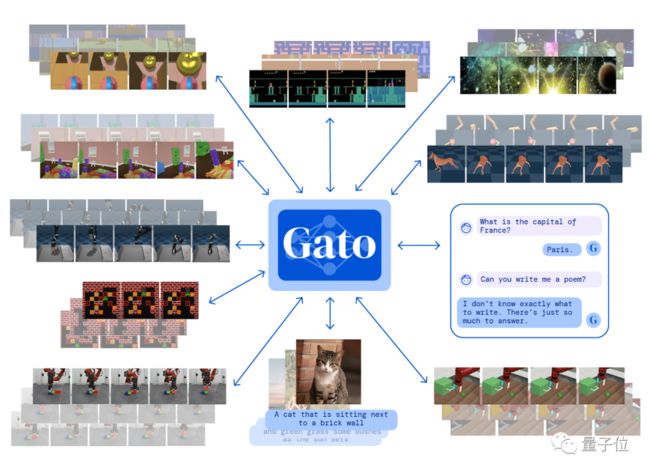
模型名为Gato,西班牙语中的“猫”。
按照DeepMind的说法,这只猫猫可以使用具有相同权重的同一个神经网络,适应各种不同的环境。
具体而言,DeepMind让它在604个不同的任务上接受了训练,这些任务模式完全不同,需要观察的元素和行为规则也不同。
而Gato不仅在450个任务中都超过了专家水平的50%,在23个雅达利游戏上表现还超过人类平均分。
DeepMind CEO哈萨比斯直接说:
这是我们目前最通用的智能体。
这一最新成果一发布,当即就在AI圈子里掀起热议。

有AI研究者指出:
Gato令人印象深刻。只需要在云上花费5万美元,就能完成对它的训练。
这点钱只是PaLM训练费用1100万美元的一个零头。用PaLM的预算完全可以将Gato扩展100倍,而这很可能是行之有效的。
PaLM是谷歌发布的5400亿参数语言模型。

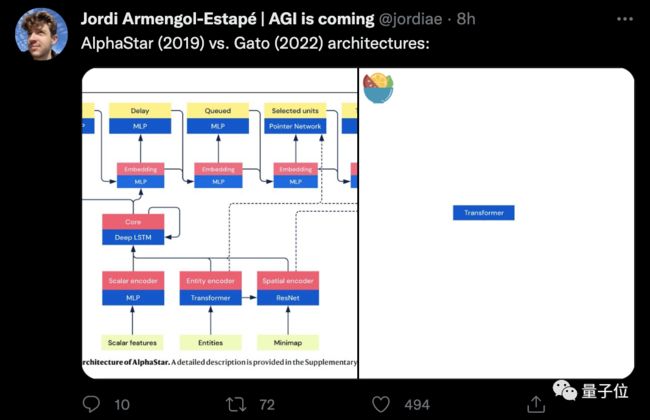
有人直接祭出了AlphaStar架构和Gato架构的对比:
Zoom AI杰出科学家Awni Hannun则直接感叹起过去5周以来,谷歌/DeepMind释出成果之密集。
所以这只来自DeepMind的“猫猫”,究竟怎么一回事?
一个Transformer搞定一切
对于研究方法,DeepMind只用一句话就解释明白了:
我们受到语言大模型的启发,用类似的方法把模型能力拓展到文本之外的领域。
没错,这次立功的又是语言大模型中常用的Transformer架构。
Transformer的本质就是把一个序列转换(transform)成另一个序列。

所以要想让它掌握各种不同任务,首先就需要把各类数据都编码成序列。
文本自不必说,天然就是序列信息,可用经典的SentencePiece编码。
图像,ViT已经打好样,先按16x16像素分割,再给每个像素编上号处理成序列。
玩游戏时的按键输入同样是序列,属于离散值,比如懂得都懂的“上上下下左右左右BABA”。

操纵机器人时的传感器信号和关节力矩属于连续值,也通过一系列采样和编码处理成离散序列。
最终,所有序列数据都交给同一个Transformer处理。
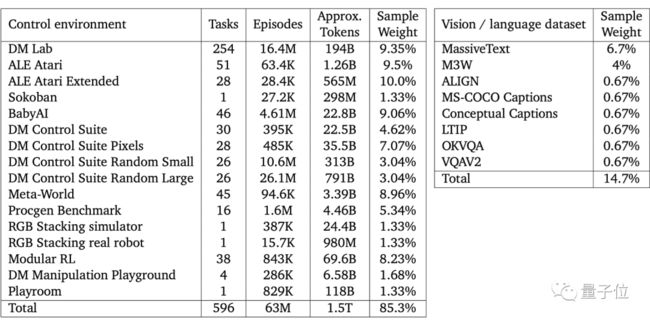
整个Gato模型使用的训练数据总体上偏向游戏和机器人控制任务,596个任务占了85.3%。视觉和自然语言任务只占14.7%。
模型架构上,为了简洁和可扩展性,就在最经典的原版Transformer基础上小改,具体参数如下:
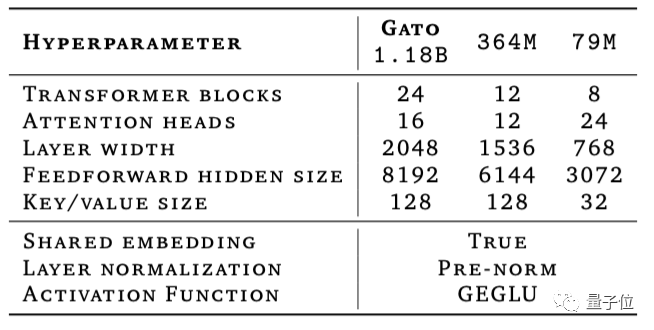
24层11.8亿参数版的Gato,在谷歌16x16 Cloud TPUv3切片上训练了大约4天。
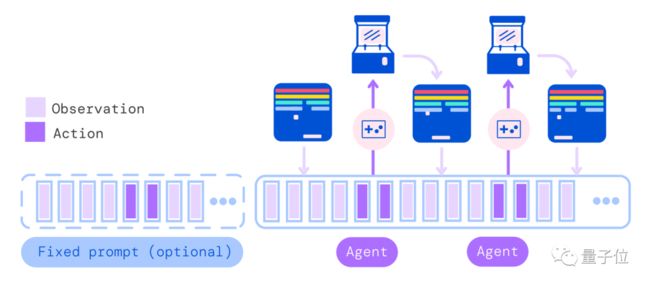
到了部署阶段,Gato对于视觉和语言任务就像传统Transformer和ViT那样运行。
对于游戏和机器人控制的行为模式则可以理解为“走一步看一步”。
首先给出一个任务提示,比如游戏操作或机器人动作,作为输出序列的开头。
接下来Gato会观察当前的环境,对动作向量进行一次自回归采样,执行动作后环境发生变化,再重复这个过程……
那么这样训练出来的Gato,在各项任务中到底表现如何?
仅靠12亿参数成为多面手
玩游戏方面,Gato的表现可以用一张图来总结。
x轴是训练集之中专家水平的百分比,其中0代表一个随机参数模型的水平。
y轴是Gato超过或达到对应专家水平的任务数量。
最终结果,Gato在604个任务中,有450个超过了专家水平的50%。
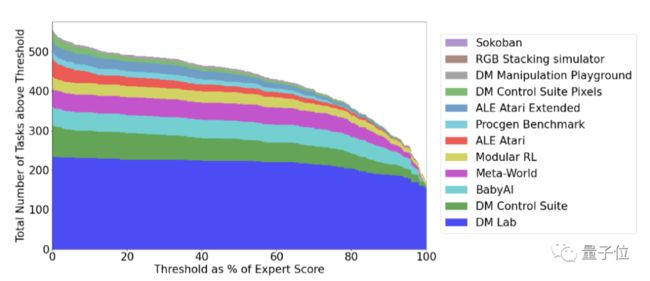
更详细的结果如下:
雅达利游戏测试中,Gato在23个游戏上表现超过人类平均分,11个游戏上比人类得分高一倍。
这些游戏包括经典的乒乓球、赛车,也包括射击、格斗等多种类型。
![]()
在Bengio团队推出的BabyAI测试上,Gato几乎在所有关卡达到了专家水平的80%,最难的几个Boss关达到75%。与之前BabyAI榜单上的两个模型水平相当(分别为77%和90%),但这两个模型都针对性的用了上百万个演示来训练。
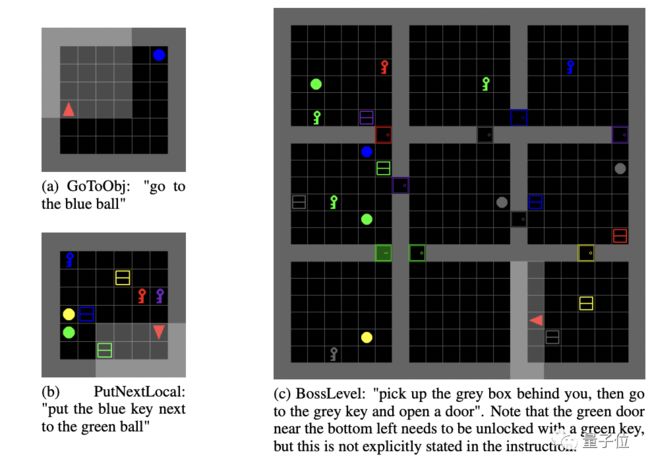
△BabyAI关卡示例。
在Meta-World上(虚拟环境中操作机械臂),Gato在全部45个任务中,有44个超过专家水平的50%,35个超过80%,3个超过90%。

△Meta-World任务示例
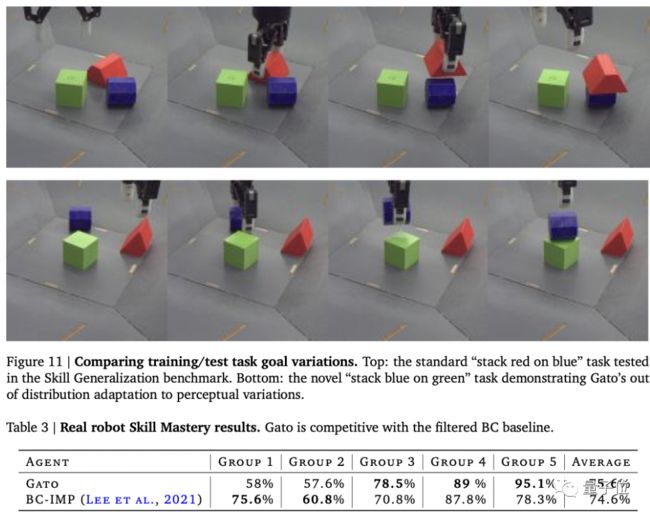
操纵真实机器人方面,与之前模型对比也不遑多让。
至于视觉和文本任务DeepMind这次至少为了验证通用模型的可行性,没有做跑分,而是给了一些示例。
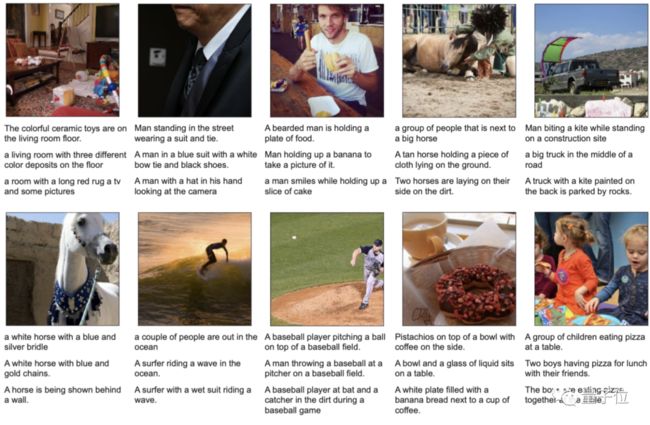
△描述图像
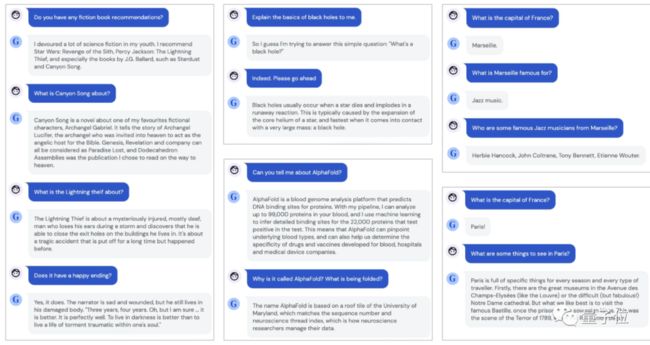
△聊天对话
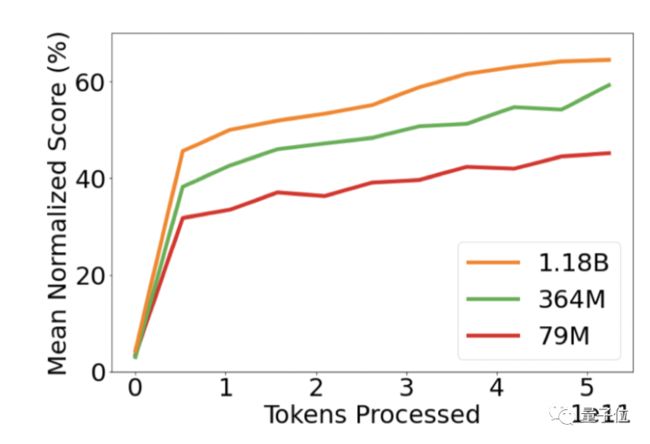
最后,DeepMind还对Gato模型的可扩展性做了评估。
虽然当前Gato在每一个单独任务上都还比不上SOTA结果,但实验结果表明,随着参数、数据和硬件的增加,Gato模型的性能还有成比例上涨的空间。
另外,Gato在少样本学习上也表现出一定潜力。
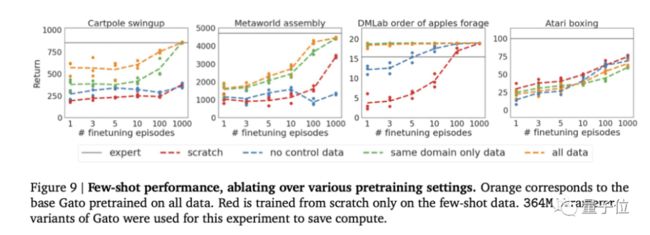
DeepMind认为,这样一个通用模型将来可通过提示或微调迅速学习新的任务,再也不用为每个任务都重头训练一个大模型了。
通用人工智能还有多远?
看完Gato如此表现,网友们的“大受震撼”也就不奇怪了。
甚至还有人认为,AGI(通用人工智能)近在眼前。
当然,反对/质疑的声音也不小。
比如始终冲在给人工智能泼冷水一线的马库斯,这次也第一时间开了炮:
仔细看看第10页。无论模型有多大,大型语言模型标志性的不靠谱和错误信息仍然存在。
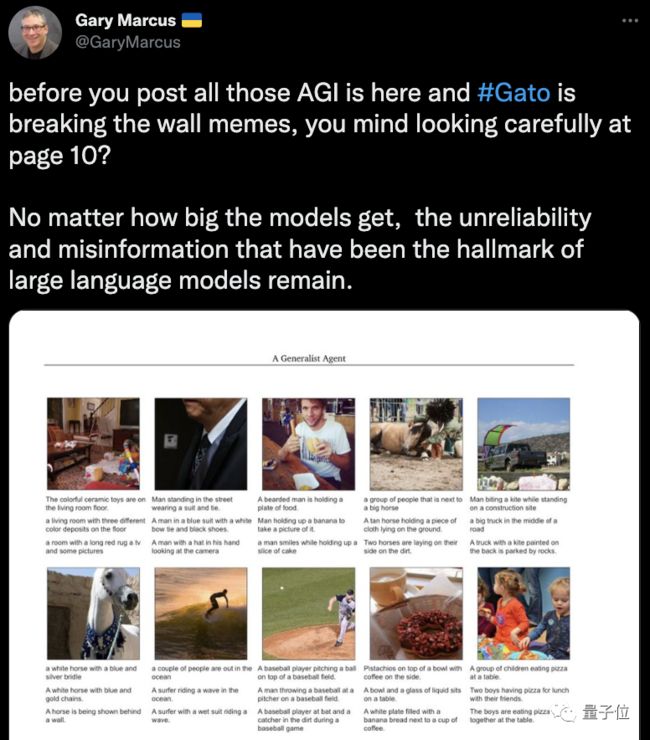
但不管怎么说,DeepMind在通用人工智能方向上的努力都在不断涌现出新成果。
事实上,无论是2013年惊艳了谷歌的雅达利游戏AI,还是名满全球的AlphaGo、AlphaStar,DeepMind透过这些阶段性成果想要达成的终极目标,一直都通向通用人工智能这个关键词。
去年,DeepMind首席研究科学家、伦敦大学学院教授David Silver还领衔发布了一篇同样引起不少讨论的文章:Reward is Enough。
论文认为,强化学习作为基于奖励最大化的人工智能分支,足以推动通用人工智能的发展。
而据Gato团队成员透露,这只“猫猫”已经在DeepMind内部孕育了2年时间。

此次Gato是以有监督方式进行离线训练的,但论文也强调,原则上,同样可以采用离线或在线强化学习的方式对其进行训练。
而就在一周前,DeepMind发布了一个新视频,其中说到:
我们接下来要做一件大事(the next big thing),那意味着需要去尝试很多人们认为过于困难的事情。但我们一定要去尝试一下。
现在看来,这个next big thing就是指AGI了。
论文地址:
https://www.deepmind.com/publications/a-generalist-agent
参考链接:
[1]https://twitter.com/DeepMind/status/1524770016259887107