Easy RL:强化学习教程:什么是强化学习
强化学习(reinforcement learning,RL)讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)中最大化它能获得的奖励。如图1.1 所示,强化学习由两部分组成:智能体和环境。在强化学习过程中,智能体与环境一直在交互。智能体在环境中获取某个状态后,它会利用该状态输出一个动作(action),这个动作也称为决策(decision)。然后这个动作会在环境中被执行,环境会根据智能体采取的动作,输出下一个状态以及当前这个动作带来的奖励。智能体的目的就是尽可能多地从环境中获取奖励。
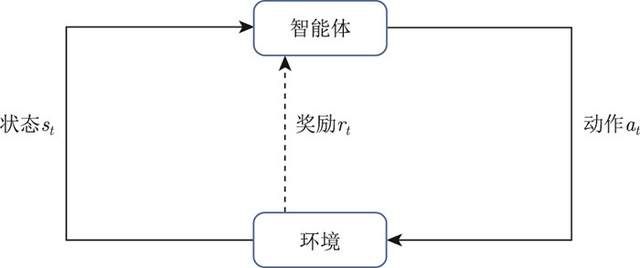
图1.1 强化学习示意[1]
1.1.1 强化学习与监督学习
我们可以把强化学习与监督学习做一个对比。以图片分类为例,如图1.2 所示,监督学习(supervised learning)假设我们有大量被标注的数据,比如汽车、飞机、椅子这些被标注的图片,这些图片都要满足独立同分布,即它们之间是没有关联关系的。假设我们训练一个分类器,比如神经网络。为了分辨输入的图片中是汽车还是飞机,在训练过程中,需要把正确的标签信息传递给神经网络。当神经网络做出错误的预测时,比如输入汽车的图片,它预测出来是飞机,我们就会直接告诉它,该预测是错误的,正确的标签应该是汽车。最后我们根据类似错误写出一个损失函数(loss function),通过反向传播(back propagation)来训练神经网络。
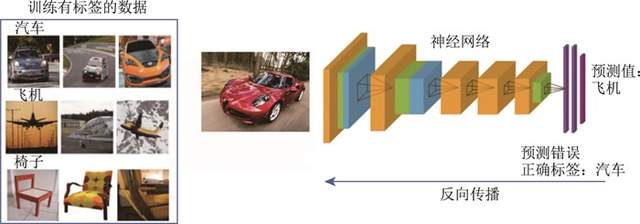
图1.2 监督学习
通常假设样本空间中全体样本服从一个未知分布,每个样本都是独立地从这个分布上采样获得的,即独立同分布(independent and identically distributed,i.i.d.)。
所以在监督学习过程中,有两个假设。第一,输入的数据(标注的数据)都应是没有关联的。因为如果输入的数据有关联,学习器(learner)是不好学习的。第二,需要告诉学习器正确的标签是什么,这样它可以通过正确的标签来修正自己的预测。
在强化学习中,监督学习的两个假设其实都不能得到满足。以雅达利(Atari)游戏
![]()
为例,如图1.3所示,这是一个打砖块的游戏,控制木板左右移动从而把球反弹到上面来消除砖块。在玩游戏的过程中,我们可以发现智能体得到的观测(observation)不是独立同分布的,上一帧与下一帧间其实有非常强的连续性。我们得到的数据是相关的时间序列数据,不满足独立同分布。另外,我们并没有立刻获得反馈,游戏没有告诉我们哪个动作是正确动作。比如现在把木板往右移,这只会使得球往上或者往左一点儿,我们并不会得到即时的反馈。因此,强化学习之所以困难,是因为智能体不能得到即时的反馈,然而我们依然希望智能体在这个环境中学习。

图1.3 雅达利游戏
![]()
如图1.4所示,强化学习的训练数据就是一个玩游戏的过程。我们从第1步开始,采取一个动作,比如把木板往右移,接到球。第2步我们又采取一个动作……得到的训练数据是一个玩游戏的序列。假设现在是在第3步,我们把这个序列放进网络,希望网络可以输出一个动作,即在当前的状态应该输出往右移还是往左移。这里有个问题,没有标签来说明现在这个动作是正确还是错误的,必须等到游戏结束才可能知道,这个游戏可能10s后才结束。现在这个动作到底对赢得游戏有无帮助,其实是不清楚的。这里我们就面临延迟奖励(delayed reward)的问题,延迟奖励使得训练网络非常困难。
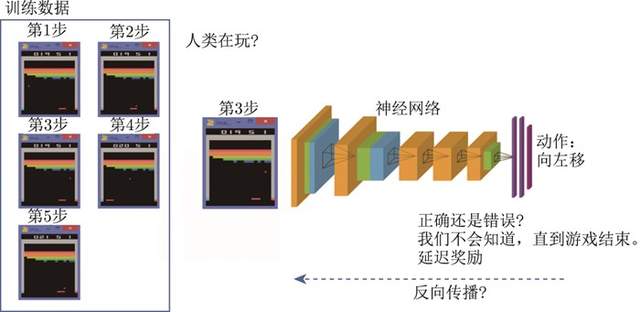
图1.4 强化学习:玩
![]()
强化学习和监督学习的区别如下。
(1)强化学习处理的大多数是序列数据,其很难像监督学习的样本一样满足独立同分布。
(2)学习器并没有告诉我们每一步正确的动作应该是什么,学习器需要自己去发现哪些动作可以带来最多的奖励,只能通过不停地尝试来发现最有利的动作。
(3)智能体获得自己能力的过程,其实是不断地试错探索(trial-and-error exploration)的过程。探索(exploration)和利用(exploitation)是强化学习中非常核心的问题。其中,探索指尝试一些新的动作,这些新的动作有可能会使我们得到更多的奖励,也有可能使我们“一无所有”;利用指采取已知的可以获得最多奖励的动作,重复执行这个动作,因为我们知道这样做可以获得一定的奖励。 因此,我们需要在探索和利用之间进行权衡,这也是在监督学习中没有的情况。
(4)在强化学习过程中,没有非常强的监督者(supervisor),只有奖励信号(reward signal),并且奖励信号是延迟的,即环境会在很久以后才告诉我们之前所采取的动作到底是不是有效的。因为我们没有得到即时反馈,所以智能体使用强化学习来学习就非常困难。当我们采取一个动作后,如果使用监督学习,就可以立刻获得一个指导,比如,我们现在采取了一个错误的动作,正确的动作应该是什么。而在强化学习中,环境可能会告诉我们这个动作是错误的,但是它并不会告诉我们正确的动作是什么。而且更困难的是,它可能是在一两分钟过后才告诉我们这个动作是错误的。所以这也是强化学习和监督学习不同的地方。
通过与监督学习的比较,我们可以总结出强化学习的一些特征。
(1)强化学习会试错探索,它通过探索环境来获取对环境的理解。
(2)强化学习智能体会从环境中获得延迟的奖励。
(3)在强化学习的训练过程中,时间非常重要。因为我们得到的是有时间关联的数据(sequential data),而不是独立同分布的数据。在机器学习中,如果观测数据有非常强的关联,会使得训练非常不稳定。这也是为什么在监督学习中,我们希望数据尽量满足独立同分布,这样就可以消除数据之间的相关性。
(4)智能体的动作会影响它随后得到的数据,这一点是非常重要的。在训练智能体的过程中,很多时候我们也是通过正在学习的智能体与环境交互来得到数据的。所以如果在训练过程中,智能体不能保持稳定,就会使我们采集到的数据非常糟糕。我们通过数据来训练智能体,如果数据有问题,整个训练过程就会失败。所以在强化学习中一个非常重要的问题就是,怎么让智能体的动作一直稳定地提升。
1.1.2 强化学习的例子
为什么我们关注强化学习?其中非常重要的一个原因就是强化学习得到的模型可以有超人类的表现。监督学习获取的监督数据,其实是人来标注的,比如 ImageNet 的图片的标签都是人类标注的。因此我们可以确定监督学习算法的上限(upper bound)就是人类的表现,标注结果决定了它的表现永远不可能超越人类的。但是对于强化学习,它在环境中自己探索,有非常大的潜力,它可以获得超越人类的能力的表现,比如DeepMind 的强化学习算法 AlphaGo 可以把人类顶尖的棋手打败。
这里给大家举一些在现实生活中强化学习的例子。
(1)在自然界中,羚羊其实也在做强化学习。它刚刚出生的时候,可能都不知道怎么站立,然后它通过试错,一段时间后就可以跑得很快,可以适应环境。
(2)我们也可以把股票交易看成强化学习的过程,可以不断地买卖股票,然后根据市场给出的反馈来学会怎么去买卖可以让奖励最大化。
(3)玩雅达利游戏或者其他电脑游戏,也是一个强化学习的过程,我们可以通过不断试错来知道怎么玩才可以通关。
图1.5所示为强化学习的一个经典例子,即雅达利的
![]()
游戏。游戏中右边的选手把球拍到左边,然后左边的选手需要把球拍到右边。训练好的强化学习智能体和正常的选手有区别:强化学习的智能体会一直做无意义的上下往复移动,而正常的选手不会做出这样的动作。
图1.5
![]()
游戏[2]
在
![]()
游戏中,只有两个动作:往上或者往下。如图1.6所示,如果强化学习通过学习一个策略网络来进行分类,那么策略网络会输入当前帧的图片,输出所有决策的可能性,比如往上移动的概率。
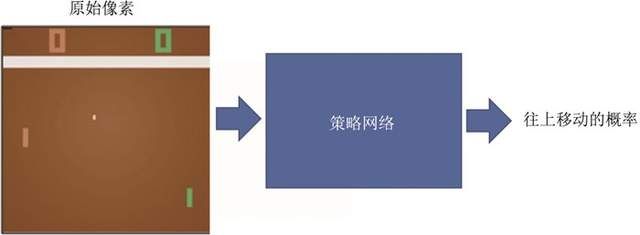
图1.6 强化学习玩
![]()
[2]
如图1.7所示,对于监督学习,我们可以直接告诉智能体正确动作的标签是什么。但在
![]()
游戏中,我们并不知道它的正确动作的标签是什么。
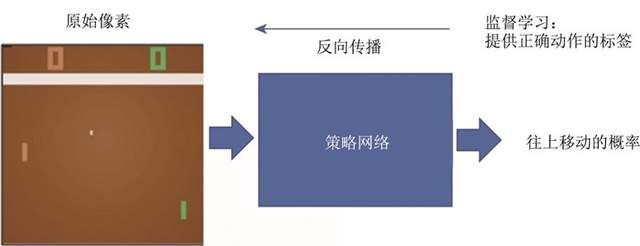
图1.7 监督学习玩
![]()
[2]
在强化学习中,让智能体尝试玩
![]()
游戏,对动作进行采样,直到游戏结束,然后对每个动作进行惩罚。图1.8所示为预演(rollout)的过程。预演是指我们从当前帧对动作进行采样,生成很多局游戏。将当前的智能体与环境交互,会得到一系列观测。每一个观测可看成一条轨迹(trajectory)。轨迹就是当前帧以及它采取的策略,即状态和动作的序列:
![]()
(1.1)
最后结束时,我们会知道到底有没有把这个球拍到对方区域,对方有没有接住,赢了还是输了。我们可以通过观测序列以及最终奖励(eventual reward)来训练智能体,使它尽可能地采取可以获得最终奖励的动作。一场游戏称为一个回合(episode)或者试验(trial)。
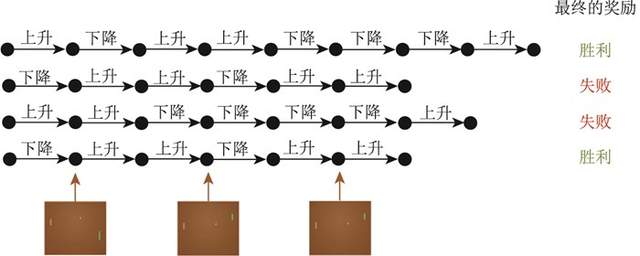
图1.8 可能的预演序列[2]
1.1.3 强化学习的历史
强化学习是有一定的历史的,早期的强化学习,我们称其为标准强化学习。最近业界把强化学习与深度学习结合起来,就形成了深度强化学习(deep reinforcement learning),因此,深度强化学习 = 深度学习 + 强化学习。我们可将标准强化学习和深度强化学习类比于传统的计算机视觉和深度计算机视觉。
如图1.9(a) 所示,传统的计算机视觉由两个过程组成。
(1)给定一张图片,我们先要提取它的特征,使用一些设计好的特征,比如方向梯度直方图(histogram of oriented gradient,HOG)、可变形的组件模型(deformable part model,DPM)。
(2)提取这些特征后,我们再单独训练一个分类器。这个分类器可以是支持向量机(support vector machine,SVM)或 Boosting,然后就可以辨别这张图片中是狗还是猫。
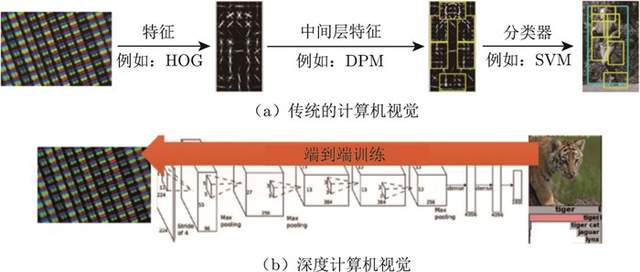
图1.9 传统的计算机视觉与深度计算机视觉的区别
2012年,Hinton团队提出了AlexNet。AlexNet在ImageNet分类比赛中获得冠军,迅速引起了人们对于卷积神经网络(convolutional neural network,CNN)的广泛关注。大家就把特征提取以及分类这两个过程合并了。我们训练一个神经网络,这个神经网络既可以做特征提取,也可以做分类,它可以实现端到端训练,如图1.9(b) 所示,其参数可以在每一个阶段都得到极大的优化,这是一个非常重要的突破。
我们可以把神经网络放到强化学习中。
- 标准强化学习:比如 TD-Gammon 玩游戏的过程,其实就是设计特征,然后训练价值函数的过程,如图1.10(a) 所示。标准强化学习先设计很多特征,这些特征可以描述当前整个状态。得到这些特征后,我们就可以通过训练一个分类网络或者分别训练一个价值估计函数来采取动作。
- 深度强化学习:自从我们有了深度学习,有了神经网络,就可以把智能体玩游戏的过程改进成一个端到端训练(end-to-end training)的过程,如图1.10(b) 所示。我们不需要设计特征,直接输入状态就可以输出动作。我们可以用一个神经网络来拟合价值函数、Q函数或策略网络,省去特征工程(feature engineering)的过程。
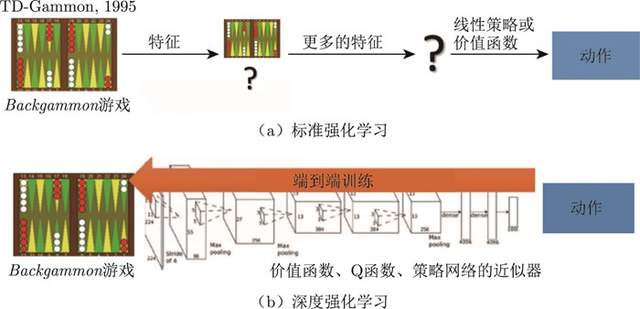
图1.10 标准强化学习与深度强化学习的区别
1.1.4 强化学习的应用
为什么强化学习在这几年有很多的应用,比如玩游戏以及机器人的一些应用,并且可以击败人类的顶尖棋手呢?这有如下几点原因。首先,我们有了更多的算力(computation power),有了更多的 GPU,可以更快地做更多的试错尝试。其次,通过不同的尝试,智能体在环境中获得了很多信息,可以在环境中取得很大的奖励。最后,通过端到端训练,可以把特征提取、价值估计以及决策部分一起优化,就可以得到一个更强的决策网络。
接下来介绍一些强化学习中比较有意思的例子。
(1)DeepMind 研发的走路的智能体。这个智能体往前走一步,就会得到一个奖励。这个智能体有不同的形态,可以学到很多有意思的功能。比如,像人一样的智能体学习怎么在曲折的道路上往前走。结果非常有意思,这个智能体会把手举得非常高,因为举手可以让它的身体保持平衡,它就可以更快地在环境中往前走。而且我们也可以增加环境的难度,加入一些扰动,智能体就会变得更鲁棒。
(2)机械臂抓取。因为我们把强化学习应用到机械臂自动抓取需要大量的预演,所以我们可以使用多个机械臂进行训练。分布式系统可以让机械臂尝试抓取不同的物体,盘子中物体的形状是不同的,这样就可以让机械臂学到一个统一的动作,然后针对不同的抓取物都可以使用最优的抓取算法。因为抓取的物体形状的差别很大,所以使用一些传统的抓取算法不能把所有物体都抓起来。传统的抓取算法对每一个物体都需要建模,这样是非常费时的。但通过强化学习,我们可以学到一个统一的抓取算法,其适用于不同的物体。
(3)OpenAI 的机械臂翻魔方。OpenAI 在2018年的时候设计了一款带有“手指”的机械臂,它可以通过翻动手指使得手中的木块达到预期的设定。人的手指其实非常灵活,怎么使得机械臂的手指也具有这样灵活的能力一直是个问题。OpenAI先在一个虚拟环境中使用强化学习对智能体进行训练,再把它应用到真实的机械臂上。这在强化学习中是一种比较常用的做法,即我们先在虚拟环境中得到一个很好的智能体,然后把它应用到真实的机器人中。这是因为真实的机械臂通常非常容易坏,而且非常贵,一般情况下没办法大批量地被购买。OpenAI 在2019 年对其机械臂进行了进一步的改进,这个机械臂在改进后可以玩魔方了。
(4)穿衣服的智能体。很多时候我们要在电影或者一些动画中实现人穿衣服的场景,通过手写执行命令让机器人穿衣服非常困难,穿衣服也涉及非常精细的操作。我们可以训练强化学习智能体来实现穿衣服功能。我们还可以在其中加入一些扰动,智能体可以抵抗扰动。可能会有失败的情况(failure case)出现,这样智能体就穿不进去衣服。
强化学习书籍推荐
Easy RL 强化学习教程(蘑菇书正式版)

本书结合了李宏毅老师的“深度强化学习”、周博磊老师的“强化学习纲要”、李科浇老师的“世界冠军带你从零实践强化学习”公开课的精华内容,在理论严谨的基础上深入浅出地介绍马尔可夫决策过程、蒙特卡洛方法、时序差分方法、Sarsa、Q 学习等传统强化学习算法,以及策略梯度、近端策略优化、深度Q 网络、深度确定性策略梯度等常见深度强化学习算法的基本概念和方法,并以大量生动有趣的例子帮助读者理解强化学习问题的建模过程以及核心算法的细节。
此外,本书还提供较为全面的习题解答以及Python 代码实现,可以让读者进行端到端、从理论到轻松实践的全生态学习,充分掌握强化学习算法的原理并能进行实战。
全书主要内容源于3门公开课,并在其基础上进行了一定的原创。比如,为了尽可能地降低阅读门槛,笔者对3门公开课的精华内容进行选取并优化,对所涉及的公式都给出详细的推导过程,对较难理解的知识点进行了重点讲解和强化,以方便读者较为轻松地入门。此外,为了丰富内容,笔者还补充了不少除3门公开课之外的强化学习相关知识。全书共13章,大体上可分为两个部分:第一部分包括第1~3章,介绍强化学习基础知识以及传统强化学习算法;第二部分包括第4~13章,介绍深度强化学习算法及其常见问题的解决方法。第二部分各章相对独立,读者可根据自己的兴趣和时间选择性阅读。