吃瓜教程——第三章
《机器学习》——第三章 线性模型
- 一、基本形式
- 二、线性回归
-
- 2.1 最小二乘法
- 2.2 极大似然估计
- 2.3 求解 w w w和 b b b的值
- 2.4 Hessian矩阵
- 2.5 多元线性回归
- 三、对数几率回归
- 四、线性判别分析(LDA)
- 五、多分类学习
- 六、类别不平衡
- 七、总结
一、基本形式
给定由 d d d个属性描述的示例中, x = ( x 1 ; x 2 ; ⋯ ; x d ) x=\left( x_1;x_2;\cdots ;x_d \right) x=(x1;x2;⋯;xd),其中 x i x_i xi是 x x x在第 i i i个属性上的取值,线性模型表示为
f ( x ) = w 1 x 1 + w 2 x 2 + . . . + w d x d + b f(x)=w_1x_1+w_2x_2+...+w_dx_d+b f(x)=w1x1+w2x2+...+wdxd+b一般情况下用向量的形式,则表示成 f ( x ) = w T x + b f\left( x \right) =w^Tx+b f(x)=wTx+b只要能够确定出 w w w和 b b b的值就可以确定这个线性模型了
二、线性回归
问:线性回归是什么?
答:线性回归是通过学习一个线性模型,来预测出其对应的连续值,通过对预测值和真实值之间,尽可能缩小其欧氏距离,即使得 f ( x i ) ≈ y i f\left( x_i \right) \approx y_i f(xi)≈yi
2.1 最小二乘法
使用均方误差最小化来进行模型求解的,形如
E ( w , b ) = ∑ i = 1 m ( y i − f ( x i ) ) 2 = ∑ i = 1 m ( y i − w x i − b ) 2 E_{\left( w,b \right)}=\sum_{i=1}^m{\left( y_i-f\left( x_i \right) \right) ^2}\\\,\,=\sum_{i=1}^m{\left( y_i-wx_i-b \right) ^2} E(w,b)=i=1∑m(yi−f(xi))2=i=1∑m(yi−wxi−b)2
2.2 极大似然估计
假设线性回归模型如下所示,
y = w x + b + ϵ y=w x+b+\epsilon y=wx+b+ϵ
其中 ϵ \epsilon ϵ符合 p ( ϵ ) = 1 2 π σ exp ( − ϵ 2 2 σ 2 ) p(\epsilon)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\epsilon^{2}}{2 \sigma^{2}}\right) p(ϵ)=2πσ1exp(−2σ2ϵ2)
然后将 ϵ \epsilon ϵ用 y − ( w x + b ) y-(wx+b) y−(wx+b)进行代替后,得到的式子为
p ( y ) = 1 2 π σ exp ( − ( y − ( w x + b ) ) 2 2 σ 2 ) p(y)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{(y-(w x+b))^{2}}{2 \sigma^{2}}\right) p(y)=2πσ1exp(−2σ2(y−(wx+b))2)
代入极大似然估计后,得到如下所示,
L ( w , b ) = ∏ i = 1 m p ( y i ) = ∏ i = 1 m 1 2 π σ exp ( − ( y i − ( w x i + b ) ) 2 2 σ 2 ) L(w, b)=\prod_{i=1}^{m} p\left(y_{i}\right)=\prod_{i=1}^{m} \frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(y_{i}-\left(w x_{i}+b\right)\right)^{2}}{2 \sigma^{2}}\right) L(w,b)=i=1∏mp(yi)=i=1∏m2πσ1exp(−2σ2(yi−(wxi+b))2)
由于极大似然函数不好求,因此对上述的式子进行取对数,最终得出
ln L ( w , b ) = ∑ i = 1 m ln 1 2 π σ exp ( − ( y i − w x i − b ) 2 2 σ 2 ) = ∑ i = 1 m ln 1 2 π σ + ∑ i = 1 m ln exp ( − ( y i − w x i − b ) 2 2 σ 2 ) \begin{aligned} \ln L(w, b) &=\sum_{i=1}^{m} \ln \frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(y_{i}-w x_{i}-b\right)^{2}}{2 \sigma^{2}}\right) \\ &=\sum_{i=1}^{m} \ln \frac{1}{\sqrt{2 \pi} \sigma}+\sum_{i=1}^{m} \ln \exp \left(-\frac{\left(y_{i}-w x_{i}-b\right)^{2}}{2 \sigma^{2}}\right) \end{aligned} lnL(w,b)=i=1∑mln2πσ1exp(−2σ2(yi−wxi−b)2)=i=1∑mln2πσ1+i=1∑mlnexp(−2σ2(yi−wxi−b)2)
- 其中使用了 l n ( a b ) = l n a + l n b ln(ab)=lna+lnb ln(ab)=lna+lnb的性质
2.3 求解 w w w和 b b b的值
加上argmin后就变成
( w ∗ , b ∗ ) = a r g min ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 = a r g min ( w , b ) ∑ i = 1 m ( y i − w x i − b ) 2 \left( w^*,b^* \right) =\underset{\left( w,b \right)}{arg\min}\sum_{i=1}^m{\begin{array}{c} \left( f\left( x_i \right) -y_i \right) ^2\\\end{array}}\\=\underset{\left( w,b \right)}{arg\min}\sum_{i=1}^m{\begin{array}{c} \left( y_i-wx_i-b \right) ^2\\\end{array}} (w∗,b∗)=(w,b)argmini=1∑m(f(xi)−yi)2=(w,b)argmini=1∑m(yi−wxi−b)2
- 其中 a r g m i n argmin argmin表示当这个式子取最小的时候, w w w和 b b b的取值是多少
由于上述的式子中存在着两个参数一个是 w w w,一个是 b b b,因此对上述的式子,根据数分的知识,要求出其值,则分别对两个参数求偏导,令导数为0,即可求出连个参数的值
最终得出 w w w的求解公式为
w = ∑ i = 1 m y i ( x i − x ˉ ) ∑ i = 1 m x i 2 − 1 m ( ∑ i = 1 m x i ) 2 w=\frac{\sum_{i=1}^{m} y_{i}\left(x_{i}-\bar{x}\right)}{\sum_{i=1}^{m} x_{i}^{2}-\frac{1}{m}\left(\sum_{i=1}^{m} x_{i}\right)^{2}} w=∑i=1mxi2−m1(∑i=1mxi)2∑i=1myi(xi−xˉ)
b b b的求解公式是
b = 1 m ∑ i = 1 m ( y i − w x i ) b=\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-w x_{i}\right) b=m1i=1∑m(yi−wxi)
2.4 Hessian矩阵
用于判断这个函数是否为一个凸函数的办法,Hessian矩阵形如下所示,
∇ 2 E ( w , b ) = [ ∂ 2 E ( w , b ) ∂ w 2 ∂ 2 E ( w , b ) ∂ w ∂ b ∂ 2 E ( w , b ) ∂ b ∂ w ∂ 2 E ( w , b ) ∂ b 2 ] \nabla^{2} E_{(w, b)}=\left[\begin{array}{ll} \frac{\partial^{2} E_{(w, b)}}{\partial w^{2}} & \frac{\partial^{2} E_{(w, b)}}{\partial w \partial b} \\ \frac{\partial^{2} E_{(w, b)}}{\partial b \partial w} & \frac{\partial^{2} E_{(w, b)}}{\partial b^{2}} \end{array}\right] ∇2E(w,b)=[∂w2∂2E(w,b)∂b∂w∂2E(w,b)∂w∂b∂2E(w,b)∂b2∂2E(w,b)]
Hessian矩阵是针对于一个函数对其求二阶偏导,得出的一个矩阵,当这个矩阵为半正定的时候便可以说明这个函数为凸函数
由于在现实中不可能单单只是存在着对一维的数组进行操作,肯定会涉及到n维的欧式空间
2.5 多元线性回归
从一般的线性回归模型,到映射在n维空间上的多元线性回归,可以通过矩阵的形式表示出来,即
f ( x i ) = w T x i + b f\left(\boldsymbol{x}_{i}\right)=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b f(xi)=wTxi+b
其中 w = ( w 1 , w 2 , . . . w n ) w=(w_1,w_2,...w_n) w=(w1,w2,...wn), x = ( x 1 , x 2 , . . . x n ) x=(x_1,x_2,...x_n) x=(x1,x2,...xn),当然从满足矩阵运算的角度来说,对哪一个进行转置都是ok的,只不过是满足一列乘以一行的规律
根据均方差误差最小化原则有
w ∗ = arg min w ( y − X w ) T ( y − X w ) \boldsymbol{w}^{*}=\arg \min _{w}(\boldsymbol{y}-\boldsymbol{X} \boldsymbol{w})^{T}(\boldsymbol{y}-\boldsymbol{X} \boldsymbol{w}) w∗=argwmin(y−Xw)T(y−Xw)
对 w w w进行求导
∂ E w ∂ w = 2 X T ( X w − y ) \frac{\partial \boldsymbol{E}_{\boldsymbol{w}}}{\partial \boldsymbol{w}}=2 \boldsymbol{X}^{T}(\boldsymbol{X} \boldsymbol{w}-\boldsymbol{y}) ∂w∂Ew=2XT(Xw−y)
令导数为0,就可以求出来 w w w的解
三、对数几率回归
对数几率回归,又叫做逻辑回归,比如说将二分类的问题的结果转化为0-1上的值的输出,而最理想的单位阶跃函数是
y = { 0 , z < 0 0.5 , z = 0 1 , z > 0 y=\left\{ \begin{array}{c} 0,z<0\\ 0.5,z=0\\ 1,z>0\\\end{array} \right. y=⎩⎨⎧0,z<00.5,z=01,z>0
周志华老师在书中给出这样的一幅图
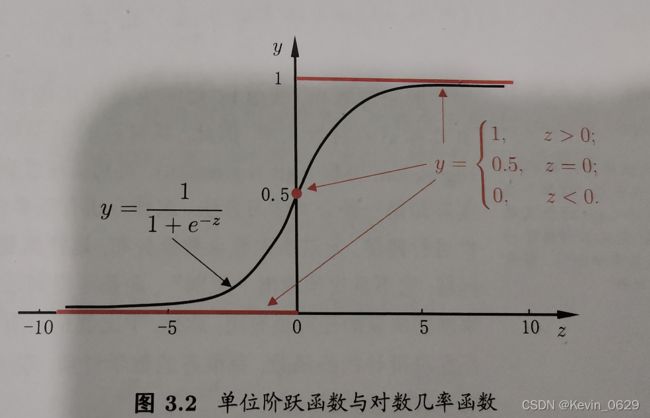
- 小心得:看到这幅图,让我想起来就在上一年的同样也是1月到2月之间,我参加了一个叫做美国大学生数学建模比赛,其中我们队对蜜蜂的那个迁移问题求解,其中就用到了这个函数的图
针对于上述的这幅图,有一个函数可以代替图,他便是sigmoid函数
y = 1 1 + e − z y=\frac{1}{1+e^{-z}} y=1+e−z1
将线性模型 y = w T x + b y=w^Tx+b y=wTx+b带入sigmoid函数中, 可以得到
y = 1 1 + e − ( w T x + b ) y=\frac{1}{1+e^{-\left(\boldsymbol{w}^{T} \boldsymbol{x}+b\right)}} y=1+e−(wTx+b)1
取对数后得到的操作如下所示
ln y 1 − y = w T x + b \ln \frac{y}{1-y}=\boldsymbol{w}^{T} \boldsymbol{x}+b ln1−yy=wTx+b
采用极大似然去求解,将模型改写如下
p ( y = 1 ∣ x ) = e w T x + b 1 + e w T x + b p ( y = 0 ∣ x ) = 1 1 + e w T x + b \begin{aligned} &p(y=1 \mid \boldsymbol{x})=\frac{e^{\boldsymbol{w}^{T} \boldsymbol{x}+b}}{1+e^{\boldsymbol{w}^{T} \boldsymbol{x}+b}} \\ &p(y=0 \mid \boldsymbol{x})=\frac{1}{1+e^{\boldsymbol{w}^{T} \boldsymbol{x}+b}} \end{aligned} p(y=1∣x)=1+ewTx+bewTx+bp(y=0∣x)=1+ewTx+b1
得到极大似然函数,并对极大似然函数进行求对数
L ( w , b ) = ∏ i = 1 m p ( y i ∣ x i ; w , b ) l ( w , b ) = ∑ i = 1 m ln [ y i p 1 ( x ^ i ; w , b ) + ( 1 − y i ) p 0 ( x ^ i ; w , b ) ] \begin{aligned} L(\boldsymbol{w}, b) &=\prod_{i=1}^{m} p\left(y_{i} \mid \boldsymbol{x}_{i} ; w, b\right) \\ l(\boldsymbol{w}, b) &=\sum_{i=1}^{m} \ln \left[y_{i} p_{1}\left(\hat{\boldsymbol{x}}_{i} ; \boldsymbol{w}, b\right)+\left(1-y_{i}\right) p_{0}\left(\hat{\boldsymbol{x}}_{i} ; \boldsymbol{w}, b\right)\right] \end{aligned} L(w,b)l(w,b)=i=1∏mp(yi∣xi;w,b)=i=1∑mln[yip1(x^i;w,b)+(1−yi)p0(x^i;w,b)]
四、线性判别分析(LDA)
LDA的思想很朴素,通过给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离,在书中周志华老师给出这样的一幅图,
其中正例的投影为 w T μ 0 w^T\mu_0 wTμ0,其协方差为 w T Σ 0 w w^T\varSigma _0w wTΣ0w,负例的投影为 w T μ 1 w^T\mu_1 wTμ1,协方差为 w T Σ 1 w w^T\varSigma _1w wTΣ1w
使得同类样例的投影点尽可能接近,则可以让下面的等式尽可能小 w T Σ 0 w + w T Σ 1 w w^T\varSigma _0w+w^T\varSigma _1w wTΣ0w+wTΣ1w
使得异类样例的投影点尽可能远离,则可以让下面的等式尽可能大
∥ w T μ 0 − w T μ 1 ∥ 2 2 \left\| w^T\mu _0-w^T\mu _1 \right\| _{2}^{2} ∥∥wTμ0−wTμ1∥∥22
因此得到一个目标函数J
J M A X = ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w J_{MAX}=\frac{\left\| w^T\mu _0-w^T\mu _1 \right\| _{2}^{2}}{w^T\varSigma _0w+w^T\varSigma _1w} JMAX=wTΣ0w+wTΣ1w∥∥wTμ0−wTμ1∥∥22
定义类内散度矩阵
S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T S_w=\varSigma _0+\varSigma _1\\=\sum_{x\in X_0}{\left( x-\mu _0 \right) \left( x-\mu _0 \right) ^T}+\sum_{x\in X_1}{\left( x-\mu _1 \right) \left( x-\mu _1 \right) ^T} Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T
以及类间散度矩阵
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_b=(\mu_0-\mu_1)(\mu_0-\mu_1)^T Sb=(μ0−μ1)(μ0−μ1)T
所以目标函数 J J J可以改写成
J = w T S b w w T S w w J=\frac{w^TS_bw}{w^TS_ww} J=wTSwwwTSbw
五、多分类学习
- 一对一(OvO)
- 一对多(OvR)
- 多对多(MvM)
六、类别不平衡
情境:当数据集中,正例和负例的不多的时候,需要对其进行重新采样
再缩放思想
解决类别不平衡的三类做法
- 直接对训练集里的反类样例进行"欠采样",即去除一些反例使得正反例数目接近
- 对训练集里的正类样例进行"过采样",即增加一些正例使得正反例数目接近,然后再学习
- 直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,称为"阈值移动"
七、总结
首先,我觉得通过不断的写这种博客,一来能够强迫我自己每天都要去学习,对自己来说是一种监督,其次第二也让我对机器学习这本书的公式推导有一定的了解,虽然了解的还不够彻底,但是相比于之前还是有进步的,然后也学到了不少的latex的语法,说回正题,在本章学习中,由于之前期末考试月,前面存在着一些遗留的环节,因此对前面遗留的部分已经全部补回来了,所以这一章存在着一定的缺漏,但是我会在这两天全部看完再次更新我的笔记内容
针对这一章的学习,让我对线性模型有了一定的了解,有基本形式的,有高维形式的,还要对数几率线性模型就是我们口中一直提到的逻辑回归
这里附带上前两章节的连接
- 吃瓜教程第一章
- 吃瓜教程第二章